MIT算法导论公开课第八讲全域哈希和完全哈希
来源:互联网 发布:怎么自己注册域名 编辑:程序博客网 时间:2024/06/13 12:12
全域哈希
对于任意哈希函数而言,都存在一个不好的健集,使得所有的健都会哈希到同一个槽里去,那么如何解决这种情况呢?如何防止对某个键集永远有较差的表现?如何防止竞争对手使用这个键集来降低你的性能表现? 一个词解决这个问题 —— 随机!
全域哈希的方法就是随机选择一个哈希函数H(当然不是每次操作都选择一个哈希函数,而是构建一个哈希表的时候随机选一个,选定之后这个哈希表的所有操作都是基于这个哈希函数,这种方法可以防止竞争对手别有用心的设计一个键集,同时也能避免某些键集永远会导致较差的性能,如果是,那么重新建一个表就行!)
定义:设U为键的全域,H是哈希的有限集,H里面的每个哈希函数h将集合U映射到哈希表的m个位置上,如果哈希表满足:对于U里面的两个值x,y x≠y {h∈H:h(x)=h(y)}=|H|/m,那么H就是全域的。
|H|的意思是指全域哈希函数的个数,那么从里面任意取一个函数h,这个函数把x和y哈希到同一个位置的概率就是1/m,也就是说,这些函数都是均匀函数。
定理:用h来将任意n个键哈希到大小为m的表T里,使用链表法解决冲突,如果关键字k不在表中,则关键字k被哈希到其中链表的长度至多为α。
证明:设




则,
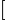


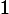
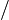





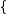
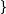

最后结果就等于(n-1)/m。所以总共与x可能有冲突的建小于α个。
完全哈希
当键值是static(即固定不变)的时候,也就是只考虑查询的情况。我们可以设计方案使得最差情况下的查询性能也很出色,这就是完全哈希。
完全哈希的思想就是采用两级的框架,每一级上都用全域哈希:

完美哈希的结构如上图。具体来说,第一级和带链表的哈希非常的相似,只是第一级发生冲突后后面接的不是链表,而是一个新的哈希表。
为了保证不冲突,每个二级哈希表的数量是第一级映射到这个槽中元素个数的平方,这样可以保证整个哈希表非常的稀疏。下面给出一个定理,能更清楚的看到设置m=n^2的作用
定理:设H是一类全域哈希函数,哈希表的槽数m=n^2. 那么,如果我们用一个随机
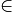

证明:根据全域哈希的定义,对任意选出的哈希函数h,表中2个给定keys冲突的概率是1/m,即1/n^2
且总共有 


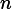


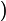
 /
/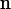

证明:主要用到马尔科夫不等式:
Pr{X≥t}≤E[x]/t
利用这个不等式,让t=1,即可得到冲突次数大于1的概率最多为1/2
参考:
算法导论
http://www.cnblogs.com/soyscut/p/3396216.html?utm_source=tuicool&utm_medium=referral
http://www.guokr.com/blog/483599/
- MIT算法导论公开课第八讲全域哈希和完全哈希
- 【算法导论】第八课 全域哈希 完美哈希
- 全域哈希和完全哈希
- MIT算法导论公开课第七讲哈希表
- MIT公开课《算法导论》笔记一:算法分析
- 算法导论MIT第一讲
- 算法导论公开课对应章节(来自MIT)
- 浅析全域哈希和完全哈希(c语言实现)
- 全域哈希(Universial Hashing)和完全哈希(Perfect Hashing)
- MIT算法导论-第一讲-算法分析
- MIT算法导论-第三讲-分治
- MIT算法导论-第四讲-快速排序
- MIT公开课---计算机科学及编程导论
- MIT公开课《算法导论》笔记二:渐近符号、递归及解法
- MIT算法导论——第一讲.Analysis of algorithm
- MIT算法导论——第二讲.Solving Recurrence
- MIT算法导论——第四讲.Quicksort
- MIT算法导论——第五讲.Linear Time Sort
- mapreduce的timeout参数设置
- SpringMVC与Struts2区别与比较总结
- tf.summary.FileWriter
- 修改数据库建表的时候primery key的默认值
- 项目中遇到的问题(新)
- MIT算法导论公开课第八讲全域哈希和完全哈希
- Intellij IDEA 设置自动生成 serialVersionUID
- 3的幂的和-----51Nod//快速幂
- Component.GetComponentsInChildren
- 数据结构|用栈实现十进制转换成二进制(实验3.5)
- python 爬取360看看的电影
- Android Studio不能走到断点的原因?
- Java 多线程同步的五种方法
- Java常用集合类及其区别


