面经总结
来源:互联网 发布:网络与信息安全事件 编辑:程序博客网 时间:2024/05/16 05:21
一、操作系统
1. 介绍一下信号量和互斥锁
信号量是非负数,只有两个操作wait,signal
互斥量是0,1,只能用于一个资源的互斥访问
互斥量用于线程的互斥,信号线用于线程的同步。
有人做过如下类比:
Mutex是一把钥匙,一个人拿了就可进入一个房间,出来的时候把钥匙交给队列的第一个,一般的用法是用于串行化对临界区代码的访问,保证这段代码不会被并行的运行。
Semaphore是一件可以容纳N人的房间,如果人不满就可以进去,如果人满了,就要等待有人出来。
2. 介绍一下死锁
是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
死锁的发生必须具备以下四个必要条件:
1)互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
2)请求和保持条件:指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
3)不剥夺条件:指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
4)环路等待条件:指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源。
3. 线程的五大状态
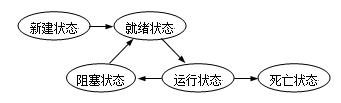
- 新建状态(New): 当用new操作符创建一个线程时, 例如new Thread(r),线程还没有开始运行,此时线程处在新建状态。
- 就绪状态(Runnable): 一个新创建的线程并不自动开始运行,要执行线程,必须调用线程的start()方法。当线程对象调用start()方法即启动了线程,start()方法创建线程运行的系统资源,并调度线程运行run()方法。当start()方法返回后,线程就处于就绪状态。处于就绪状态的线程并不一定立即运行run()方法,线程还必须同其他线程竞争CPU时间,只有获得CPU时间才可以运行线程。
- 运行状态(Running):当线程获得CPU时间后,它才进入运行状态,真正开始执行run()方法.
- 阻塞状态(Blocked):所谓阻塞状态是正在运行的线程没有运行结束,暂时让出CPU,这时其他处于就绪状态的线程就可以获得CPU时间,进入运行状态。
- 死亡状态(Dead)有两个原因会导致线程死亡:
1) run方法正常退出而自然死亡,
2) 一个未捕获的异常终止了run方法而使线程猝死。
为了确定线程在当前是否存活着(就是要么是可运行的,要么是被阻塞了),需要使用isAlive方法。如果是可运行或被阻塞,这个方法返回true; 如果线程仍旧是new状态且不是可运行的, 或者线程死亡了,则返回false.
4. 进程和线程有什么区别?什么时候用多进程好,什么时候用多线程好?
进程是资源分配的基本单位、线程是CPU调度的基本单位。在操作系统中,每个进程拥有独立的地址空间,而线程之间没有单独分配的地址空间。
1)需要频繁创建销毁的优先用线程,如web服务器,每一个请求开一个线程
2)需要进行大量计算的优先使用线程,最常见的是图像处理、算法处理。
3)强相关的处理用线程,弱相关的处理用进程
4)可能要扩展到多机分布的用进程,多核分布的用线程
5. 进程间怎么通信?
- 管道:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- 消息队列: 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 信号量: 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 共享内存使多个进程可以访问同一块内存空间,是最快的IPC形式,是针对其他通信方式运行效率低而设计的,往往与其他进程结合使用,如与信号量结合,来达到进程间的同步与互斥。传递文件最好用共享内存的方式。
二、计算机网络
1.tcp的三次握手,四次挥手
三次握手过程:
第一次:A给B发送一个数据包,其中syn=1,ack=0,seq=1234(随机),A进入SYN_SENT状态。
第二次:B给A发送一个数据包,其中syn=1,ack=1,ack number=1235(第一个数据包的seq+1,表示确认了),seq=5678(随机),B进入SYN_RCVD状态。
第三次:A给B发送一个数据包,其中ack=1,ack number=5679(表示B给我的请求已经确认),这时同时进入ESTABLISHED状态。
为啥不能是两次或四次呢?
因为至少3次通信才能保证两方的发信和收信功能都是正确的。
第一次:A方发送功能正常(因为发出去了)
第二次:B方接收功能正常(因为看到了A的请求)、B方发送功能也正常(因为发出去了)
第三次:A方接收功能正常(因为看到了B的请求)
知乎上看到一个段子形象的描述了三次握手:
三次握手:
A:“喂,你听得到吗?”
B:“我听得到呀,你听得到我吗?”
A:“我能听到你,今天balabala……”
两次握手:(注意此时A听不到B说话!!)
A:“喂,你听得到吗?”
B:“我听得到呀”
A:“喂喂,你听得到吗?”
B:“草,我听得到呀!!!!”
A:“你TM能不能听到我讲话啊!!喂!”
“……”
四次握手:
A:“喂,你听得到吗?”
B:“我听得到呀,你听得到我吗?”
A:“我能听到你,你能听到我吗?”
B:“……不想跟傻逼说话”
作者:匿名用户
链接:https://www.zhihu.com/question/24853633/answer/114872771
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
四次挥手过程:
第一次:A给B发送一个fin,进入FIN_WAIT_1状态,序号为1234(随机)。
第二次:B收到了A的fin,发送ACK,序号为1235,进入CLOSE_WAIT状态。
第三次:B再发送一个fin,进入LAST_ACK状态,序号为5678(随机)。(表示B不再接收A的数据,只接收最后一个ACK,但还会发数据)
第四次:A收到了fin后,发送一个ACK给B,序号为5679,B收到后进入CLOSED状态。(表示A不再接收B的数据,但还会发)

为啥是四次呢?
这个答案比较简单了,因为保证双向通信的关闭。即A->B和B->A都要关闭,每次都要双方确认。
2. HTTP的get post put delete
GET请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,参数之间以&相连,如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0%E5%A5%BD。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如:%E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST把提交的数据则放置在是 HTTP包的请求体(request body) 中。
GET用于信息获取,而且应该是安全的和幂等的。 安全的 就是它不会修改服务器端数据,幂等的 就是它操作1次和操作n次得到结果是一样的。
POST表示可能修改变服务器上的资源的请求。
GET和POST还有一个重大区别,GET产生一个TCP数据包;POST产生两个TCP数据包。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
put相当于update,所以也是幂等的,但post就不是。delete是删除资源,也是幂等的。例如:
* delete http://www.bank.com/account/123456表示删除账号为123456的账户,执行几次都是一样的。
* put http://www.forum.com/articles/4231 表示增加一个ID为4231的帖子,同样执行几次都是一样的。
* POST http://www.forum.com/articles 表示增加一个帖子,若重复发送则得到的帖子的id不同,所以不满足幂等性。
* GET http://www.bank.com/account/123456 表示获得账户123456的数据,执行几次都是一样的。.
3. Time_wait等待超时了会怎样?
TIME_WAIT状态将持续2个MSL(Max Segment Lifetime,最大数据段生存期),在Windows下默认为4分钟,即240秒,然后就closed了。
4. cookie和session
(1)cookie是放在客户端的,如果用户删除了cookie记录,cookie就丢了,session是放在服务器的,服务器重启了session就丢失了。
(2)cookie不安全,因为是放在客户端的,所以可以得到存放在本地的cookie数据并进行欺骗;
(3)cookie性能好一些,因为它不占用服务器资源,而session需要放在服务器里,如果访问量很大,session很多,会降低服务器性能。
(4)cookie只能放字符串,如果存取Java对象会比较困难,而session啥都能放。
(5)从有效期上,cookie的有效期可以设为Integer.MAX_VALUE,session虽然理论上也可以,但是首先sessionID是存在cookie中的,cookie中的sessionID的maxage=-1(表示只在浏览器内存中存活),所以关闭浏览器后sessionID就会清空,而且服务器端的session也是有生存周期的,否则session太多了也会性能下降。
5. 浏览器输入了www.baidu.com之后有哪些过程?
