Spring Cloud构建微服务架构:Hystrix监控数据聚合【Dalston版】
来源:互联网 发布:360数据恢复大师电脑版 编辑:程序博客网 时间:2024/06/05 12:47
上一篇我们介绍了使用Hystrix Dashboard来展示Hystrix用于熔断的各项度量指标。通过Hystrix Dashboard,我们可以方便的查看服务实例的综合情况,比如:服务调用次数、服务调用延迟等。但是仅通过Hystrix Dashboard我们只能实现对服务当个实例的数据展现,在生产环境我们的服务是肯定需要做高可用的,那么对于多实例的情况,我们就需要将这些度量指标数据进行聚合。下面,在本篇中,我们就来介绍一下另外一个工具:Turbine。
准备工作
在开始使用Turbine之前,我们先回顾一下上一篇中实现的架构,如下图所示: 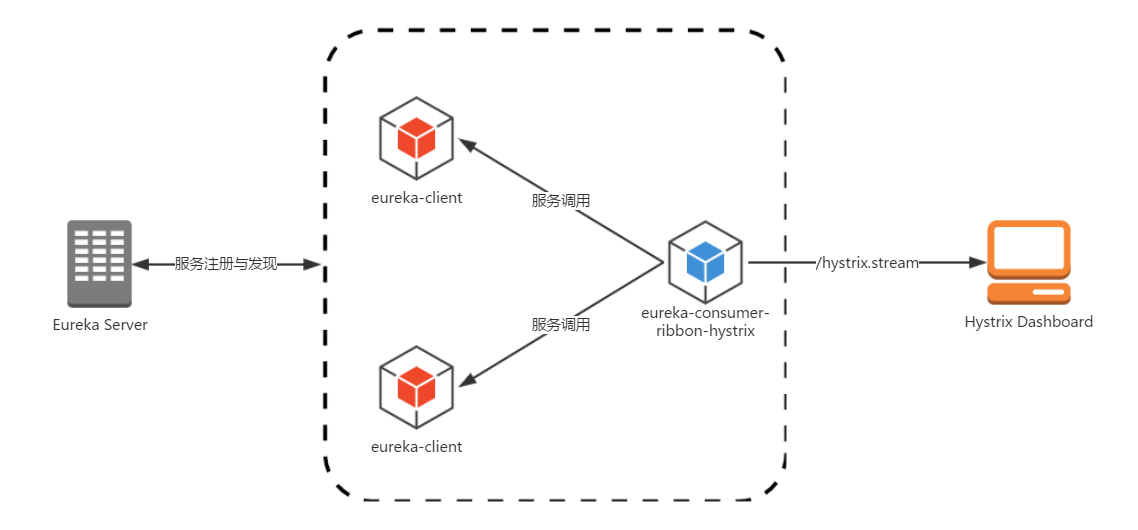
其中,我们构建的内容包括:
- eureka-server:服务注册中心
- eureka-client:服务提供者
- eureka-consumer-ribbon-hystrix:使用ribbon和hystrix实现的服务消费者
- hystrix-dashboard:用于展示
eureka-consumer-ribbon-hystrix服务的Hystrix数据
动手试一试
具体实现步骤如下:
- 创建一个标准的Spring Boot工程,命名为:turbine。
- 编辑pom.xml,具体依赖内容如下:
<parent> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-parent</artifactId> <version>Dalston.SR1</version> <relativePath /> <!-- lookup parent from repository --></parent><dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-turbine</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency></dependencies>- 创建应用主类
TurbineApplication,并使用@EnableTurbine注解开启Turbine。
@Configuration@EnableAutoConfiguration@EnableTurbine@EnableDiscoveryClientpublic class TurbineApplication { public static void main(String[] args) { SpringApplication.run(TurbineApplication.class, args); }}- 在
application.properties加入eureka和turbine的相关配置,具体如下:
spring.application.name=turbineserver.port=8989management.port=8990eureka.client.serviceUrl.defaultZone=http://localhost:1001/eureka/turbine.app-config=eureka-consumer-ribbon-hystrixturbine.cluster-name-expression="default"turbine.combine-host-port=true参数说明
turbine.app-config参数指定了需要收集监控信息的服务名;turbine.cluster-name-expression参数指定了集群名称为default,当我们服务数量非常多的时候,可以启动多个Turbine服务来构建不同的聚合集群,而该参数可以用来区分这些不同的聚合集群,同时该参数值可以在Hystrix仪表盘中用来定位不同的聚合集群,只需要在Hystrix Stream的URL中通过cluster参数来指定;turbine.combine-host-port参数设置为true,可以让同一主机上的服务通过主机名与端口号的组合来进行区分,默认情况下会以host来区分不同的服务,这会使得在本地调试的时候,本机上的不同服务聚合成一个服务来统计。
