drools多一点
来源:互联网 发布:java面试时的自我介绍 编辑:程序博客网 时间:2024/05/24 06:57
An introduce to ruleEngine with the analyze of Drools
规则引擎(RuleEngine)是一个有限状态机,通过入参实现状态转移,在Java中定义为JSR94规范。规则引擎目前的开源实现主要是JBoss家族的Drools,采用友好的Apache协议(意味着可以作为商业产品)。以及据说非常贵的ILOG引擎,还有一些国内引擎。
1. 规则引擎的简介
规则引擎一般用于处理请求报文总类繁多,业务控制复杂的场景,比如某个订单入口,某个网络的控制域,某个路由,比如
- 决策业务(Decisiontable),比如XX可以打折,XX可以立减多少,多少利率,风控等
- 关联推荐,比如XX符合大数据,给TA推荐一些产品广告
- 邮件分类/智能短信,比如华为手机分析短信的“智能情景”业务
在进行大型项目设计时,结合StackOverflow的问答,有如下实践
- 规则引擎处理的业务大部分应该是无状态的。请求报文为结构体,一般可以用正则表达式去处理。
- 规则引擎也可以用于处理有状态的业务。而业务规格一般涉及到查表、查定时器等操作,需要与请求规格进行分层,不要滥用Then,更不要阻塞主线程。
- 通过外部DSL(比如Regex, XML, Groovy/JRuby/Kotlin)实现高扩展性,降低新需求的硬编码(详见之前写的DSL编程技术的介绍)
- 不要过于高估RETE算法而把所有的非关联业务扔到一个引擎中进行for循环,而要及时设计出子规格目录(也就是人为设计一个Category)
2. 把Drools批判一番
2.1. Drools源码中如何生成rule与when?
首先下载Drools,然后配置MVN代理(我这里用的是Cow,折腾了好久),运行mvn package下载依赖并编译后,然后使用Idea导入example,断点分析即可。本文使用的版本是Drools7
Drools使用了自己的drl语法,是一种DSL,通过ASM实现了它自己的Parser(ConsequenceGenerator),在启动时将读取META-INF/kmodule.xml中的配置,并将drl反序列化为RuleImpl与JVM字节码。
DRL文件
rule BrokenWing @Defeasible @Defeats( "AllBirdsFly" ) when // Drools设计的DSL b : Bird( ) Broken( part == "wing", bird == b )then // Java代码与Drools的内置函数 insertLogical( new Fly( b ), "neg" );end
生成的ByteCode(通过IDEA的断点Eval调用ClassGenerator.generateBytecode()与配置-Ddrools.dump.dir= ./)实现)
生成的Rule是这样的,虽然通过ASM生成了代码,但是IDEA目前无法调试此断点
public class Rule_BrokenWing185864016DefaultConsequenceInvokerGenerated implements Consequence, CompiledInvoker { private static final long serialVersionUID = 510L; public Rule_BrokenWing185864016DefaultConsequenceInvokerGenerated() { } public int hashCode() { return -505782175; } public List getMethodBytecode() { //详见下面的Class return RuleImpl.getMethodBytecode(this.getClass(), "Rule_BrokenWing185864016", "org.drools.examples.birdsfly", "defaultConsequence", "org/drools/examples/birdsfly/Rule_BrokenWing185864016.class"); } public boolean equals(Object var1) { return var1 != null && var1 instanceof CompiledInvoker?MethodComparator.compareBytecode(this.getMethodBytecode(), ((CompiledInvoker)var1).getMethodBytecode()):false; } public String getName() { return "Rule_BrokenWing185864016DefaultConsequenceInvokerGenerated"; } // 从getTuple中获取输入并执行`then` public void evaluate(KnowledgeHelper var1, WorkingMemory var2) throws Exception { LeftTuple var3 = (LeftTuple)var1.getTuple(); Declaration[] var4 = ((RuleTerminalNode)var1.getMatch().getTuple().getTupleSink()).getRequiredDeclarations(); Tuple var8 = var3.getParent(); InternalFactHandle var6 = var8.getOriginalFactHandle(); Bird var7 = (Bird)var6.getObject(); Rule_BrokenWing185864016.defaultConsequence(var1, var7, var6); }}
