LSTM模型理论总结
来源:互联网 发布:对讲机写频软件下载 编辑:程序博客网 时间:2024/05/14 03:22
0诸论

1.传统RNN模型的问题:梯度的消失和爆发
说到LSTM,无可避免的首先要提到最简单最原始的RNN。
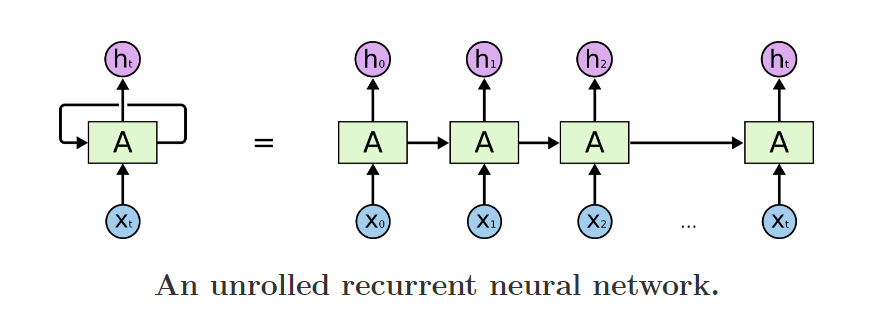
我们经常可以看到有人说,LSTM适合时序序列,变长序列,尤其适合自然语言处理。那么是什么赋予它可以处理变长序列的能力呢? 其实,只要仔细研究上图,相信每个人都能有一个直观的答案。
从图片左边来看,RNN有两个输入,一个是当前t时刻的输入Xt, 另一个是一个看似“本身“的输入。
这样看还不甚明了,再看图片右边: 实际上右图是左图的一个在时间序列上的展开,上一个时刻输出是这一个时刻的输入。值得注意的是,实际上,右图上的所有神经元是同一个神经元,也就是左图,它们共享同样的权值,只不过在每一个时刻接受不同的输入,再把输出给下一个时刻作为输入。这就是存储的过去的信息。

先看一下比较典型的BPTT(Back propgation through time)一个展开的结构,如下图,这里只考虑了部分图。

对于t时刻的误差信号计算如下:
推导公式如下:

上面的公式在整个BPTT乃至整个BP网络里都是非常常见的了。具体推导如下,做个演示:

那么如果这个误差信号一直往过去传呢,假设任意两个节点u, v他们的关系是下面这样的:

那么误差传递信号的关系可以写成如下的递归式:

继续说上面的公式,n表示图中一层神经元的个数,这个公式不难理解,要求从t时刻某节点u传递到t-q时刻某节点v的误差,那么就需要先求出u传递到t-q+1时刻所有节点的误差之后,再进行相邻两层之前的回传(也就是之前那个公式)。
这显然是一个递归的过程,把里面连乘展开看:

看起来比较复杂,事实上可以这么说:
前面的q-1个加和符号,就是在误差回传过程中,从u到v遍历了所有中间层的可能的链接起来的路径。
后面的连乘法就是其中一条路径的误差表示,总共经历了q个层,每一层都要经过一个激活函数的导数和权值相乘。
展开来看,把后面的这个连乘的式子叫做T的话:

整个结果式对T求和的次数是n^(q-1), 即T有n^(q-1)项
而每一个T经过了q次这样的系数的乘法:

如果上式> 1, 误差就会随着q的增大而呈指数增长,那么网络的参数更新会引起非常大的震荡。
如果上式< 1, 误差就会消失,导致学习无效,一般激活函数用sigmoid函数,它的倒数最大值是0.25, 权值最大值要小于4才能保证不会小于1。
误差呈指数增长的现象比较少,误差消失在BPTT中很常见。
到这里,我们大致应该可以明白了,由于经过每一层误差反传,就会引入一个激活函数的导数的乘子,所以导致经过多步之后,这个乘子的连乘会导致一系列麻烦,即我们所谓的梯度消失和爆发的问题。
事实上,上面这个式子结果的分析是非常复杂的,因为我们可以调节w和增加每一层的节点数n来对结果进行调节。但是事实上这些做法都不能完善的解决,因为w是每一层都共享的参数,它会影响net的值,而net值的变化会对激活函数的导数有影响。
举个例子,即便把w变成无限大,那么导致net也会无限大,导致激活函数的导数为0。
事实上原文也对这些问题进行了分析,并且验证了上面说道的两个问题,但是更深入的分析是一个非常复杂的情况,涉及到高阶无穷小和w的调节等一系列动态的问题。作者在原文中都没有继续说清楚。
更加深入的理解这个问题可以参照这篇论文,
《On the difficulty of training Recurrent Neural Networks》Razvan Pascanu,Tomas Mikolov,Yoshua Bengio
这里面深入讨论了vanishing and the exploding gradient 的本质(w矩阵特征值等复杂的原理),和他们带来的一些现象。
梯度消失和爆发不是这篇文章的重点,所以我暂时写到这里,总结一下,对于常见的梯度消失问题来说:
传统的RNN模型,在训练的过程中的梯度下降过程中,更加倾向于按照序列结尾处的权值的正确方向进行更新。也就是说,越远的序列输入的对权值的正确变化所能起到的“影响”越小,所以训练的结果就是往往出现偏向于新的信息,即不太能有较长的记忆功能。
2.LSTM对问题的解决方式
为了克服误差消失的问题,需要做一些限制,先假设仅仅只有一个神经元与自己连接,简图如下:

根据上面的,t时刻的误差信号计算如下:

为了使误差不产生变化,可以强制令下式为1:

根据这个式子,可以得到:

这表示激活函数是线性的,常常的令fj(x) = x, wjj = 1.0,这样就获得常数误差流了,也叫做CEC(constant error carrousel)。
3.LSTM对模型的设计
到上面为止,提出的最简单的结构其实可以大致用这样一个图表述:

但是光是这样是不行的,因为存在输入输出处权值更新的冲突,所以加上了两道控制门,分别是input gate, output gate,来解决这个矛盾,图如下:

图中增加了两个控制门,所谓控制的意思就是计算cec的输入之前,乘以input gate的输出,计算cec的输出时,将其结果乘以output gate的输出,整个方框叫做block, 中间的小
圆圈是CEC, 里面是一条y = x的直线表示该神经元的激活函数是线性的,自连接的权重为1.0
4.LSTM训练的核心思路和推导
到此为止,我们大致有了这样的印象,作者还是比较“任性”地创造了这么一个模型,在理论上坚定了一个叫CEC的恒定误差流,在这个核心思想上又加入了一些Gate,在这里带来了另外一个问题,加入了Gate之后的结构,已经与之前的核心简单结构不符,在训练过程中,必然地在一个Block里面,误差会发生传播,弥散作用于不同的Gate,导致梯度被分散,可能依然会带来梯度消失的问题。如何解决?
作者给出的解决方法是:设计与结构相适应的训练算法,来保持CEC功能的完整。这里用到的想法是截断梯度回传(truncated backprop version of the LSTM algorithm)。
这个算法的思想是:为了保证在Memory cell的内部的误差不会衰减,所有到达这个Block的输入误差,包括(netcj , netinj, netoutj ) , 不会继续朝更前一个时间状态进行反向传播。
形象化地描述这个过程:当一个误差信号到达一个Block的output时(通过隐层和输出层的回传),首先被输出门的激活函数和导数 h’进行尺度变换(scaled), 之后成为了CEC状态的值往之前的时刻进行传递,当这个误差要通过Input gate和g离开这个某个时刻的Block的时候,它再次经过激活函数和g’的变换,然后此刻的误差在进入到前一个时间状态的Block之前(实际上按照算法的设计,这个误差根本不会从这里进入下一个Block),对与它链接的一些权重进行更新。具体的实现过程,来进行一下推导。
(1)截断梯度法的近似

简单解释一下,误差回传到 input / output gate 和一个Block的输入(netcj)之后,不会向上一个时刻回传误差,而只用来在这里更新各个部分的权值w。
根据上式的推导,可以得到的另外几个关键公式如下:

在Memory cell中的各个t时刻的误差,保持一致。

最后整个梳理一下误差回传的过程,误差通过输出层,分类器,隐层等进入某个时刻的Block之后,先将误差传递给了Output Gate和Memory Cell两个地方。
到达输出门的误差,用来更新了输出门的参数w,到达Memory Cell之后,误差经过两个路径,
1是通过这个cell向前一个时刻传递或者更前的时刻传递,
2是用来传递到input gate和block的输入,用来更新了相应的权值(注意!不会经过这里向前一个时刻传递误差)。
最关键最关键的问题再重复一遍就是,这个回传的算法,只通过中间的Memory Cell向更前的时刻传递误差。
5.近期LSTM的模型的改进


(注意这里角标顺序回归正常,从前到后)
与97年LSTM的原型想必,主要改动的几点:
1. 引入了Forget门,有些文献也叫做Keep Gate(其实这个叫法我觉得更好)。
2. 激活函数的选择有所改变,通常就是sigmoid和tanh。
3. 加入了Peephole,即Celll对各个Gate的链接。
4. 训练过程不再使用截断算法,而是用FULL BPTT+一些trick进行算法,且获得的更好效果。
具体的前向和后向推导如下:
- wij表示从神经元i到j的连接权重(注意这和很多论文的表示是反着的)
- 神经元的输入用a表示,输出用b表示
- 下标 ι, φ 和 ω分别表示input gate, forget gate,output gate
- c下标表示cell,从cell到 input, forget和output gate的peephole权重分别记做 wcι , wcφ and wcω
- Sc表示cell c的状态
- 控制门的激活函数用f表示,g,h分别表示cell的输入输出激活函数
- I表示输入层的神经元的个数,K是输出层的神经元个数,H是隐层cell的个数
前向的计算:

误差反传更新:

(以上的公式取自Alex的论文,我懒得从原文里截图了,借用下之前提到的博客里的图。)
这块的公式的推导,比原文里要简单的多,说白了就是链式法则的反复应用,我觉得想在原理上更深入的话这个反传的推导不妨试试。其实一点都不难。
6.LSTM的工作特性的研究
事实上,到目前为止,大部分的LSTM的模型和语言模型、手写体识别、序列生成、机器翻译、语音、视频分析等多种任务中取得了一些成功的应用,但是很少有人去研究到底是什么原因导致了这些情况的发生,以及哪些设计是切实有效的。
对各个门之间的状态,在字母级别的语言序列和语言模型中做了一系列实验,并且对RNN和GRU模型也做了对比实验。
这里简单说一下比较有趣的一点,如下,这篇文章的实验是用了《战争与和平》和LINUX的源码(!!!)两个数据集上做的。
作者非常惊喜地发现,LSTM的记忆单元中的某些Units有着令人惊喜的功能,比如它们可能会标志着段落的结束、或者引用内容,或者linux的源码中的一些条件语句的内容。
当然,大部分都是我们难以解释的一些隐层状态。

“The forget gates are its most criticalcomponents”
遗忘门,起到了最为关键的作用。(而LSTM原型中压根就没有遗忘门......)
另外这篇文章也提到了各个门的状态的一些统计信息,

大致情况可以这样表述,forget门倾向于为不激活状态(偏向0),即频繁忘记东西。
Input Gate倾向于通常出于打开的状态。
Output gate则有开有闭,基本平衡。
7.一些可能存在的问题
1. Theano LSTM 例程里的梯度回传算法,由于Theano自动求导的功能,在回传时候应该是采用的是FULL BPTT,这个是不是会带来一些如之前所说的问题?
答:这个问题我在之前其实已经说明了Alex的一些Trick的做法。仔细思考下,确实FULL BPTT带来的梯度的问题,由于Memory Cell功能的完整性,而被缓解了。也就是说误差回传的主力还是通过了Memory Cell而保持了下来。所以我们现在用的LSTM模型,依然有比较好的效果。
2. LSTM的Input、Output、Forget门之间的功能是不是其实有重复?有没有更简单的结构可以改进。
答:没错,例如已经出现的GRU (Gated Recurrent Unit)
8. 总结
两个关键问题:
1. 为什么具有记忆功能?
这个是在RNN就解决的问题,就是因为有递归效应,上一时刻隐层的状态参与到了这个时刻的计算过程中,直白一点呢的表述也就是选择和决策参考了上一次的状态。
2. 为什么LSTM记的时间长?
因为特意设计的结构中具有CEC的特点,误差向上一个上一个状态传递时几乎没有衰减,所以权值调整的时候,对于很长时间之前的状态带来的影响和结尾状态带来的影响可以同时发挥作用,最后训练出来的模型就具有较长时间范围内的记忆功能。
9.Keras实现
keras: 在构建LSTM模型时,使用变长序列的方法
众所周知,LSTM的一大优势就是其能够处理变长序列。而在使用keras搭建模型时,如果直接使用LSTM层作为网络输入的第一层,需要指定输入的大小。如果需要使用变长序列,那么,只需要在LSTM层前加一个Masking层,或者embedding层即可。
from keras.layers import Masking, Embeddingfrom keras.layers import LSTM model = Sequential() model.add(Masking(mask_value= -1,input_shape=(sequenceLength, 23*3,))) model.add(LSTM(100, dropout_W=0.2, dropout_U=0.2, input_shape=(sequenceLength, 23*3,)))使用方法:首先将序列转换为定长序列,如,选取一个序列最大长度,不足这个长度的序列补-1。然后在Masking层中mask_value中指定过滤字符。如上代码所示,序列中补的-1全部被过滤掉。
此外,embedding层也有过滤的功能,但与masking层不同的是,它只能过滤0,不能指定其他字符,并且因为是embedding层,它会将序列映射到一个固定维度的空间中。因此,如果诉求仅仅是让keras中LSTM能够处理边长序列,使用Masking层会比使用Embedding层更加适合。
- LSTM模型理论总结
- LSTM模型理论总结(产生、发展和性能等)
- LSTM模型
- 自然语言处理模型之GRU和LSTM网络模型总结
- LSTM RNN 理论
- LSTM模型概述
- LSTM模型(转载)
- GRU与LSTM总结
- lstm(三) 模型压缩lstmp
- tensorflow RNN LSTM语言模型
- 压缩感知理论模型
- 图形学理论 光照模型
- 灰色理论预测模型
- 生产者消费者理论模型
- CAP理论-BASE模型
- RNN, LSTM, GRU 公式总结
- 架构-LSTM理解总结(1)
- Siamese LSTM解决句子相似度以及扩展(理论篇)
- ERROR TIMS-4236:“invalid value ‘20171024_02’ for bundle_version” at SoftwareAssets
- 无限轮播
- erlang 文件读写操作
- Android架构之Activity和Fragment复杂嵌套
- Linux中的中断处理机制
- LSTM模型理论总结
- TCP连接的状态详解以及故障排查
- cocos2dx-3.4环境搭建及apk发布调试之谜海归巢
- eclipse中给类制定注释模板
- Struts2---自定义拦截器
- JavaWeb学习心得之Tomcat服务器(一)
- 技术团队开发流程
- 用OpenCV的GaussianBlur函数做高斯滤波
- Spark官网资料学习网址