在完成了上面的内容构建之后,我们来体验一下Turbine对集群的监控能力。分别启动eureka-server、eureka-client、eureka-consumer-ribbon-hystrix、turbine以及hystrix-dashboard。访问Hystrix Dashboard,并开启对http://localhost:8989/turbine.stream`的监控,这时候,我们将看到针对服务eureka-consumer-ribbon-hystrix的聚合监控数据。
而此时的架构如下图所示:
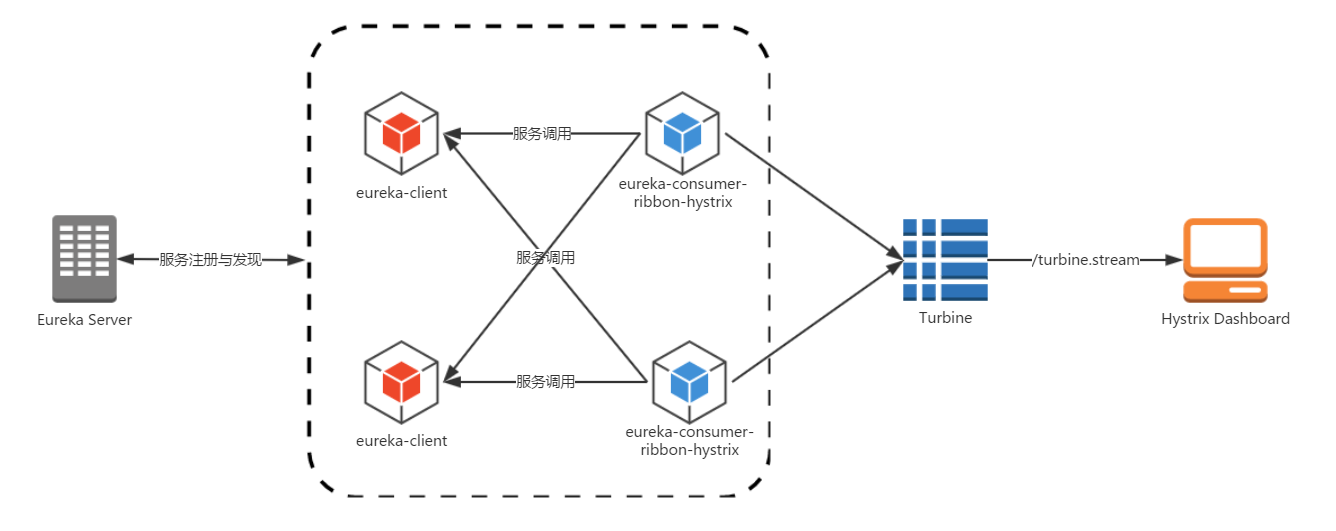
通过消息代理收集聚合
Spring Cloud在封装Turbine的时候,还实现了基于消息代理的收集实现。所以,我们可以将所有需要收集的监控信息都输出到消息代理中,然后Turbine服务再从消息代理中异步的获取这些监控信息,最后将这些监控信息聚合并输出到Hystrix Dashboard中。通过引入消息代理,我们的Turbine和Hystrix Dashoard实现的监控架构可以改成如下图所示的结构:

从图中我们可以看到,这里多了一个重要元素:RabbitMQ。对于RabbitMQ的安装与基本时候我们可以查看之前的《Spring Boot中使用RabbitMQ》一文,这里不做过多的说明。下面,我们可以来构建一个新的应用来实现基于消息代理的Turbine聚合服务,具体步骤如下:
- 创建一个标准的Spring Boot工程,命名为:turbine-amqp。
- 编辑pom.xml,具体依赖内容如下:
<parent> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-parent</artifactId> <version>Dalston.SR1</version> <relativePath /> <!-- lookup parent from repository --></parent><dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-turbine-amqp</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency></dependencies>可以看到这里主要引入了spring-cloud-starter-turbine-amqp依赖,它实际上就是包装了spring-cloud-starter-turbine-stream和pring-cloud-starter-stream-rabbit。
注意:这里我们需要使用Java 8来运行
- 在应用主类中使用@EnableTurbineStream注解来启用Turbine Stream的配置。
@Configuration@EnableAutoConfiguration@EnableTurbineStream@EnableDiscoveryClientpublic class TurbineApplication { public static void main(String[] args) { SpringApplication.run(TurbineApplication.class, args); }}- 配置application.properties文件:
spring.application.name=turbine-amqpserver.port=8989management.port=8990eureka.client.serviceUrl.defaultZone=http://localhost:1001/eureka/对于Turbine的配置已经完成了,下面我们需要对服务消费者eureka-consumer-ribbon-hystrix做一些修改,使其监控信息能够输出到RabbitMQ上。这个修改也非常简单,只需要在pom.xml中增加对spring-cloud-netflix-hystrix-amqp依赖,具体如下:
<dependencies> ... <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-netflix-hystrix-amqp</artifactId> </dependency></dependencies>在完成了上面的配置之后,我们可以继续之前的所有项目(除turbine以外),并通过Hystrix Dashboard开启对http://localhost:8989/turbine.stream的监控,我们可以获得如之前实现的同样效果,只是这里我们的监控信息收集时是通过了消息代理异步实现的。
代码示例
样例工程将沿用之前在码云和GitHub上创建的SpringCloud-Learning项目,重新做了一下整理。通过不同目录来区分Brixton和Dalston的示例。
- 码云:点击查看
- GitHub:点击查看
原作者:程序员didi
原文出处:http://blog.didispace.com/spring-cloud-starter-dalston-5-2/
- Spring Cloud构建微服务架构:Hystrix监控数据聚合【Dalston版】
- Spring Cloud构建微服务架构:Hystrix监控数据聚合
- Spring Cloud构建微服务架构:Hystrix监控面板【Dalston版】
- Spring Cloud构建微服务架构:服务容错保护(Hystrix服务降级)【Dalston版】
- Spring Cloud构建微服务架构:服务容错保护(Hystrix依赖隔离)【Dalston版】
- Spring Cloud构建微服务架构:服务容错保护(Hystrix断路器)【Dalston版】
- Spring Cloud构建微服务架构:Hystrix监控面板
- Spring Cloud构建微服务架构Hystrix监控面板
- Spring Cloud构建微服务架构Hystrix监控面板
- Spring Cloud构建微服务架构:服务注册与发现(Eureka、Consul)[Dalston版]
- Spring Cloud构建微服务架构:服务注册与发现(Eureka、Consul)【Dalston版】
- Spring Cloud构建微服务架构:服务消费(基础)【Dalston版】
- Spring Cloud构建微服务架构:服务消费(Ribbon)【Dalston版】
- Spring Cloud构建微服务架构:服务消费(Feign)【Dalston版】
- Spring Cloud构建微服务架构:服务注册与发现(Eureka、Consul)【Dalston版】
- Spring Cloud构建微服务架构:服务消费(基础)【Dalston版】
- Spring Cloud构建微服务架构:服务消费(Ribbon)【Dalston版】
- Spring Cloud构建微服务架构:服务消费(Feign)【Dalston版】
- 关于怎么将导出文件设置为中文名字
- JSON stringify 和 JSON parse
- winrar5.50去广告教程(仅供学习使用)
- 将压缩文件解压到指定目录
- linux echo命令的-n、-e两个参数
- Spring Cloud构建微服务架构:Hystrix监控数据聚合【Dalston版】
- 数据库基础
- 【计算机动画】形状插值
- 2017杭州云栖大会_.top域名不仅来了_还带了一段freestyle
- 不同系统之间的文件传输
- DOM基础
- pygtk 编写多线程程序
- .gitignore
- OpenGL学习脚印:缓冲对象相关函数的使用(buffer object function)