生成的then是这样的
public class Rule_BrokenWing185864016 { private static final long serialVersionUID = 510l; public static void defaultConsequence(KnowledgeHelper drools, Bird b, FactHandle b__Handle__ ) throws Exception { RuleContext kcontext = drools; drools.insertLogical( new Fly( b ), "neg" ); }}
这种可读性非常差的DSL注定了Drool只是一个半成品,你只要用过了,你就马上明白
- DRL语法奇特,过于接近AST,不亚于又学了一门新语言
- 生成代码过程是黑盒,而且代码中不能打断点
这两个缺点注定了Drools只是少数人的玩具,无法普及。
2.2. RETE算法与WorkingMemory
我们接着讲Drools的优点。它使用了 RETE算法,RETE是net的拉丁文,可以翻译为【网络算法】,英文好的可以参考这里,中文可以参考这里。它可以将多个“规则”编译生成一个AST,其中重复的条件编译到树的前面,不相同的校验编译到后面,实现最后For循环的叶子最少。
举个官网上的例子,定义了如下的规则
rule when Cheese( $chedddar : name == "cheddar" ) $person : Person( favouriteCheese == $cheddar ) then println( $person.getName() + " likes cheddar" );endrule when Cheese( $chedddar : name == "cheddar" ) $person : Person( favouriteCheese != $cheddar ) then println( $person.getName() + " does not like cheddar" );end
RETE通过算法,将重复的条件放到最前面,最后生成如下的树
- 红色为
AlphaNode表示字面意义上的对比,类似Java8中的Predicate<T> - 黄色为
LeftInputNodeAdapter, 表示节点的一对多转换,类似于flatmap<Predicate>操作 - 绿色为
JoinNode,类似Java8中的Predicate<T>.and()操作

RETE具体RETE算法需要对RuleImpl进行FindUsage与断点分析,就分析到这里了。
2. 3. Drools的优与劣
Drools成也RETE算法,败也RETE算法。
- Drools完美实现了RETE算法,如果用的好应该是循环次数最少的规则引擎。
- Drools设计的DSL受限于RETE算法中需要合并条件的约束,Rule扩展性太弱,无法承载复杂业务。
3. 更好的规则引擎
某厂为运营商提供后台系统,运营商的套餐有多复杂大家都知道。
- 如何处理众多套餐的业务识别呢?
- 如果防止大规模规则名称冲突?
- 如何让运营商通过网页点点点就可以定制与配置业务呢?
如果你希望了解,欢迎私信或者邮件,走社招(深圳南京)内部推荐流程,成为人人羡慕的“外来的和尚”,我也能分点推荐奖。
4. SUM
- 需求决定架构,有可能客户/业务也不明白自己要什么,规则引擎从最开始的if-else到正则表达式,再到最后的Drools,经过很多次迭代才完善软件,因此要计算时间投入收益比,没必要强行用
drl实现无码化,从网上的中文资料数量可以看出国内精通Drools的人也不是很多。硬编码/正则表达式也是一种方法。 - 如果真的想用于复杂业务,可以进行二次定制支持更加通用的JVM脚本,比如在for循环中调用ScriptEngine进行可配置动态化的规则(比如JS+JMX热部署)。
作者:BlackSwift
链接:http://www.jianshu.com/p/a9a4e2ebba3c
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。http://www.jianshu.com/p/a9a4e2ebba3c
1.drools是什么
Drools是为Java量身定制的基于Charles Forgy的RETE算法的规则引擎的实现。具有了OO接口的RETE,使得商业规则有了更自然的表达。
Rule是什么呢?
