java基础知识
来源:互联网 发布:主力资金知乎 编辑:程序博客网 时间:2024/05/16 09:45
集合相关的知识
1 set,list,map的区别
set和list都是继承与collection接口类,他们的不同是,set不允许有重复值(这个重复值是由equals决定的),不能维护次序,list是允许有重复值的,可以维护次序
map是另一个接口体系,存放键值对,key值是不允许重复的。
2 认识Collections
提供了一些操作Collection的静态方法
1)排序,二分查找(如何使用),反转

2)list列表的填充,求最大值和最小值,还有实现集合的同步(静态代理实现)


3集合中使用的数据结构
1)哈希算法
哈希算法是散列算法,是一种单向的密码体制,就是只有加密过程,没有解密的过程,而且生成的是固定长度的输出
==和equals的区别,==比较值和hashcode,equals只是比较值
哈希算法要尽量是输出不产生冲突,如果冲突要通过再散列解决之。
算法:斐波那契(Fibonacci)散列法,MD5算法等等
2)红黑树
http://www.cnblogs.com/yangecnu/p/Introduce-Red-Black-Tree.html
3)链表
4)数组
4 Vector
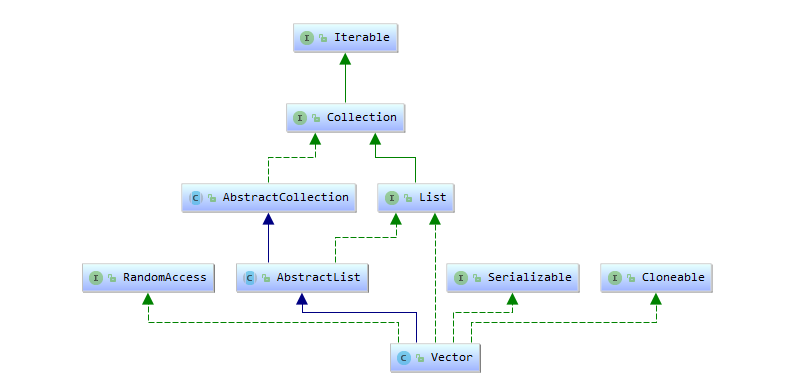
vector是list的继承体系,他通过同步锁sychronized实现了线程安全,并发下的性能比较低了。
hashtable是map的继承体系,也是使用sychronized实现线程安全,并发下要锁整个表,性能很低。
目前在并发包中有了替代产品:
ConcurrentHashMap
CopyOnWriteArrayList
CopyOnWriteArraySet
ArrayBlockingQueue
LinkedBlockingQueue
4 ArrayList,LinkedList之间的区别
他们都是list的继承体系,就具有list的特点(重复值,有序等等),只是提供不同场景下的性能需求
arrayList是对数组的封装,数组是一个连续的空间,通过索引进行查找,非常快,修改时要进行数据的移动,比较慢
linkedList是链表的实现,链表有前后的指针,存储上不连续,当进行删除,添加的时候,非常快,当查找是,要从链头进行查找,比较慢
5 hashset,linkedHashSet,treeset的区别
往haseset里面存对象,先通过调用hashcode()方法,获取到这个对象的hashcode,再把这个对象放在hashcode对应的位置上,所以重写equals方法也应该重写hashcode方法,如果对象是eqauls的,那么他们的hashcode也是相同的。
linkedhashset也是根据hashcode决定存放位置的,通过链表决定存放顺序,维持一个顺序。
迭代的时候,linkedHashSet好,插入操作的时候,hashset比较好。
treeSet是一个排序的集合,集合里面的对象实现compareTo接口,通过这个方法返回的值来判定对象的大小。
6 HashMap,LinkedHashMap,TreeMap
他们都是map体系的具体实现类,各有各的特点
hashMap在插入,删除,定位的时候性能比较高,linkedHashMap和linkedHashSet差不多,都是维持一种自然顺序,如果选择按照存储先后顺序遍历,那么linkedHashMap比较好,treeMap是一种排序map,按顺序遍历比较好。
hashmap的源代码和存储机制:
hashmap中维护了一个数组,数组的元素是Entry<key,value>的链表,存入数据的时候,首先是根据key计算这个对象的hashcode,根据hashcode获取索引(下标),把这个entry存放在数组中,如果有hash冲突,那么就会加到链表上,查找的时候,根据key找到数组下标,找到下标就找到了链表头,再从链表的头开始遍历。
DEFAULT_INITIAL_CAPACITY初始容量,DEFAULT_LOAD_FACTOR是负载因子,如果new HashMap的时候,没有指定参数,那么就用这两个默认的常量,一个是16,一个0.75,计算结果是12,这个值就是数组的大小,如何理解这两个值,如何选择从而使性能更高呢?