(1)先查找对应IP地址:浏览器内部的dns缓存->os中的缓存->host文件
(2)若没有,则递归的询问DNS服务器:根服务器->com域服务器->baidu.com服务器->www.baidu.com的IP
(3)若还是没有,则访问失败,若找到了,则放入os缓存->浏览器内部缓存
(4)根据ip地址,向百度服务器建立连接(三次握手)
(5)连接成功了之后发送http请求,获取相应的文件,渲染页面、加载对应的js脚本等
(6)断开连接
6. http的请求与响应报文是什么样的

请求行由请求方法字段、URL字段和HTTP协议版本字段3个字段组成,它们用空格分隔。例如,GET /index.html HTTP/1.1。
请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔。请求头部通知服务器有关于客户端请求的信息,典型的请求头有:
* User-Agent:产生请求的浏览器类型。
* Accept:客户端可识别的内容类型列表。
* Host:请求的主机名,允许多个域名同处一个IP地址,即虚拟主机。
最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。
请求数据不在GET方法中使用,而是在POST中使用。
响应报文由三部分组成:状态行、首部行、实体。

见实例。
HTTP/1.1 200 OKDate: Sat, 31 Dec 2005 23:59:59 GMTContent-Type: text/html;charset=ISO-8859-1Content-Length: 122<html><head><title>Homepage</title></head><body><!-- body goes here --></body></html>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
三、java编程
(一) 考查Java源码
1. ArrayList
ArrayList继承了抽象类AbstractList,实现了List,RandomAccess,Cloneable,Serializable接口。
- RandomAccess标识其支持快速随机访问;
- Cloneable标识其支持对象复制;
- Serializable标识其可序列化;
然后介绍一下具体实现:
首先底层是用一个数组实现的,数组的长度默认为10,不过也可以在new 的时候指定。
那么说说增删改查吧~~
增嘛,就是add方法了,我们在lc里都非常熟悉。然后ArrayList的add源码是酱紫:
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true;}- 1
- 2
- 3
- 4
- 5
所以是先调用ensureCapacityInternal方法再往数组里面加东西。
那么ensureCapacityInternal方法又长什么样呢?
private void ensureCapacityInternal(int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } ensureExplicitCapacity(minCapacity);}- 1
- 2
- 3
- 4
- 5
- 6
- 7
首先判断数组是不是空的,若是,则确保数组容量至少为初始值和size+1的较大值,然后再进入ensureExplicitCapacity方法。
private void ensureExplicitCapacity(int minCapacity) { modCount++; // overflow-conscious code if (minCapacity - elementData.length > 0) grow(minCapacity);}- 1
- 2
- 3
- 4
- 5
- 6
- 7
modCount我们已经很熟悉了,记录修改次数的,防止在多线程环境下读写冲突,这里因为add操作调用了他,所以modCount++了。
然后就是关键了,如果minCapacity(传进来的是size+1)比数组长度小,那就装不下了,要grow。
grow方法如下:
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity);}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
恩我们看到了,在这里是首先把旧容量扩充到原来的1.5倍,然后讨论了两种情况:
* 扩充了还是不够:那么就扩大到minCapacity。
* 新容量比MAX_ARRAY_SIZE(这是个常量,为
然后把数组搬过去即可。
说完add再说与之对应的remove。
public E remove(int index) { rangeCheck(index); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work return oldValue;}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
首先检查一下index是不是不合法的,这里我觉得怪怪的。。。。。
讲道理来说,对一个数组的越界访问不管是偏大还是偏小都要抛出IndexOutOfBoundsException,但是在这段代码里面,如果index偏大,是在rangeCheck方法里面抛出的,而如果是偏小(例如传一个负数),则是在引用elementData[index]里面抛出的,不知道这样做的理由是什么。如果需要使用方法来约束数组范围,那么负值也要考虑的;如果在引用数组下标elementData[index]`时约束范围,那这个rangeCheck方法存在的意义又是什么?
源码中的解释是:It is always used immediately prior to an array access,which throws an ArrayIndexOutOfBoundsException if index is negative.哪位读者能解释一下?
如果下标是正确的,那么修改次数+1,然后取出旧值,把后面的往前搬一下,清空数组末尾的值(置空)。
然后Add还有这样的方法:
public void add(int index, E element) { rangeCheckForAdd(index); ensureCapacityInternal(size + 1); // Increments modCount!! System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++;}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
可是这里的rangeCheckForAdd又检测负值了。。。。。。。。。。。。。
改和查很简单,贴一下源码就可以了。
public E get(int index) { rangeCheck(index); return elementData(index);}public E set(int index, E element) { rangeCheck(index); E oldValue = elementData(index); elementData[index] = element; return oldValue;}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
indexOf和lastIndexOf也很简单,就是一个从头找, 一个从尾找。都是遍历操作。
2.LinkedList
LinkedList的底层实现是个双向链表,其中节点类描述如下:
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
然后对象中维护了头结点和尾节点,因此就可以得到任意一个节点了。
同理,我们还是从增删改查四个方面研究LinkedList:
先说add,二话不说上源码:
public boolean add(E e) { linkLast(e); return true;}void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++;}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
相当简单,学过数据结构里面链表相关章节的都很容易看明白。
然后上remove源码:
public boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false;}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这里就是讨论了一下节点内储存了null的特殊情况,然后关键部分在unlink方法:
E unlink(Node<E> x) { // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element;}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
同样也很简单,就是数据结构里面学过的双端链表的删除操作,需要注意的就是特殊情况,也就是要删除的节点在边上。
因为是双端链表实现的嘛,LinkedList比ArrayList多了addFirst,addLast,removeFirst,removeLast方法,内部实现都差不多也就不再赘述。
然后get和set,先上源码 :
public E get(int index) { checkElementIndex(index); return node(index).item;}public E set(int index, E element) { checkElementIndex(index); Node<E> x = node(index); E oldVal = x.item; x.item = element; return oldVal;}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这个也都比较简单,同样是先检查index是否越界再get或set。
最后他俩的区别就是我们在数据结构课上非常熟悉的,顺序存储和随机存储的优势啦~~ArrayList是随机存储的,所以get和set会快,而LinkedList是顺序存储的,所以add和remove快。
3.ThreadLocal
这东西比较简单,他是对一个类的封装,被ThreadLocal封装的变量每一个线程都有一个独立的副本,每一个线程都可以独立改变自己的副本而不影响别的线程。
在以前,底层实现是一个HashMap,key是当前线程,value是该实例。
但是现在的设计思路改了!!现在的底层实现是Thread个HashMap,每个HashMap的key是这个ThreadLocal实例,value是那个对象的副本。
为什么这样搞呢?如果是原来的设计方案,那么在大型项目里有很多Thread和很多ThreadLocal的前提下,就会有ThreadLocal个HashMap,每个里面就有Thread个元素。在Thread很多的情况下性能会低。
还有一点,当一个线程停止时,对应的ThreadLocal副本都不存在了,可以销毁一个HashMap。但用第一种设计思路的话这些HashMap都在。
4. sleep()和wait()
sleep是Thread类的静态方法。sleep的作用是让线程休眠制定的时间,在时间到达时恢复,也就是说sleep将在接到时间到达事件事恢复线程执行.