一条规则是对商业知识的编码。一条规则有 attributes ,一个 Left Hand Side ( LHS )和一个 Right Hand Side ( RHS )。Drools 允许下列几种 attributes : salience , agenda-group , no-loop , auto-focus , duration , activation-group 。
规则的 LHS 由一个或多个条件( Conditions )组成。当所有的条件( Conditions )都满足并为真时, RHS 将被执行。 RHS 被称为结果( Consequence )。 LHS 和 RHS 类似于
if(<LHS>){
<RHS>
}
下面介绍几个术语:
对新的数据和被修改的数据进行规则的匹配称为模式匹配( Pattern Matching )。进行匹配的引擎称为推理机( Inference Engine )。被访问的规则称为 ProductionMemory ,被推理机进行匹配的数据称为 WorkingMemory 。 Agenda 管理被匹配规则的执行。推理机所采用的模式匹配算法有下列几种: Linear , RETE , Treat , Leaps 。这里注意加红的地方,对数据的修改也会触发重新匹配,即对 WorkingMemory中的数据进行了修改。
然后规则引擎大概是这个样子的:

这个图也很好理解,就是推理机拿到数据和规则后,进行匹配,然后把匹配的规则和数据传递给Agenda。
规则引擎实现了数据同逻辑的完全解耦。规则并不能被直接调用,因为它们不是方法或函数,规则的激发是对 WorkingMemory 中数据变化的响应。结果( Consequence ,即 RHS )作为 LHS events 完全匹配的 Listener 。
数据被 assert 进 WorkingMemory 后,和 RuleBase 中的 rule 进行匹配(确切的说应该是 rule 的 LHS ),如果匹配成功这条 rule 连同和它匹配的数据(此时就叫做 Activation )一起被放入 Agenda ,等待 Agenda 来负责安排激发 Activation (其实就是执行 rule 的 RHS ),上图中的菱形部分就是在 Agenda 中来执行的, Agenda 就会根据冲突解决策略来安排 Activation 的执行顺序。
下面附上drools规则引擎的执行过程

2.rete算法
参考链接:Rete Algorithm
rete在拉丁文里是net network的意思,这个算法由 Charles Forgy 博士在他的博士论文里提到。
这个算法可以分为两个部分,一个是如何编译规则,一个是如何执行。原话(The Rete algorithm can be broken into 2 parts: rule compilation and runtime execution.)
rule compilation 就是如何通过对所有规则进行处理,生成一个有效的辨别网络。而一个辨别网络,则对数据进行过滤,使数据一步步往下传送。数据刚进入网络,有很多的匹配条件,这里可以理解为:逻辑表达式为true or false,然后在网络里往下传递的时候,匹配的条件越来越少,最后到达一个终止节点。
在这个论文里Dr Charles描述了这么几个节点,Node:
2.rete算法
参考链接:Rete Algorithm
rete在拉丁文里是net network的意思,这个算法由 Charles Forgy 博士在他的博士论文里提到。
这个算法可以分为两个部分,一个是如何编译规则,一个是如何执行。原话(The Rete algorithm can be broken into 2 parts: rule compilation and runtime execution.)
