[DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
来源:互联网 发布:淘宝筛选发货地 编辑:程序博客网 时间:2024/05/16 12:44
Optimization Algorithms优化算法
觉得有用的话,欢迎一起讨论相互学习~Follow Me
2.6 动量梯度下降法(Momentum)
- 另一种成本函数优化算法,优化速度一般快于标准的梯度下降算法.
基本思想:计算梯度的指数加权平均数并利用该梯度更新你的权重
假设图中是你的成本函数,你需要优化你的成本函数函数形象如图所示.其中红点所示就是你的最低点.使用常规的梯度下降方法会有摆动这种波动减缓了你训练模型的速度,不利于使用较大的学习率,如果学习率使用过大则可能会偏离函数的范围.为了避免摆动过大,你需要选择较小的学习率.

- 而是用Momentum梯度下降法,我们可以在纵向减小摆动的幅度在横向上加快训练的步长.
基本公式
- 在纵轴方向上,你希望放慢一点,平均过程中,正负数相互抵消,平均值接近于零.
- 横轴方向所有的微分都指向于横轴方向,所以横轴的平均值仍较大.
- 横轴方向运动更快,纵轴方向摆动幅度变小.
- 两个超参数
α控制学习率,β控制指数加权平均数,β最常用的值是0.9 - 此处的指数加权平均算法不一定要使用带修正偏差,因为经过10次迭代的平均值已经超过了算法的初始阶段,所以不会受算法初始阶段的影响.
2.7 RMSprop(均方根)
RMSprop (root mean square prop),也可以加速梯度下降.

- 对于梯度下降,横轴方向正在前进,但是纵轴会有大幅度的波动.我们现将横轴代表参数W,纵轴代表参数b.横轴也可以代表
W[1],W[2],W[3]...W[n] ,但是为了便于理解,我们将其称之为b和W. - 公式
Sdw=βSdw+(1−β)(dw)2 接着RMSprop会这样更新参数值Sdb=βSdb+(1−β)(db)2 W=W−αdwSdw−−−√ b=b−αdbSdb−−−√ - w的在横轴上变化变化率很小,所以dw的值十分小,所以
Sdw 也小,而b在纵轴上波动很大,所以斜率在b方向上特别大.所以这些微分中,db较大,dw较小.这样W除数是一个较小的数,总体来说,W的变化很大.而b的除数是一个较大的数,这样b的更新就会被减缓.纵向的变化相对平缓. - 注意:这里的W和b标记只是为了方便展示,在实际中这是一个高维的空间,很有可能垂直方向上是W1,W2,W5..的合集而水平方向上是W3,W4,W6…的合集.
实际使用中公式建议为:
W=W−αdwSdw+ϵ−−−−−−√ 为了保证实际使用过程中分母不会为0.b=b−αdbSdb+ϵ−−−−−−√ 主要目的是为了减缓参数下降时的摆动,并允许你使用一个更大的学习率
α ,从而加快你的算法速率.
2.8 Adam算法
Adam 算法基本原理是将Momentum和RMSprop结合在一起.
算法原理