wait是Object的方法,也就是说可以对任意一个对象调用wait方法,调用wait方法将会将调用者的线程挂起,直到其他线程调用同一个对象的notify方法才会重新激活调用者,例如:
sleep和wait的区别有:
- 这两个方法来自不同的类分别是Thread和Object
- 最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
- wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用
synchronized(x){ x.notify() //或者wait() }- 1
- 2
- 3
- 4
- sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
5.finalize()方法
finalize()是Object的protected方法,有点像c++里面的析构函数,它是在对象被回收之前调用的。垃圾回收器准备释放内存的时候,会先调用finalize()。
但是和C++的析构函数不太一样的是,C++中的析构函数调用的时机是确定的(对象离开作用域或delete掉),但Java中的finalize的调用具有不确定性。
6. Integer 的缓存机制
在Java编译器中,把原始类型(8种)自动转换为封装类的过程,称为自动装箱,相当于valueOf方法。
例如:
Integer i=10;这行代码是等价于Integer i=Integer.valueOf(10);的。根据jdk源码,valueOf方法是先去一个叫IntegerCache类(是一个Integer数组cache[]的再封装)里面查找这个数是否被缓存了,如果有,直接拿出来,如果没有则new一个对象。
IntegerCache的缓存范围是从-128到high,这个high是通过JVM的启动参数指定的。
那么看两道题:
public class Hello { public static void main(String[] args) { int a = 1000, b = 1000; System.out.println(a == b); //true,因为是基本类型的比较 Integer c = 1000, d = 1000; System.out.println(c == d); //false,因为1000是没缓存的,系统调用了两次new,而对象类型比较的是地址,所以false Integer e = 100, f = 100; System.out.println(e == f); //true,100是缓存的,所以直接从cache里面拿的,是同一个地址 } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
public class Main { public static void main(String[] args){ int a=0; Integer b=0; Integer c=new Integer(0); Integer d=Integer.valueOf(0); System.out.println(a==b);//true,因为涉及到基本类型的比较,要解包 System.out.println(a==c); System.out.println(b==c);//b是缓存区里拿出来的,c是new出来的,所以false System.out.println(c==d);//d也是缓存区里拿出来的,所以b==d是true,c==d是false System.out.println(b==d); }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
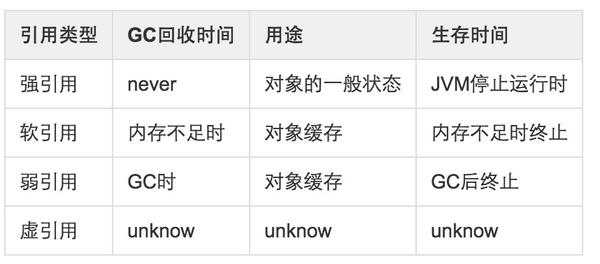
7.Java的四种引用
强引用:类似于Object ObjA = ObjB;这样的引用就叫强引用,系统中绝大多数都是这种引用,如果不在代码中切断ObjA和ObjB的联系(如写出ObjA=null;)当内存空间不足时就会抛出OutOfMemory异常。
软引用:内存不足的时候,如果这个对象只是软可达的,那么就清理掉他,如果内存空间足够,就不会清理。
弱引用:只要垃圾回收器发现了一个只具有弱引用的对象,那么不管内存空间够不够,都清理掉他。
虚引用:相当于没有引用,随时会被系统清理掉。
8.volatile关键字的理解
(1)防止指令重排序(指令重排序指的是cpu可以把指令不按逻辑顺序分配给各电路单元执行,以优化效率)
(2)实现线程可见性:每次修改volatile变量都强制将修改后的值刷新到主存,读取该变量值的时候需要重新从主内存中读取。
9. AtomicInteger
是Integer的线程安全版的封装,在Java中,i++不是线程安全的,高并发下统计会出现错误,而AtomicInteger的 getAndIncrement方法是线程安全的,保证原子操作。
10. synchronized和lock
(1) synchronized是底层的,由jvm层面实现,而Lock是使用代码实现的,如果不在finally块中显式释放lock.unlock(),就不会自动释放锁。
(2) synchronized是悲观锁,也就是说进入同步块之后其他线程必须等待线程释放锁,而ReentrantLock是乐观锁,他是通过CAS操作(compare and set,就是先比较内存中的值有没有被改变,再set)保证线程同步的。
(3) 并发程度低的时候synchronized好,并发程度高的时候lock好。
11.CAS如何实现,什么是ABA问题
CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
ABA问题:如果一个线程要把一个变量a的值从A改成B,那么它先去内存里看看内存值是不是A,但如果是A,也不能保证是线程安全的,例如这个a的值先从A改成了C,又从C改回了A,那么这个C有可能赋值给b,等等。会出现安全隐患。
如何解决:用版本戳version来标记,只有版本号相同才认为相同。
12.String,StringBuffer,StringBuilder
String是不可变类,因为jdk源码中声明了final。如果一个字符串经常需要被修改,则使用StringBuffer好一些。修改String其实是首先创建一个StringBuffer,再append来修改,再toString返回。而StringBuilder是StringBuffer的单线程版本,如果是单线程的,效率更高些。
因此如果是小数据操作,String最方便,如果是大量字符串修改操作,多线程使用StringBuffer,单线程使用StringBuilder。
13. 什么是NIO AIO BIO
首先来说Socket的流程:open->accept->read->send->close.
- BIO:同步阻塞IO,每个连接对应一个线程,要求Server对每个连接都开一个线程,其中若客户端不向服务器发起连接请求,accept方法就会一直阻塞。另外,socket中的read方法是阻塞的,要等到数据都准备好才发送,当连接比较多的时候会使得程序效率十分低下。

- NIO: NonBlocking IO,同步非阻塞IO。 这次不需要每个连接维护一个处理线程,而是每一个请求对应一个线程,如果没有数据则不需要工作线程来处理。
NIO技术主要由三部分组成,Channel,Buffers,Selector。
Channel: 我们对数据的读取和写入要通过Channel,它就像水管一样,是一个通道。通道不同于流的地方就是通道是双向的,可以用于读、写和同时读写操作。
Buffer: 是一个对象,包含一些要写入或者读出的数据。
Selector: Selector会不断轮询注册在其上的Channel,如果某个Channel上面发生读或者写事件,这个Channel就处于就绪状态,会被Selector轮询出来,然后通过SelectionKey可以获取就绪Channel的集合,进行后续的I/O操作。
- AIO: 异步非阻塞IO,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理,
14.Object类的方法?
1.clone方法
保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。
所谓浅拷贝,就是只复制对象,不把引用复制一份,而深拷贝是递归的把对象及其每一层的引用都复制过来。
2.getClass方法
final方法,获得运行时类型。
3.toString方法
该方法用得比较多,一般子类都有覆盖。
4.finalize方法
该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。
5.equals方法
该方法是非常重要的一个方法。一般equals和==是不一样的,但是在Object中两者是一样的。子类一般都要重写这个方法。
6.hashCode方法
该方法用于哈希查找,重写了equals方法一般都要重写hashCode方法。这个方法在一些具有哈希功能的Collection中用到。
一般必须满足obj1.equals(obj2)==true。可以推出obj1.hashCode()==obj2.hashCode(),但是hashCode相等不一定就满足equals。不过为了提高效率,应该尽量使上面两个条件接近等价
7.wait方法
wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
(1)其他线程调用了该对象的notify方法。
(2)其他线程调用了该对象的notifyAll方法。
(3)其他线程调用了interrupt中断该线程。
(4)时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。
8.notify方法
该方法唤醒在该对象上等待的某个线程。
9.notifyAll方法
该方法唤醒在该对象上等待的所有线程。
15. equals和==的区别:
==是比较两个对象是否为同一个引用,但equals是可以重写的,Object.class中默认的equals就是==。
16. 动态代理
主要用来做方法的增强,让你可以在不修改源码的情况下,增强一些方法,在方法执行前后做任何你想做的事情(甚至根本不去执行这个方法)
实例:现在有一个接口Subject,里面有一个方法f,现在我们需要在执行f之前和之后增加一些操作,而f是什么我们并不确定。有可能工程中有许多f的实现类,有可能f就是个给别人用的接口。那么怎么办呢?
我们就需要动态代理了,首先我们写一个类,叫做“调用处理器”,需要实现InvocationHandler方法,用来具体实现我们需要增强的具体内容。
接下来创建调用处理器对象,传入接口,并动态生成代理对象,通过代理对象来调用方法f,这时候就发现无论f的实现是怎么样的,都能够产生增强的效果。
public class Demo { public static void main(String[] args) { RealSubject realSubject = new RealSubject(); //1.创建委托对象 ProxyHandler handler = new ProxyHandler(realSubject); //2.创建调用处理器对象 Subject proxySubject = (Subject)Proxy.newProxyInstance(RealSubject.class.getClassLoader(),RealSubject.class.getInterfaces(), handler);//3.动态生成代理对象 proxySubject.f(); //4.通过代理对象调用方法 }}/** * 接口 */interface Subject{ void f();}/** * 委托类 */class RealSubject implements Subject{ public void f(){ System.out.println("执行了RealSubject的方法f"); }}/** * 代理类的调用处理器 */class ProxyHandler implements InvocationHandler{ private Subject subject; public ProxyHandler(Subject subject){ this.subject = subject; } @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { System.out.println("====before====");//定义预处理的工作,当然你也可以根据 method 的不同进行不同的预处理工作 Object result = method.invoke(subject, args); System.out.println("====after===="); return result; }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
输出如下:
====before====执行了RealSubject的方法f====after====- 1
- 2
- 3
17.继承Thread与实现Runnable的区别
因为Java不可以多继承却可以实现多个接口,所以继承Thread就不能继承别的了,而实现Runnable还可以实继承别的类。
实现Runnable可以使用同一个实例化对象开多个线程,实现线程间数据共享。而如果需要重写Thread底层的方法,那就必须继承Thread类了。
18. 什么叫乐观锁 什么叫悲观锁
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
(二)设计模式
1. 单例模式
单例模式有以下特点:
1. 单例类只能有一个实例。
2. 单例类必须自己创建自己的唯一实例。
3. 单例类必须给所有其他对象提供这一实例。
单例模式有两种,分别叫做饱汉式和饿汉式。(起名字的一定是个粗糙的大叔,叫萌萌的妹子不好么?)