rule compilation 就是如何通过对所有规则进行处理,生成一个有效的辨别网络。而一个辨别网络,则对数据进行过滤,使数据一步步往下传送。数据刚进入网络,有很多的匹配条件,这里可以理解为:逻辑表达式为true or false,然后在网络里往下传递的时候,匹配的条件越来越少,最后到达一个终止节点。
在这个论文里Dr Charles描述了这么几个节点,Node:
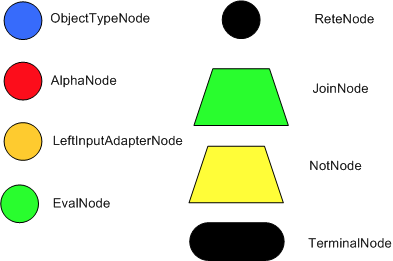
这里对其中的几个节点做一下简单介绍,另外说一下如何运作的。
- 首先,root node是所有的对象都可以进入的节点,也是辨别网络的一个入口,这个可以理解为一个虚节点,其实可能并不存在。
- 然后立马进入到ObjectTypeNode节点,这是一个对象类型节点。很明显,这里承载的是一个对象,可以理解为是java中的某个new Object(),在这个算法里,这个节点的作用就是为了保证不做一些无用功,什么无用功呢,就是不是对每个规则,进入的对象都要去辨别一遍,而是确定的对象类型,去做跟他相关的辨别,其实就是match。那么怎么做到呢?这里用到了一个hashMap,每次进入网络的对象,都会在这个map中通过hash,找到一个对应的辨别路径去辨别,即match。附上英文原文:(
Drools extends Rete by optimizing the propagation from ObjectTypeNode to AlphaNode using hashing. Each time an AlphaNode is added to an ObjectTypeNode it adds the literal value as a key to the HashMap with the AlphaNode as the value. When a new instance enters the ObjectType node, rather than propagating to each AlphaNode, it can instead retrieve the correct AlphaNode from the HashMap,thereby avoiding unnecessary literal checks.)
一个图来说明:

所有经过ObjectTypeNode的对象都会走到下一个节点,下一个节点可以是下面的几种:AlphaNodes, LeftInputAdapterNodes and BetaNodes。后面两个节点是AlphaNodes节点的一些变种,AlphaNodes节点是用来判断一些条件的。可以理解为一些逻辑表达式的计算。
下面开始上图:

- 这个图就是传递进一个Cheese对象,然后依次判断是否满足条件:1.判断name是否是“cheddar”,2.如果判断1通过了,继续判断strength是否是strong。这是最简单了一种情况了,这里附上对应的规则描述,后面会继续讲解:
rule "cheessRule" when
$cheese:Cheese(name == "cheddar" && strength == "strong")
then
......
end
3.maven依赖
这里列了一些后面的一些例子需要用到的maven依赖
<!--kie api 构建kie虚拟文件系统,关联decisiontable和drl文件,很关键 -->
<dependency> <groupId>org.kie</groupId> <artifactId>kie-api</artifactId></dependency><!-- 规则引擎核心包,里面包含了RETE引擎和LEAPS 引擎--><dependency> <groupId>org.drools</groupId> <artifactId>drools-core</artifactId></dependency><dependency> <groupId>org.drools</groupId> <artifactId>drools-compiler</artifactId></dependency><!-- 决策表依赖--><dependency> <groupId>org.drools</groupId> <artifactId>drools-decisiontables</artifactId></dependency><dependency> <groupId>org.drools</groupId> <artifactId>drools-templates</artifactId></dependency>
4.规则文件:.drl or xls
我们一般用到的也就这两种形式,一个是drl文件,是drools规则引擎提供的最原生的方式,语法很简单,具体语法见drools语法介绍
还有一个是决策表,决策表可以是xls也可以是csv,我们一般用xls比较多。而且好理解。xls就是一个excel文件。ps:在使用的过程中,遇到很多坑,其中一个最大的坑是mac系统的问题,这里后面会安利。
drl文件
首先来看下drl文件,这个在第2条讲解node的时候已经提到过了。
举例:
package com.sankuai.meituan.maxtse.drools.testimport com.sankuai.meituan.maxtse.drools.po.Studentrule "ageUp12" when $student: Student(age > 2) then $student.ageUp12(); endrule "nameMax" when $student: Student(name == "max") then $student.nameMax(); retract($student); end
简单说明:以第一个rule为例
- package 定义了规则文件的一个命名空间,和java中的package无关。
- import 这里可以有多个,就是在规则文件里引用到的java类。
- rule 用来定义一个规则,这里名字不可重复,后面跟一个when关键字,翻译过来就是,规则 名ageUp12,当满足......