如果我们事先知道我们大概存放数据的范围,那么可以在new hashMap的时候,指定合适的capacity和factor,减少put数据时不断的扩容工作。
加入我们知道我们需要存放10000个对象,那么我们在new的时候就直接设定一个2的n次方距离10000很近的数值,那么在初始化的时候,map中的数组就差不多有10000个长度,在put时候,就免去了扩容和重排的时间消耗,这就是空间换时间的概念。
总结:
hashmap,hashset在添加,删除,定位的时候速度快
linkedHashMap,linkedHashSet按照自然顺序遍历的时候,使用
treeSet,treeMap按照自定义排序顺序遍历的时候,使用
7 并发的集合工具
1 )ConcurrentHashMap
ConcurrentHashMap在线程安全的基础上提供了更好的写并发能力,但同时降低了对读一致性的要求;ConcurrentHashMap的设计与实现非常精巧,大量的利用了volatile,final,CAS等lock-free技术来减少锁竞争对于性能的影响,无论对于Java并发编程的学习还是Java内存模型的理解,ConcurrentHashMap的设计以及源码都值得非常仔细的阅读与揣摩。
在ConcurrentHashMap中,有很多的segment段,每一个segment都有自己的锁,就是分段锁的实现,当put数据的时候,根据key值先计算hashcode值h1,根据h1再计算一下h2找到自己的segment,再计算哈希值h3,就是放置hashEntry的地方,因为有好几个segment,如果多线程的时候,不是在同一个segment上操作的话,那么就可以实现并发写操作,从而提高了性能。
put操作步骤:
(1)value为null,抛异常
(2)根据key获取hashcode值h1,再计算出segment数组的下标,获取到segment
(3)这个segment就加锁了,把value放到hashEntry中,实现了put操作
get操作步骤:
和put差不多,找到segment,在这个segment上找到key对应的hashEntry,get的时候不加锁,通过volitle保证可见性
删除的时候也不加锁,它的实现是将目entry之前的拷贝,之后的关联上,把目标删除,在删除的同时,因为是拷贝操作,不影响原来链表的操作,相当于在两个链表上操作????