饱汉式就是说,这个人有钱,资源很多,所以什么时候需要这个实例什么时候new,写法如下:
public class SingletonDemo{ private static SingletonDemo instance = null; private SingletonDemo(){ } public static SingletonDemo getInstance(){ if(instance==null){ instance = new SingletonDemo(); } return instance; }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
饿汉式就是说,这个人很没钱,怕饿死,所以在类加载的时候就new好,写法如下:
public class SingletonDemo{ private static SingletonDemo instance = new SingletonDemo(); private SingletonDemo(){ } public static SingletonDemo getInstance(){ return instance; }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
很显然,如果是大型项目,饱汉式的单例类很多的情况下,会导致系统的启动很慢。饿汉式的问题是在多线程下会出现线程不安全的情况。因为如果多个线程同时运行到if(instance==null)这句里面,就都进来了,这样就new了好多instance。
解决方法有3种:
方法一(利用同步方法):把饱汉式的public static Singleton getInstance()加上synchronized关键字,但这种的粒度太大了,在并发很高的情况下会导致性能降低。 我们只需要控制new 语句就可以了,因此请看方法二:
方法二(双重同步锁):
public static SingletonDemo getInstance(){ if(null == instance ) { synchronized(SingletonDemo.class){ if(null == instance) instance = new SingletonDemo(); } } return instance;} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
首先解释一下,为什么要判断两遍呢?进入同步块不是已经确保了instance==null么?别忘了这是并发环境啊~~~接下来是见证奇迹的时刻!!
假设去掉同步块里面的if语句啊。。。。设两个线程1和2,同时调用了getInstance()方法,由于instance==null成立,则线程1进入同步块,线程2等待,那么线程1退出同步块的时候线程2就进入了,可是此时instance已经new出来了,线程2又new 了一遍!!!
所以这两个if语句看起来逼格很高吧~~表示已经被帅到有没有~
但是,这种方法也有问题!!!!
问题出在哪里呢?这个希望能背下来,如果被问到了说不定可以hold住面试官哦~~
当然这种问题出现的前提是该单例类是很复杂的。假设线程A执行到了第2行,那么instance==null正确,进入同步块,然后他开始new这个实例,但是 这里假设new 的开销非常大!!! 我们都知道jvm加载一个类是先寻找二进制文件,创建Class对象,再生成引用,再赋值、执行构造方法等操作。
那么静态代码块非常复杂的时候,线程B也执行到了第二行的时候,已经生成了引用,那么instance 不为null,可是此时该实例还没初始化完全啊!!就return了!!对不对!!
那么有什么办法呢,由此提出了方法三~~
方法三:静态内部类
public class Singleton { private static class SingletonHolder { private static final Singleton INSTANCE = new Singleton(); } private Singleton (){} public static final Singleton getInstance() { return SingletonHolder.INSTANCE; }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这个用的是内部类,首先外部类被加载的时候内部类不立即加载,这样就做到了延迟加载,而JVM在初始内部类的时候已经实现了线程安全,而不需要关键字来限定。
2. 生产者消费者模式
就是一个很标准的同步问题,有一个有限大小的缓冲区,生产者线程每次往里放入资源,消费者线程每次从里面拿资源,该问题的关键是保证生产者不会在缓冲区满的时候加入数据,消费者不会在空的时候拿数据。
在Java中可以用阻塞队列来实现这个需求。因为阻塞队列的put方法在队列已满的时候是将线程阻塞的,take方法同理。
public class ConsumerThread implements Runnable { protected BlockingQueue<Object> queue; ConsumerThread(BlockingQueue<Object> theQueue) { this.queue = theQueue; } public void run() { try { while (true) { Object obj = queue.take(); System.out.println("消费了一个资源,现在队列大小是 " + queue.size()); take(obj); } } catch (InterruptedException e) { e.printStackTrace(); } } void take(Object obj) throws InterruptedException { Random r = new Random(); Thread.sleep(r.nextInt(1000)); // simulate time passing }}public class ProducerThread implements Runnable { protected BlockingQueue<Object> queue; ProducerThread(BlockingQueue<Object> theQueue) { this.queue = theQueue; } public void run() { try { while (true) { Object justProduced = getResource(); queue.put(justProduced); System.out.println("生产了一个资源,现在队列大小是 " + queue.size()); } } catch (InterruptedException e) { e.printStackTrace(); } } Object getResource() throws InterruptedException { Random r = new Random(); Thread.sleep(r.nextInt(1000)); // simulate time passing return new Object(); }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
那么BlockingQueue跟一般的queue区别就是,它的所有方法都加了ReetrantLock,并用了两个信号量notFull和notEmpty来控制边界值。put在拿到锁的时候,如果此时队列已满(count == items.length),就一直等待notFull信号激活,激活后将元素入队并激活notEmpty信号。take方法反之。
3. 访问者模式
就是一种将算法与对象结构分离的模式。
假设现在有一个复杂的结构,由多种对象组成。访问者模式的实现方式是在每个对象里注册一个accept方法,接受访问者接口,该接口拥有visit方法,分别对不同类型的结构做出不同的动作,在遍历该结构时,对每一个元素调用accept方法,在accept方法里调用访问者的visit方法,因此可以按不同逻辑处理该复杂对象的不同成分。且访问者是个接口,visit方法是可以根据不同需求实现的。
Wikipedia给出的访问者模式的例子如下
interface Visitor { void visit(Wheel wheel); void visit(Engine engine); void visit(Body body); void visit(Car car);}class Wheel { private String name; Wheel(String name) { this.name = name; } String getName() { return this.name; } void accept(Visitor visitor) { visitor.visit(this); }}class Engine { void accept(Visitor visitor) { visitor.visit(this); }}class Body { void accept(Visitor visitor) { visitor.visit(this); }}class Car { private Engine engine = new Engine(); private Body body = new Body(); private Wheel[] wheels = { new Wheel("front left"), new Wheel("front right"), new Wheel("back left") , new Wheel("back right") }; void accept(Visitor visitor) { visitor.visit(this); engine.accept(visitor); body.accept(visitor); for (int i = 0; i < wheels.length; ++ i) wheels[i].accept(visitor); }}class PrintVisitor implements Visitor { public void visit(Wheel wheel) { System.out.println("Visiting " + wheel.getName() + " wheel"); } public void visit(Engine engine) { System.out.println("Visiting engine"); } public void visit(Body body) { System.out.println("Visiting body"); } public void visit(Car car) { System.out.println("Visiting car"); }}public class VisitorDemo { static public void main(String[] args) { Car car = new Car(); Visitor visitor = new PrintVisitor(); car.accept(visitor); }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
我们访问一辆车的时候,需要先访问车的整体(Car),再访问引擎(Engine),再访问车身(Body),最后访问车轮(Wheel).而如何遍历这辆车则是由Visitor的实现类做到的,与车的构建部分无关。
在DTS中,控制流图结构由{VexNode,Edge}两种结构组成,在VexNode和Edge类中均注册了accept方法。因此遍历的时候需要实现两个visit方法,分别实现对点的遍历和对边的遍历。且我们对控制流图的操作有很多种,因此需要实现不同的控制流图Visitor。
(三)JVM的问题
1. JVM的内存模型
JVM的基本结构分为数据区、本地方法接口、执行引擎、类加载器。

数据区是最重要的一部分,分为如下几部分:

(1)虚拟机栈VM Stack: 它主要用来存储线程执行过程中的局部变量,方法的返回值,以及方法调用上下文。每一次函数调用都对应一个栈帧(stack frame),用于存储当次函数调用的局部变量、返回值等信息。栈区不够用了会抛出StackOverflowError,一般由于函数调用层数太高(如死递归)导致。每一个线程对应一个栈区。
(2)堆区Heap:它是所有线程共享的,用来保存各种对象。如数组,实例等等,然后根据存在时间还可以分为新生代和老生代。
(3)方法区Method:也是所有线程共享的,用于存储已被加载的类信息、常量、静态变量等信息。这里面还有个运行时常量池Runtime Constant Pool,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。(How to understand?)
(4)程序计数器PC Register:这块内存空间比较小,作用就是存储当前线程所执行的代码行号。是线程独立的。
(5) 本地方法栈Native Method Stack:类似于VM Stack,但是这里是为Native方法服务,也是线程独立的。
执行引擎:负责执行class文件中包含的字节码指令.