- when 和then之间是逻辑表达式,也就是辨别条件,其中$student:Student(age >2)这里其实包含了两个意思,一个是满足age>2的Student对象,一个是把这个对象赋值给$student变量,这样后面就可以引用这个变量了。逻辑表达式写在小括号里,如果是多个条件,可以用逗号分隔,如$sutdent :Student(age > 2,name=="max")
- then和end之间来定义action,即当满足age>2的时候,做什么操作,这里可以像在java方法里一样,调用任何一个java类的方法,只要import了这个类且在前面定义了这个变量
第二个例子可以看到有个retract($student),这里是用到了drools内部提供的一个函数,具体见后续关于drools语法介绍的博客
决策表(decisiontable)
决策表就是一个excel文件,可以是xls(xlsx暂不支持)或者csv是个表格,看上去也很直观,即便是不懂代码的人看了也能看懂,不像drl文件那么多语法。关键的一点是:decisiontable也是最终转成drl文件来让drools规则引擎来解析执行的。*.xls到*.drl的转换这个在后面的wiki会说到。
直接上图吧

这里可以暂时忽略那些背景色,只是为了好区分没个模块的作用
这里忽略文件开始的空行,从有数据的第一行开始解释说明:
第一行,第一列:RuleSet 第二列com.sankuai.meituan.maxtse.drools.test。这里RuleSet可以省略的,累似drl文件中的package
第二行,第一列:Import 第二列具体的java类,这里和drl文件里的Improt相对应,多个引用类用逗号分隔
第三行,是个对这个决策表的说明
第四行,第一列:RuleTable FirstDecisionTable 这一行很关键 指明这是一个决策表,并且下面的几行都是具体的规则,就好比上面几行是一些准备条件,下面才是真正干活的地方,这里来个说明
第五行,CONDITION行,这一行可以有两种列名:CONDITION ACTION。CONDITION列就是drl里的辨别条件, ACTION则是具体的操作,即满足前面几列的CONDITION的条件后,会执行什么操作,这里CONDITION一定在ACTION前面,ACTION可以有多个列, 单个ACTION里的多个操作用逗号分隔,末尾要加分号结尾这里很重要,不然会有解析错误
第六行,紧挨着CONDITION的一行,可以在这里声明下面要用的到对象,对应drl文件里的$student:Student()
第七行,是辨别条件逻辑表达式,如:student.getAge()==$param则对应drl里的age==12这里$param是对应列每个单元格的值,然后这里需要特别说明下,针对于非字符串,如整数,小数等,可以直接使用$param,但是如果单元格里是字符串,则需要加双引号。(ps:mac里的双引号是斜的,一定要保证是竖着"的)另外,如果有多个值,可以用逗号隔开,然后可以用$1,$2提取变量值,如第一个ACTION里的student.doAction1($1,"$2")
第八行仍然是注释行,可以添加每一个CONDITON ACTION列的说明。
下面的每一行就是对应的某些条件的取值了。
参考:decisionTable
http://www.cnblogs.com/yuebintse/p/5767996.html
- drools多一点
- Drools
- drools
- drools
- drools
- Drools
- drools
- Drools
- drools学习的一点理解,简单记录下
- 多一点
- drools下载
- drools总结
- drools介绍
- Drools Expert
- drools sample
- drools介绍
- Drools使用
- thrift Drools
- XListView-View页面Copy的代码
- Hibernate入门到精通-关系映射一对多
- phaser教程一
- 用户添加,删除
- 轮播
- drools多一点
- 【分享】请回答1988(二)
- mysql 学习笔记 ----(1)数据库表的创建
- 人工智能学习路线
- selenium简单用法
- Hibernate入门到精通-关系映射多对一
- 注册页面
- 数据库的简单使用Sqllite
- RadioGroup+Fragment替换+侧滑菜单