size这种全局方法的实现
size操作与put和get操作最大的区别在于,size操作需要遍历所有的Segment才能算出整个Map的大小,而put和get都只关心一个Segment。
真正的不是先对所有的segement加锁,而是按照下面的思路:
先给3次机会,不lock所有的Segment,遍历所有Segment,累加各个Segment的大小得到整个Map的大小,如果某相邻的两次计算获取的所有Segment的更新的次数是一样的,说明计算过程中没有更新操作,则直接返回这个值。如果这三次不加锁的计算过程中Map的更新次数有变化,则之后的计算先对所有的Segment加锁,再遍历所有Segment计算Map大小,最后再解锁所有Segment;
总结concurrentHashMap
JDK6,7中的ConcurrentHashmap主要使用Segment来实现减小锁粒度,把HashMap分割成若干个Segment,在put的时候需要锁住Segment,get时候不加锁,使用volatile来保证可见性,当要统计全局时(比如size),首先会尝试多次计算modcount来确定,这几次尝试中,是否有其他线程进行了修改操作,如果没有,则直接返回size。如果有,则需要依次锁住所有的Segment来计算。
jdk7中ConcurrentHashmap中,当长度过长碰撞会很频繁,链表的增改删查操作都会消耗很长的时间,影响性能,所以jdk8 中完全重写了concurrentHashmap,代码量从原来的1000多行变成了 6000多 行,实现上也和原来的分段式存储有很大的区别。
主要设计上的变化有以下几点:(以后了解)
不采用segment而采用node,锁住node来实现减小锁粒度。
设计了MOVED状态 当resize的中过程中 线程2还在put数据,线程2会帮助resize。
使用3个CAS操作来确保node的一些操作的原子性,这种方式代替了锁。
sizeCtl的不同值来代表不同含义,起到了控制的作用。
2)CopyOnWriteArrayList
CopyOnWrite技术是一种读写分离的技术,在写的时候,会加锁,并创建一个新的数组,长度是原来的长度+1,并把原来的数据拷贝到这个新的数组上面,添加完成之后,把引用指向这个新的数组,在添加的过程中,读的还是原来的数组,当读的时候,别的线程在写,那么读到的是旧数据。CopyOnWrite并发容器用于读多写少的并发场景。
CopyOnWrite容器有很多优点,但是同时也存在两个问题,即内存占用问题和数据一致性问题。所以在开发的时候需要注意一下。
内存占用:
比如说以前的容器放了100m的数据,在添加的时候,就会产生一个100m的新数组,这个大对象直接进入old区,有可能触发full gc等操作,并产生很长时间的暂停,这个时候就需要性能的调优:比如说把存入容器的对象优化变小,比如十进制换成64进制,这样数据变化比较明显,占有内存变小,触发垃圾回收的几率变小;或者说不适用这种容器,用ConcurrentHashMap替代试试。
数据实时性问题:
这个容器的修改不能实时被看见,如果不满足需求的话,就不使用这个容器,使用ConcurrentHashMap。
CopyOnWriteArraySet
和CopyOnWriteArrayList相似,区别是在list和set数据结构的区别。
3)ArrayBlockingQueue
可阻塞的队列,使用ReentrantLock实现,包含了notEmpty和notFull,add()方法,如果满了,抛出异常,put()方法,如果满了,block住,等待唤醒。
实现生产者和消费者非常简单,可以使用put和take组合,只需要简单的代码就可以实现,生产者使用put方法,满了就block,等待消费者消费,并通知生产者,消费者通过take()拿,空了,就block住,等生成者生产,并通知。
LinkedBlockingQueue
链表的实现方式,和array的区别,array查找速度快,linked更新比较快。
final,static,native的使用
8 通过native实现JNI的过程:
1)在java类中定义一个native方法
2)编译程class文件
3) 通过javah -jni 类名生成.h的c文件,里面有对应的方法名
4)编写cpp文件,实现那个方法,生成动态链接库.dll文件
5)运行java文件,实现本地调用。
匿名内部类和静态内部类
同步异步的理解:
一个任务的执行会不会影响整个流程的等待是判断同步和异步的标准:
一个任务执行完,才可以执行下一个(同步)