本地方法接口:主要是调用C或C++实现的本地方法及返回结果。
类加载器:在JVM启动时或者在类运行时将需要的class加载到JVM中。
2. GC
GC主要有两大块内容,一是垃圾检测,二是垃圾回收。所谓垃圾检测,就是系统判断什么内存空间是垃圾,一般有两种方法:
* 引用计数法:对每个对象增加一个计数器,该对象被引用了就+1,没被引用就-1. 可是这样有一个很严重的问题,例如有两个对象ObjA和ObjB,他们之间是互相耦合的,但是没有其他对象引用他们。事实上他们已经是垃圾了,可是引用计数不为0,就不能回收。
* 可达性分析算法:以根对象GC Root为起点进行搜索,如果有对象是不可达的,就是垃圾。GC Root集包括栈区中引用的、常量池中引用的、静态区引用的对象等等。
垃圾检测说完了,那么说说是怎么回收的,如果判定一个对象从Gc Root是不可达的,系统就会回收这些对象。那么如何回收呢,下面由浅入深介绍几种策略:
(1)标记-清除(Mark-sweep):
若一个对象是垃圾,则标记起来,然后统一回收。但是这样会产生大量碎片,如果再new一个很大的对象还要触发内存整理。
(2)复制(Copying):
把内存分为两部分,每次使用其中一个区域。当这一块的内存需要清理了,则复制到另一个区域中。这样就不产生碎片,但是有一半内存空间浪费了。
(3) 标记-整理(Mark-Compact):
标记的过程同策略1,但是清除垃圾对象的同时,把不是垃圾的对象“压缩”到一起,这样也解决了碎片,且不浪费一半空间。
分代gc:
为什么要分代回收?-
因为在实际工程中,不同对象的生命周期不一样,例如socket连接、线程等对象是要从工程启动开始就始终持续的,而如String List等对象往往使用一次就成为垃圾了。因此需要将对象按生命周期划分,不同周期使用不同策略。
如何按周期划分?
将对象按其生命周期的不同划分成:年轻代(Young Generation)、年老代(Old Generation)、持久代(Permanent Generation)。
然后Young又细分为Eden,From Survivor,To Survivor三部分,一个新对象优先是放在Eden区的,所有新生成的对象首先都是放在年轻代的。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。年轻代分三个区。一个Eden区,两个Survivor区(一般而言)。大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor也满了的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制“年老区(Tenured)”。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来 对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor去过来的对象。而且,Survivor区总有一个是空的。同时,根据程序需要,Survivor区是可以配置为多个的(多于两个),这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能。
如果增加到一定年龄(默认为15岁),则进入Old Generation.
如下图所示。(图转侵删。)

由图可知,两个Survivor区是对称的,没有先后之分。
那么老年代满了怎么办?那就触发一次Full GC,回收整个堆内存。
由上面介绍可知,年轻代的gc用到了复制算法, 老年代的gc用到的是标记-整理算法。
垃圾回收器
垃圾回收器是内存回收的具体实现。《深入理解jvm》一书中以hotspot JVM为例,介绍了7种收集器。

Serial(串行GC)收集器
Serial收集器是一个新生代收集器,单线程执行,使用复制算法。它在进行垃圾收集时,必须暂停其他所有的工作线程(用户线程)。是Jvm client模式下默认的新生代收集器。对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高的单线程收集效率。
ParNew(并行GC)收集器
ParNew收集器其实就是serial收集器的多线程版本,除了使用多条线程进行垃圾收集之外,其余行为与Serial收集器一样。
Parallel Scavenge(并行回收GC)收集器
Parallel Scavenge收集器也是一个新生代收集器,它也是使用复制算法的收集器,又是并行多线程收集器。parallel Scavenge收集器的特点是它的关注点与其他收集器不同,CMS等收集器的关注点是尽可能地缩短垃圾收集时用户线程的停顿时间,而parallel Scavenge收集器的目标则是达到一个可控制的吞吐量。吞吐量= 程序运行时间/(程序运行时间 + 垃圾收集时间),虚拟机总共运行了100分钟。其中垃圾收集花掉1分钟,那吞吐量就是99%。
Serial Old(串行GC)收集器
Serial Old是Serial收集器的老年代版本,它同样使用一个单线程执行收集,使用“标记-整理”算法。主要使用在Client模式下的虚拟机。
Parallel Old(并行GC)收集器
Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。
CMS(并发GC)收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。CMS收集器是基于“标记-清除”算法实现的,整个收集过程大致分为4个步骤:
①.初始标记(CMS initial mark)
②.并发标记(CMS concurrenr mark)
③.重新标记(CMS remark)
④.并发清除(CMS concurrent sweep)
其中初始标记、重新标记这两个步骤任然需要停顿其他用户线程。初始标记仅仅只是标记出GC ROOTS能直接关联到的对象,速度很快,并发标记阶段是进行GC ROOTS 根搜索算法阶段,会判定对象是否存活。而重新标记阶段则是为了修正并发标记期间,因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间会被初始标记阶段稍长,但比并发标记阶段要短。
由于整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,所以整体来说,CMS收集器的内存回收过程是与用户线程一起并发执行的。
CMS收集器的优点:并发收集、低停顿,但是CMS还远远达不到完美,主要有三个显著缺点:
* CMS收集器对CPU资源非常敏感。在并发阶段,虽然不会导致用户线程停顿,但是会占用CPU资源而导致引用程序变慢,总吞吐量下降。CMS默认启动的回收线程数是:(CPU数量+3) / 4。
* CMS收集器无法处理浮动垃圾,可能出现“Concurrent Mode Failure“,失败后而导致另一次Full GC的产生。由于CMS并发清理阶段用户线程还在运行,伴随程序的运行自热会有新的垃圾不断产生,这一部分垃圾出现在标记过程之后,CMS无法在本次收集中处理它们,只好留待下一次GC时将其清理掉。这一部分垃圾称为“浮动垃圾”。也是由于在垃圾收集阶段用户线程还需要运行,即需要预留足够的内存空间给用户线程使用,因此CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分内存空间提供并发收集时的程序运作使用。在默认设置下,CMS收集器在老年代使用了68%的空间时就会被激活,也可以通过参数-XX:CMSInitiatingOccupancyFraction的值来提供触发百分比,以降低内存回收次数提高性能。要是CMS运行期间预留的内存无法满足程序其他线程需要,就会出现“Concurrent Mode Failure”失败,这时候虚拟机将启动后备预案:临时启用Serial Old收集器来重新进行老年代的垃圾收集,这样停顿时间就很长了。所以说参数-XX:CMSInitiatingOccupancyFraction设置的过高将会很容易导致“Concurrent Mode Failure”失败,性能反而降低。
* 最后一个缺点,CMS是基于“标记-清除”算法实现的收集器,使用“标记-清除”算法收集后,会产生大量碎片。空间碎片太多时,将会给对象分配带来很多麻烦,比如说大对象,内存空间找不到连续的空间来分配不得不提前触发一次Full GC。为了解决这个问题,CMS收集器提供了一个-XX:UseCMSCompactAtFullCollection开关参数,用于在Full GC之后增加一个碎片整理过程,还可通过-XX:CMSFullGCBeforeCompaction参数设置执行多少次不压缩的Full GC之后,跟着来一次碎片整理过程。
G1收集器
G1(Garbage First)收集器是JDK1.7提供的一个新收集器,G1收集器基于“标记-整理”算法实现,也就是说不会产生内存碎片。还有一个特点之前的收集器进行收集的范围都是整个新生代或老年代,而G1将整个Java堆(包括新生代,老年代)。
3. JVM的内存开太大了会怎么样?
若堆大小超过32G,则jvm进入64位引用,每个对象的引用将从4字节变成8字节,所以若堆区大小在32G-38G之间的话,相当于减小了可用堆的大小。因此若实际开发中,尽量把堆控制在32G以内,如果32G实在是不够用了,应直接加到38G以上。
4. 类加载
4.1 类加载过程?
一个类的生命周期如下:

加载->连接(验证-准备-解析)->初始化->使用->卸载。
其中加载过程最为重要,分为以下三个过程:
* 通过 类全名 获得对应的二进制字节流;
* 将字节流中的信息(类名、静态信息、常量)存入方法区
* 在堆区生成java.lang.Class对象
4.2 双亲委派模型
首先,两个类是相同的充要条件是,这个类本身相同且类加载器相同。那么系统需要加载一个类的时候,如何找该哪个加载器来加载呢?
