10月14日,2017杭州云栖大会·阿里云大数据计算服务(MaxCompute)专场,阿里云技术专家路璐带来《MaxCompute基于BigBench标准的最新测试进展》分享。

在11日的主论坛上,MaxCompute做了敢为人先、引领潮流BigBench On MaxCompute2.0的重磅发布,意味着MaxCompute成为第一个做到100TB数据规模的BigBench,并且在100T数据规模的Qpm达到7830Qpm,成为第一个达到7000分的大数据引擎。同时MaxCompute也是第一个公有云服务的BigBench Benchmark,在性价比上具有很大的优势,并给出了几种性价比计算方式:其中预付费3年的性价比达到371美元per Qpm;预付费1月的性价比达到12.3美元per Qpm;按需后付费的性价比达到2.1美元per Qpm。

这也就是说从规模、性能、性价比角度,MaxCompute都达到了业界领先水平。本文正是为大家解读这组数据。
TPCx-BB简介
BigBench实际上就是TPCx-BB的前身,它于2016年2月被TPC委员会接受以后被命名为TPCx-BB,在此之前叫BigBench。
TPCx-BB是业界领先的基于端到端的大数据分析领域应用级测试基准,由Intel领衔发起,并作为主要开发和大力推广。这里有两个关键词,第一个是端到端的,作为大数据从业者,我们在选择大数据引擎时,性能只是其中一方面,服务等级协议(SLA)和总体拥有成本(TCO)也是我们考量的一方面,甚至是更重要的一方面。传统的Benchmark可能只关注性能,但BigBench作为一款端到端的测试基准,它不仅仅考量大数据引擎的性能,同时参考了大数据工业领域的应用特征,引入了SLA和TCO的衡量标准。
第二个关键词是应用级,现在大数据领域的应用种类繁多,很难用一种应用满足所有的业务需求,同时也很难衡量出大数据平台的真实情况。TPCx-BB模拟了一个真实的线下、线上销售场景的完整应用,应用类型包含SQL、MapReduce、MachineLearning、Streaming等,并且各种应用类型之间的比例与实际情况相近,所以是一款应用级的测试基准。
基于以上特征,TPCx-BB提出了一个完整的软硬件评估标准,并且针对大数据业务类型和应用特征,可以在不同的规模上进行评测。目前官方最大数据规模是10TB,最佳性能是1491 BBQpm,最高性价比的589 美元per Qpm。
TPCx-BB作业特征分布
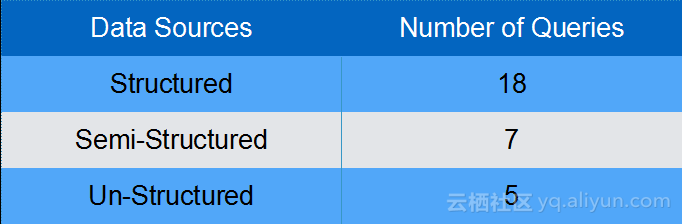
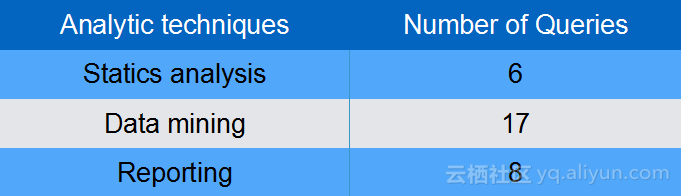
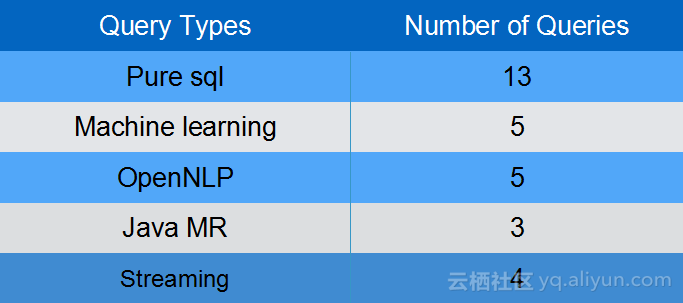
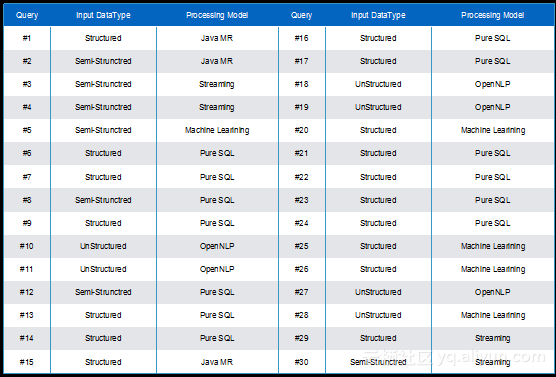
上图展示了TPCx-BB的作业特征分布,TPCx-BB一共包含30个作业:
从源数据分析,包含了18个结构化作业、7个半结构化作业和5个非结构化作业;