超参数取值
- 学习率
α 十分重要,也经常需要调试. β1 常用的缺省值是0.9β2 Adam的发明者推荐使用的数值是0.999ϵ的取值没有那么重要,Adam论文的作者建议为ϵ=10−8 - 在实际使用中,
β1,β2,ϵ都是使用的推荐的缺省值,一般调整的都是学习率α - Adam: Adaptive Moment Estimation(自适应估计时刻)
2.9 学习率衰减(learning rate decay)
- 加快学习算法的一个办法就是随时间慢慢减少学习率,我们将之称为学习率衰减(learning rate decay)
概括
- 假设你要使用mini-batch梯度下降法,mini-batch数量不大,大概64或者128个样本,但是在迭代过程中会有噪音,下降朝向这里的最小值,但是不会精确的收敛,所以你的算法最后在附近摆动.,并不会真正的收敛.因为你使用的是固定的
α ,在不同的mini-batch中有杂音,致使其不能精确的收敛.
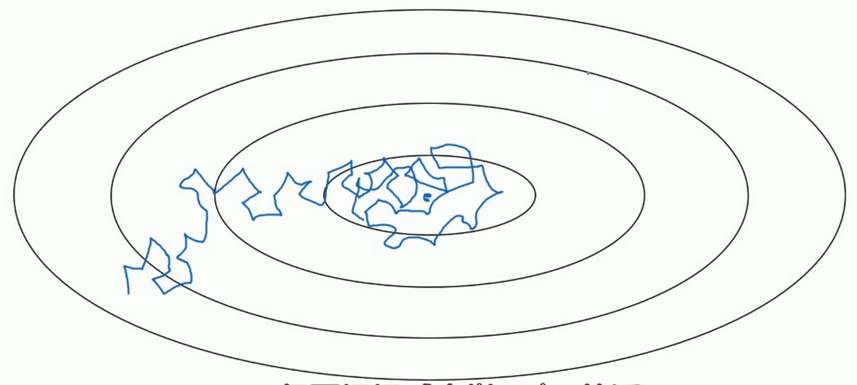
- 但如果能慢慢减少学习率
α 的话,在初期的时候,你的学习率还比较大,能够学习的很快,但是随着α 变小,你的步伐也会变慢变小.所以最后的曲线在最小值附近的一小块区域里摆动.所以慢慢减少α 的本质在于在学习初期,你能承受较大的步伐, 但当开始收敛的时候,小一些的学习率能让你的步伐小一些.
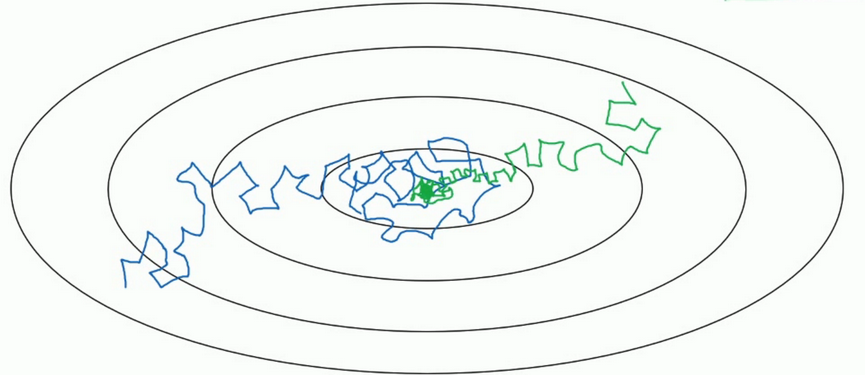
细节
- 一个epoch表示要遍历一次数据,即就算有多个mini-batch,但是一定要遍历所有数据一次,才叫做一个epoch.
- 学习率
α,其中α0表示初始学习率,decay−rate是一个新引入的超参数 :α=11+decay−rate∗epoch−num∗α0

其他学习率衰减公式
指数衰减
阅读全文
1 0
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.1_2.2_mini-batch梯度下降法
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.3_2.5_带修正偏差的指数加权平均
- CS231n作业笔记2.3:优化算法Momentum, RMSProp, Adam
- CS231n课程笔记6.1:优化迭代算法之SGD,Momentum,Netsterov Momentum,AdaGrad,RMSprop,Adam
- 深度学习之momentum,RMSprop,Adam优化算法
- 优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
- 优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
- 转:深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
- 【deeplearning.ai笔记第二课】2.2 优化算法(动量梯度下降,RMSprop,adam)
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.9_归一化normalization
- 神经网络优化算法如何选择Adam,SGD
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
- 梯度优化算法Adam
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.10_1.12/梯度消失/梯度爆炸/权重初始化
- 类中成员函数的实现,放在类块里和外部实现的区别
- Struts2概述
- ubuntu下qt无法加载qmldesigner qmlprofiler welcome
- react_basic(2)
- Struts2的数据校验
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
- Loadrunner windows socket 协议 1
- SMBconnection类使用
- unit15
- 让Android的webview支持H5的图片上传,无需原生开发功能
- CentOS7 软件源
- 基础练习 数列特征
- 学习使用C++封装DLL并调用
- 安装Linux操作系统(1)