首先系统内置的加载器之间的关系如下:

(1).BootStrap ClassLoader:启动类加载器,负责加载存放在%JAVA_HOME%\lib目录中的,或者通被-Xbootclasspath参数所指定的路径中的,并且被java虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库,即使放在指定路径中也不会被加载)类库到虚拟机的内存中,启动类加载器无法被java程序直接引用。
(2).Extension ClassLoader:扩展类加载器,由sun.misc.Launcher$ExtClassLoader实现,负责加载%JAVA_HOME%\lib\ext目录中的,或者被java.ext.dirs系统变量所指定的路径中的所有类库,开发者可以直接使用扩展类加载器。
(3).Application ClassLoader:应用程序类加载器,由sun.misc.Launcher$AppClassLoader实现,负责加载用户类路径classpath上所指定的类库,是类加载器ClassLoader中的getSystemClassLoader()方法的返回值,开发者可以直接使用应用程序类加载器,如果程序中没有自定义过类加载器,该加载器就是程序中默认的类加载器。
当这些都不能满足要求的时候,就需要自定义类加载器了。那么双亲委派模型的机制是什么呢?
(1).如果一个类加载器收到了类加载请求,它首先不会自己去尝试加载这个类,而是把类加载请求委派给父类加载器去完成。
(2).每一层的类加载器都把类加载请求委派给父类加载器,直到所有的类加载请求都应该传递给顶层的启动类加载器。
(3).如果顶层的启动类加载器无法完成加载请求,子类加载器尝试去加载,如果连最初发起类加载请求的类加载器也无法完成加载请求时,将会抛出ClassNotFoundException,而不再调用其子类加载器去进行类加载。
这个机制是在loadClass方法中实现的,具体见源码:
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded Class<?> c = findLoadedClass(name); if (c == null) { long t0 = System.nanoTime(); try { if (parent != null) { c = parent.loadClass(name, false); } else { c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } if (c == null) { // If still not found, then invoke findClass in order // to find the class. long t1 = System.nanoTime(); c = findClass(name); // this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { resolveClass(c); } return c; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
4.3 自定义类加载器
需要继承ClassLoader类。由4.2知道,如果需要打破双亲委派模型,则需重写loadClass方法,如不需要,则只需重写findClass方法,(findClass方法默认直接抛出ClassNotFoundException,在双亲委派找不到类加载器的时候,就需要我们加入自己的逻辑了。)
5. JVM配置参数
-Xmx3g: 设置最大可用内存
-Xms3g: 设置初始可用内存
-Xmn2g: 设置年轻代大小
-Xss1m: 设置每个线程的堆栈大小
-XX:NewRatio=4: 设置年轻代与年老代(不含持久代)的比值
-XX:SurvivorRatio=4: 设置Eden和一个Survivor区的比值
-XX:MaxPermSize=16m: 设置持久代
-XX:MaxTenuringThreshold=0: 设置垃圾最大年龄
四、算法与数据结构
1. 找出一个字符串中第一个只出现一次的字符
例如:”abcdeab”,找出”c”.
思路:先遍历一遍字符串,用m[26]统计每个字符出现的次数,然后再扫一遍字符串只要m[a[i]-‘a’]==1就返回a[i].
2.将m个有序链表合并成一个有序链表(Leetcode 23.Merge K sorted lists)
http://blog.csdn.net/cmershen/article/details/51550304
方法一:把这些链表扔到优先队列里面,然后每次取出的链表都是头元素最小的那个,然后删掉头结点再扔回队列里面去,直到队列全空
/** * Definition for singly-linked list. * public class ListNode { * int val; * ListNode next; * ListNode(int x) { val = x; } * } */public class Solution { public ListNode mergeKLists(ListNode[] lists) { if (lists==null||lists.length==0) return null; PriorityQueue<ListNode> queue= new PriorityQueue<ListNode>(lists.length,new Comparator<ListNode>(){ @Override public int compare(ListNode o1,ListNode o2){ if (o1.val<o2.val) return -1; else if (o1.val==o2.val) return 0; else return 1; } }); ListNode dummy = new ListNode(0); ListNode tail=dummy; for (ListNode node:lists) if (node!=null) queue.add(node); while (!queue.isEmpty()){ tail.next=queue.poll(); tail=tail.next; if (tail.next!=null) queue.add(tail.next); } return dummy.next; }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
方法二:归并排序(待完善)
3.最大连续子数组和(Leetcode 53,一定背下来!!)
Kanade算法:
用dp[n]代表结尾为n的连续子数组的和最大值,则有如下转移方程:
即如果以n-1为结尾的子数组和是>0的,则前n-1项对n为结尾是“有贡献”的,那么以n为结尾的子列和就带上前面那个数组。否则从第n项开始。最后返回dp[n]里面最大值即可。因为dp[n]只跟dp[n-1]有关,故维护dp[n-1]一个变量就可以了。
public class Solution { public int maxSubArray(int[] nums) { int maxsum = -9999999; int sumk = 0; for(int num : nums) { sumk = (sumk + num > num) ? sumk + num : num; maxsum = (maxsum > sumk) ? maxsum : sumk; } return maxsum; }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4.求A的B次方的后三位
快速幂取模算法,我都有模板了,其实本质就是二进制展开,如果这一位是0就没关系,如果是1就乘进去
http://blog.csdn.net/u013486414/article/details/42318931
#include <bits/stdc++.h>using namespace std;typedef long long ll;int main() { int a,b; cin>>a>>b; int ans=1; while(b) { if(b&1) ans=(ans*a)%1000; a=(a*a)%1000; b>>=1; } cout<<ans<<endl;}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
5.翻转单链表(Leetcode 206)
用三个指针迭代翻转。不要写递归的了
ListNode* reverseList(ListNode* head) { if(!head || !head->next) return head; else { ListNode* a=head; ListNode* b=head->next; while(b) { ListNode* c=b->next; b->next=a; a=b; b=c; } head->next=null; return a; }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
6.Two sum(Leetcode 1)
方法一:排序+双指针,时间O(nlogn),空间1(这样找不到下标)
方法二:用Map存储(如果不要求下标的话set也行),扫两遍数组,第一遍记录有哪些数(以及下标),第二遍去map(set)里面查sum-i在不在
7.手写快排
private void quickSort(int[] array,int low,int high) { if(low>=high) return; int i=low,j=high,index=array[i]; while(i<j) { while(i<j && array[j]>=index) //向左找到第一个小于基准值的,搬到最左边 j--; if(i<j) //如果i==j了,这个位置就是基准值 array[i++]=array[j]; while(i<j && array[i]<index) //从左向右找到第一个大于等于基准值的,搬到最右边 i++; if(i<j) array[j--]=array[i]; } array[i]=index;//当i==j了,那个位置就是基准值 quickSort(array,low,i-1); quickSort(array,i+1,high);}public void quickSort(int[] array) { if(array.length==0) return ; quickSort(array,0,array.length-1);}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
8.手写归并排序
private void merge(int[] array,int left,int mid,int right) { int i=left,j=mid+1; int m=mid,n=right; int k=0; while(i<=m && j<=n) { if(array[i]<=array[j]) temp[k++]=array[i++]; else temp[k++]=array[j++]; } while(i<=m) temp[k++]=array[i++]; while(j<=n) temp[k++]=array[j++]; for(i=left,j=0;i<=right;i++,j++) array[i]=temp[j];}private void mergeSort(int[] array,int left,int right) { if(left<right) { int mid = (left+right)/2; mergeSort(array, left, mid); mergeSort(array, mid+1, right); merge(array,left,mid,right); }}public void mergeSort(int[] array) { if(array.length==0) return; mergeSort(array,0,array.length-1);}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
9. 二叉树非递归前序遍历、中序遍历
前序遍历:中-左-右,所以肯定先打印并放入中节点(因为要利用这些节点找右子树),然后往左走,如果左节点是空,那么说明左子树访问完毕,把当前节点弹出来(因为中节点已经访问完毕了),再放右节点。
void preOrder(TreeNode* root) { if(!root) return; stack<TreeNode*> s; TreeNode* p=root; while(!s.empty() || p) { if(p) { cout<<p->data<<endl; s.push(p); p=p->left; } else { p=s.top(); s.pop(); p=p->right; } }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
中序遍历:左-中-右,那么先一直往左走到最左的孩子节点,如果非空就一直压栈并往左走,如果空了就打印并往右走。
void inOrder(TreeNode* root) { if(!root) return; stack<TreeNode*> s; TreeNode* p=root; while(!s.empty() || p) { if(p) { s.push(p); p=p->left; } else { p=s.top(); s.pop(); cout<<p->data<<endl; p=p->right; } }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
10.给一个数组,其中一个数出现了1次,其他数都出现了2次(4次,6次,8次……都行),怎么找到这个数?