多个线程的同时执行,没有锁的抢占,各个线程之间互补影响(异步)
多个线程,都在争抢资源,一个线程执行,其他线程等待(同步)
所以多线程和异步不能划等号
阻塞和非阻塞的理解
执行操作,发出请求,如果条件不满足就等待,这就是(阻塞)
执行操作,发出请求,如果不满足,返回标志信息(非阻塞)
比如读取文件,没有内容,就一直等到有内容才继续执行,这就是阻塞,如果直接返回没有内容的标记,就是非阻塞
阻塞IO和非阻塞的IO
当用户线程发起一个IO请求操作(本文以读请求操作为例),内核会去查看要读取的数据是否就绪,对于阻塞IO来说,如果数据没有就绪,则会一直在那等待,直到数据就绪;对于非阻塞IO来说,如果数据没有就绪,则会返回一个标志信息告知用户线程当前要读的数据没有就绪。当数据就绪之后,便将数据拷贝到用户线程,这样才完成了一个完整的IO读请求操作,也就是说一个完整的IO读请求操作包括两个阶段:
1)查看数据是否就绪;
2)进行数据拷贝
Java中传统的IO都是阻塞IO,比如通过socket来读数据,调用read()方法之后,如果数据没有就绪,当前线程就会一直阻塞在read方法调用那里,直到有数据才返回;而如果是非阻塞IO的话,当数据没有就绪,read()方法应该返回一个标志信息,告知当前线程数据没有就绪,而不是一直在那里等待。
同步IO和异步IO
这里涉及到线程和内核的交互问题
一个线程调用同步IO,不断轮询和内核交互,判断有没有完成,没有完成就一直停止哪个位置,不向下进行,就是同步的IO
一个线程调用异步IO,发出请求,就交给内核去执行了,线程不停在哪个位置上,而是向下执行,就是异步IO,这里必须要有底层的支持才可以实现
同步IO和异步IO的关键区别反映在数据拷贝阶段是由用户线程完成还是内核完成。所以说异步IO必须要有操作系统的底层支持。
9 IO和NIO(JDK8中的新特性)
IO的读取过程

1 jvm启动了项目,这个jvm对于操作系统来说是一个进程,他不能直接操作硬件系统,必须通过操作系统完成
2 操作系统会一次读取硬盘的一块区域到操作系统的缓冲区(第一读会很慢,后面就快了)
3 jvm会一点点从操作系统的缓冲区读到用户的buffer里面来
4 这种读写是阻塞的,面向流的,不能使用并发
对于文件I/O, 在我看来使用IO和NIO是区别不大的,Java1.4开始原始IO也根据NIO重新实现过了,提供了对于NIO特性的支持。即使是流,也会比以前更加高效。企业级应用软件中涉及I/O的部分多半是读写文件的功能性需求,很少有在并发上的要求,那么JavaIO包已经很胜任了。
对于网络I/O,传统的阻塞式I/O,一个线程对应一个连接,采用线程池的模式在大部分场景下简单高效。当连接数茫茫多时,并且数据的移动非常频繁,NIO无疑是更好的选择。
Java异常处理机制,分类等
所有的异常都继承Throwable接口,子类有Error和Exception,Error是项目运行中的jvm的一些错误,比如内存溢出等,这种错误通知我们后,需要我们关闭系统,分析原因解决。Exception包含了RuntimeException和其他的异常,RuntimeException是运行期的异常,主要是和编写代码的质量有关系,是存在的bug,比如数组越界(indexoutboundException),除0的错误,类强制转换异常,空指针异常等等,需要开发人员解决掉错误。其他的异常,比如IO,SQL,甚至是自定义的异常等等需要我们在业务层面去处理的。这些异常出现的时候,我们可以决定如何解决,以什么样的方式来回应客户。
- Java基础知识
- java基础知识
- java基础知识
- JAVA基础知识
- Java基础知识
- java基础知识
- java基础知识
- java基础知识
- java基础知识
- java基础知识
- java基础知识
- java基础知识
- JAVA基础知识
- Java 基础知识
- JAVA基础知识
- Java基础知识
- Java基础知识
- Java基础知识
- OSI网络模型与TCP/IP协议族
- Thrift原理简析(JAVA)
- Linux权限(鸟哥Linux私房菜读书笔记)
- LDAP用户导入Ambari
- 模拟练习
- java基础知识
- CSDN使用
- AGC010
- 管理网络
- 51Nod 1422 沙拉酱前缀
- Selenium browser.helperApps.neverAsk.saveToDisk不起效的解决
- java面试题集锦
- lucene7.1.0 (四) 各种查询
- angularJs 用户添加