这道题非常简单,就不说了,下面讨论两种变形题:
10.1 给一个数组,其中两个数出现了1次,其他数都出现了2次,怎么找到这个数?
设这两个数是a,b.全异或起来得到a^b,然后取a^b里面一个为1的位(最低最高都行),然后把原来数组里面所有这一位为1的异或到一起,所有为0的异或到一起,就是a和b。
10.2 给一个数组,其中一个数出现了1次,其他数都出现了3次,怎么找到这个数?
假设这些数都是int范围内的,那么开一个32位的数组,记录这些数第i位上有几个1.
例如:{1,1,1,2,2,2,3,3,3,4}:1: 0012: 0103: 0114: 100- 1
- 2
- 3
- 4
- 5
那么bits[0]=6,bits[1]=6,bits[2]=1,然后遍历bits数组,看哪位的值不是3的倍数,答案的哪位就是1。时间复杂度是O(n*32).
int FindNumber(int a[], int n) { int bits[32]; int i, j; // 累加数组中所有数字的二进制位 memset(bits, 0, 32 * sizeof(int)); for (i = 0; i < n; i++) for (j = 0; j < 32; j++) bits[j] += ((a[i] >> j) & 1); // 如果某位上的结果不能被整除,则肯定目标数字在这一位上为 int result = 0; for (j = 0; j < 32; j++) if (bits[j] % 3) result += (1 << j); return result; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
11. 找出无序数组中第k大的数
类似快速排序,选择一个中轴(可以是第一个数,也可以用三者取中),比中轴大的搬到左边,小的搬到右边,然后看中轴的下标i,如果i-1==k那么a[i]即为所求,如果i-1>k,则在左边数组里继续找第k大的数,否则在右边数组里找第i-i-k大的数。
int selectk(int a[], int low, int high, int k) { if(k <= 0) return -1; if(k > high - low + 1) return -1; int m = low; //选择第一个数作为中轴 int count = 1; //一趟遍历,把较大的数放到数组的左边 for(int i = low + 1; i <= high; ++i) { if(a[i] > a[low]) { swap(a[++m], a[i]); count++; //比支点大的数的个数为count-1 } } swap(a[m], a[low]); //将支点放在左、右两部分的分界处 if(count > k) { return selectk(a, low, m - 1, k); } else if( count < k) { return selectk(a, m + 1, high, k - count); } else { return m; } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
12. 二分查找
二分查找其实大家都明白原理,小时候都看过《幸运52》吧,有一个节目是猜价格:
“100元!”
“低了!”
“200元!”
“高了!”
“150元!”
“对了!”
小学生都知道的原理,但在编程中由于边界情况比较多,实现起来也比说的难得多。
http://blog.csdn.net/yefengzhichen/article/details/52372407 这篇文章介绍的已经很细了,下面就简单摘抄一下,侵删。
12.1 最简单的版本:查找某个数的下标,如果有返回,存在多个随便返回哪个都行,不存在返回-1
public int binarySearch(int[] a,int x) { int l=0,r=a.length-1; //因为x不一定有,若x没有,则l>r退出返回-1.如果已知x一定有,则写l<r,最后因l==r退出循环,就是我们要的x while(l<=r) { int mid=l+(r-l)/2;//如果写(l+r)/2可能会爆int,最好不这么写 if(x==a[mid]) return mid; else if(x<a[mid]) r=mid-1; else l=mid+1; } return -1;}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
12.2 有可能死循环的情况:查询x最后一次出现的下标,没有则返回-1
public int binarySearch2(int[] a,int x) { int l=0,r=a.length-1; while(l<r) { //因为x不一定有,若x没有,则l>r退出返回-1.如果已知x一定有,则写l<r,最后因l==r退出循环,就是我们要的x int mid=l+(r-l+1)/2;//如果l+r为奇数的时候,要取靠后的数 if(x==a[mid]) //这行注意以下问题: //1. 因为mid不一定是解,所以不能直接return mid了 //2. 不能l=mid+1,因为我们的l有可能就是解 //3. 如果第4行不写+1,这时候取的是下界,在l r相邻的时候,mid还是l,就会出不来,所以+1确保的是区间一定会变小 l=mid; else if(x<a[mid]) r=mid-1;//因为mid的位置已经比x大了,故x最后一次出现的下标一定在mid之前 else l=mid+1; } if(l==r) return l; else return -1;}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
12.3 查询小于target的最大数的下标,如没有,返回-1
public int binarySearch3(int[] a,int x) { int l=0,r=a.length-1; while(l<r) { //因为x不一定有,若x没有,则l>r退出返回-1.如果已知x一定有,则写l<r,最后因l==r退出循环,就是我们要的x int mid=l+(r-l+1)/2;//如果l+r为奇数的时候,要取靠后的数 if(x<=a[mid]) //这里不论x是小于还是等于,mid及以后都不是解,因为我们要找的是比x还小的位置 r=mid-1; else l=mid;//此时l有可能是解,所以不能写l=mid+1 } if(l==r) return l; else return -1;}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
五、其他
1.聚簇索引和非聚簇索引的区别
聚集索引:表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。 在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种。
非聚集索引:表数据存储顺序与索引顺序无关。对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。
索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
2.数据库事务
事务(transaction)是由一系列操作序列构成的程序执行单元,这些操作要么都做,要么都不做,是一个不可分割的工作单位。
数据库事务的四个基本性质(ACID)
1. 原子性(Atomicity)
事务的原子性是指事务中包含的所有操作要么全做,要么全不做(all or none)。
- 一致性(Consistency)
在事务开始以前,数据库处于一致性的状态,事务结束后,数据库也必须处于一致性状态。
拿银行转账来说,一致性要求事务的执行不应改变A、B 两个账户的金额总和。如果没有这种一致性要求,转账过程中就会发生钱无中生有,或者不翼而飞的现象。事务应该把数据库从一个一致性状态转换到另外一个一致性状态。
隔离性(Isolation)
事务隔离性要求系统必须保证事务不受其他并发执行的事务的影响,也即要达到这样一种效果:对于任何一对事务T1 和 T2,在事务 T1 看来,T2 要么在 T1 开始之前已经结束,要么在 T1 完成之后才开始执行。这样,每个事务都感觉不到系统中有其他事务在并发地执行。持久性(Durability)
一个事务一旦成功完成,它对数据库的改变必须是永久的,即便是在系统遇到故障的情况下也不会丢失。数据的重要性决定了事务持久性的重要性。
事务并发执行,不加锁,会引起的四个问题:(线程不加锁也会因此这四个问题)
1、丢失修改
事务T1,T2读取同一个数据,之后先后将修改的内容,写回数据库,会导致一个事务丢失修改。
例子:
数据a = 1;
T1, T2对a加1, 先后将读取a的之后, 又先后将2写进a,这样导致丢失修改。正确的a的值应该是3。
2、脏读
T1修改某个数据a,这是T2去读,之后T1撤销事务,a回到原来的值,这是T2读到的a的值就是一个错误的值,即脏数据。
3、不可重复读
T1读取了一个数据之后,之后T2修改了这数据,T1在读这个数据,发现和之前读的不相同。
4、幻读
T1按照某个条件从数据库中查找出了某些数据,之后T2对表的记录进行插入和删除,T1在按相同的条件从数据库中,查找数据,发现记录条数多了或者少了,就像出现幻觉一样。
3.Spring的IoC(控制反转)和AOP(面向切面)怎么理解?
IoC(Inversion of Control):IoC就是应用本身不依赖对象的创建和维护而是交给外部容器(这里为spring),这要就把应用和对象之间解耦,控制权交给了外部容器。看一个小例子:
package com.ljq.test;public interface HelloService { public void sayHello(); }- 1
- 2
- 3
- 4
- 5
那么现在我们需要HelloService里面的方法,我们先配置一下helloworld.xml:
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd"> <!-- id 表示组件的名字,class表示组件类 --> <bean id="helloService" class="com.ljq.test.HelloServiceImpl" /></beans>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
我们看到了, 这里配置的Bean是他的实现类HelloServiceImpl!!!!具体怎么实现的?I don’t care!!!
接下来我们在工程里使用这个方法:
public void testHelloWorld() { // 1、读取配置文件实例化一个IOC容器 ApplicationContext context = new ClassPathXmlApplicationContext("helloworld.xml"); // 2、从容器中获取Bean,注意此处完全“面向接口编程,而不是面向实现” HelloService helloService = context.getBean("helloService", HelloService.class); // 3、执行业务逻辑 helloService.sayHello();}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
那么如果sayHello需要改动,我们只需要改HelloServiceImpl即可,大不了换了个其他类,这样就实现了低耦合。
AOP即面向切面编程,可以将一个与各组件关系不大的但需要大量重复的功能(如记录日志)以类似于“切片”的方式插入系统的组件中,实现代码的重用。
还是用一个例子来说明。一个人需要吃苹果,那么吃苹果之前要洗手。同理吃什么之前都要洗手,我们把”洗手”这个动作看做切片,注入到吃苹果方法的前面:
首先写一个接口IToDo,里面只有吃苹果一个方法:
package com.service.imp;public interface IToDo { public String toEat();}- 1
- 2
- 3
- 4
- 5
- 6
实现出来,这里也只是输出吃苹果:
package com.service;import org.springframework.stereotype.Service;import com.service.imp.IToDo;@Servicepublic class ToDo implements IToDo { @Override public String toEat() { System.out.println("吃苹果"); return "吃苹果"; }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
接下来完成洗手方法的接口和实现类(略):
package com.service.imp;public interface IPreDo { public String toPre();}- 1
- 2
- 3
- 4
- 5
- 6
applicationContext.xml配置
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:task="http://www.springframework.org/schema/task" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.0.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.0.xsd http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task-3.0.xsd"> <context:component-scan base-package="com.service" /> <aop:aspectj-autoproxy /> <aop:config proxy-target-class="true"> <aop:aspect ref="preDo"> <aop:pointcut expression="execution(* com.service.ToDo.toEat(..))" id="register" /> <aop:before method="toPre" pointcut-ref="register" /> </aop:aspect> </aop:config></beans>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
然后我们实现这个吃苹果的工程:
public class application { public static void main(String[] args) { ApplicationContext appCtx = new ClassPathXmlApplicationContext("applicationContext.xml"); IToDo tdo = (IToDo)appCtx.getBean("toDo"); tdo.toEat(); }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
显然从容器里拿出来了一个叫IToDo的Bean,在这里我们只看到了吃苹果,那么洗手是怎么来的呢?奥秘就在xml配置里面!
这里面配置了preDo类,作为com.service.ToDo.toEat方法的前置方法,且是在方法执行前切入。
那么如果我们吃梨、吃桃子、吃别的、以及其他需要洗手的动作执行前也加上洗手这一动作,只需要修改配置文件即可。不必在每个函数前面都加上洗手方法。
4.数据库的索引
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
5.判断一个元素是否存在一个大集合里面
例题:给你100亿个email地址,然后给出一个email地址,判断在不在这个地址库里面。
答案是用布隆过滤。
基本的布隆过滤器就是一个长为m的比特串,初始化为0.还需要构建k个hash函数,其中第i个hash函数对元素E的hash值记为hash(i,E),再将这个hash值映射到[0,m-1]里面。(例如可以用取模m)。那么这个串支持3种操作:
* 加入一个元素E:计算hash(1,E),hash(2,E)...,然后把这k个hash值对应的位置为1.
* 查找元素E是否存在:计算hash,然后看对应位是否全为1.(这里会有误报,也就是有可能不在库里的字符串恰巧使得这些位都是1了,那也认为是存在的)
* 删除:如果用bit串,那是不能删除的,如果非要删除可以考虑用int数组代替bit串,这叫做Count Bloom Filter(CBF).
6.判断大量数据的重复问题(或者排序)
例题:已知某个大文件里面有一亿个电话号码,每个号码为8位数字,统计不同号码的个数。
答案:位图法。
8位数字可以表示的最大十进制数为8个9,如果每个数字对应位图中一个bit位,那么这个bit串的长度为1e8,也就是12.5MB,然后统计这个bit串有多少个1即可。(也可以排序)
7.B树和B+树
B树的每个节点都有信息,每个节点至多有k个孩子,至少有(k/2)个孩子(除了根节点和叶子),有m个关键字的节点有m+1个孩子,孩子节点的关键值范围是开区间(保证唯一)。
B+树则在B树的基础上修改:非叶子节点的子树个数等于关键字个数,孩子节点范围是父节点的左闭右开区间,只有叶子节点有关键字,父节点都是指针,叶子节点连成链表。只在叶子节点命中,即使其他节点遇到相等的值,也继续向下搜索。
8.Mysql的存储引擎innodb和myisam的区别
1 存储结构
MyISAM:每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。
2 存储空间
MyISAM:可被压缩,存储空间较小。支持三种不同的存储格式:静态表(默认,但是注意数据末尾不能有空格,会被去掉)、动态表、压缩表。
InnoDB:需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。
3 事务支持
MyISAM:强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。
InnoDB:提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
4 CURD操作
MyISAM:如果执行大量的SELECT,MyISAM是更好的选择。(因为没有支持行级锁),在增删的时候需要锁定整个表格,效率会低一些。相关的是innodb支持行级锁,删除插入的时候只需要锁定改行就行,效率较高
InnoDB:如果你的数据执行大量的 INSERT 或 UPDATE ,出于性能方面的考虑,应该使用InnoDB表。 DELETE 从性能上InnoDB更优,但DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除,在innodb上如果要清空保存有大量数据的表,最好使用truncate table这个命令。
5 外键
MyISAM:不支持
InnoDB:支持
9. Mysql的隔离级别
READ UNCOMMITTED(读取未提交):最低级别的隔离,通常又称为dirty read,它允许一个事务读取还没commit的数据,这样可能会提高性能,但是dirty read可能不是我们想要的,这个很少用到,因为四种并发问题都阻止不了
READ COMMITTED:在一个事务中只允许已经commit的记录可见,如果session中select还在查询中,另一session此时insert一条记录,则新添加的数据不可见。
REPEATABLE READ:在一个事务开始后,其他session对数据库的修改在本事务中不可见,直到本事务commit或rollback。在一个事务中重复select的结果一样,除非本事务中update数据库。
SERIALIZABLE:最高级别的隔离,只允许事务串行执行。为了达到此目的,数据库会锁住每行已经读取的记录,其他session不能修改数据直到前一事务结束,事务commit或取消时才释放锁。

10. hash冲突怎么解决?
四种方法:
* 开放地址法:如果hash表的第i项已经有值了,那么看看第i+1(也可以是i+M、M是其他数值或者随机数)项是否为空,以此类推直到hash表满了或者找到空位。
* 再hash法:同时构造多个hash函数,一个冲突了再用另一个hash函数计算一下,直到不冲突。
* 链地址:就像java的hashmap那样维护链表就是了
* 公共溢出区:把hash表分为两部分,一部分存不冲突的,一部分存冲突的
- Android面经总结
- Android面经总结
- Android面经总结
- 面经总结
- 面经总结
- Java面经总结
- 面经总结
- 面经总结
- 网友面经总结
- 面经总结
- 面经-来自资深猎头的总结
- #F面经#f design question 总结
- 2017暑期前端实习面经总结
- 2018秋招前端面经总结
- 2018秋招前端面经总结
- 面试题总结(自己总结)
- java面试题总结
- 面试题总结
- 使用spring cloud+dotnet core搭建微服务架构:服务治理
- itext 微软雅黑 西罗马 Times New Roman ttf下载
- jmeter对http get网站访问压力测试
- cvc-complex-type.2.3: Element 'servlet' cannot have character [children], because the type's content
- 专业相关知识
- 面经总结
- poi API大全
- linux下的stdin,stdout,stderr详解
- 【Android4.4蓝牙代码分析】- 蓝牙Enable过程
- spring-boot 启动
- java-正则表达式判断手机号
- AsyncTask,HandlerThread,IntentService 与 ThreadPool 分别适合的使用场景
- 事物的手动回滚
- 关于Error contacting service. It is probably not running错误的解决办法