从作业类型分析,包含6个统计分析作业,17个数据挖掘作业和8个报表类作业;
从应用类型分析,包含13个 纯sql,5个machine learning的作业,5个OpenNLP作业,3个JavaMr作业和4个streamling。
从以上分类可以看出,TPCx-BB包含的作业类型十分全面,基本涵盖了大数据领域的一些常见应用,并且应用间的比例与实际情况相当吻合。
TPCx-BB性能评估标准
TPCx-BB性能评估标准有两个,一是根据软硬件性能评估,二是根据软硬件性价比评估。
根据软硬件性能评估(SLA)是指通过BBQpm@SF评估性能,它涵盖数据规模、数据导入的性能,Power测试阶段,Throughput测试阶段。BBQpm@SF的公式如下,其中SF(scale factor)表示基准测试数据规模大小,以G为单位,比如1000代表1T,M代表基准测试运行的作业数量,完整的BBQpm包含30个query。
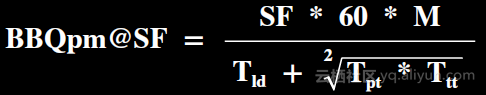
Load测试阶段:测试数据导入。Load测试阶段通过数据导入的时间衡量,因为相对作业执行,这部分对大数据系统相对不那么重要,所以在计算时加上了0.1的系数。
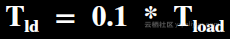
Power测试阶段:单个查询流顺序执行30个查询语句,衡量方式是计算这些查询语句的几何平均执行时间,所以在Power测试阶段大作业和小作业的权重是一样的,这就避免了针对性优化某一个大作业大幅提升成绩的问题。
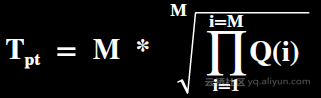
Throughput测试阶段:多个并发查询流并发执行查询语句,衡量方式是整体执行时间除以并发数,所以在Throughput测试阶段,大作业占的比重会更大。
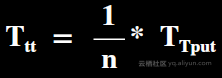
根据软硬件性价比评估(TCO)也就是被评估系统的总价格除以BBQpm,这样就避免了用大量硬件获取更高的BBQpm,真实反映出软硬件的综合实力。
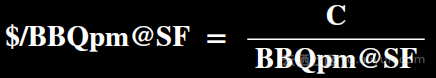
C:被评估SUT的总价格
BigBench on MaxCompute软件栈
作为一个大数据分析领域应用级测试基准,BigBench包含了多种语义类型,也就是说一个大数据分析平台至少应该支持BigBench的所有应用类型,才能满足用户数据分析的基本需求。BigBench on MaxCompute基于BigBench进行修改,兼容所有语义,只是对一些API做了适配。这也正说明MaxCompute可以完全支持BigBench,作为大数据分析平台具有功能完备性。
从详细的软件栈看,MaxCompute平台提供了Hive兼容模式,完全兼容Hive的所有数据类型和SQL语法;MaxCompute提供Tunnel数据导入导出工具,可以将不同平台数据导入到MaxCompute中;机器学习方面,MaxCompute与阿里巴巴一站式机器学习平台PAI数据打通,可以无缝接入。
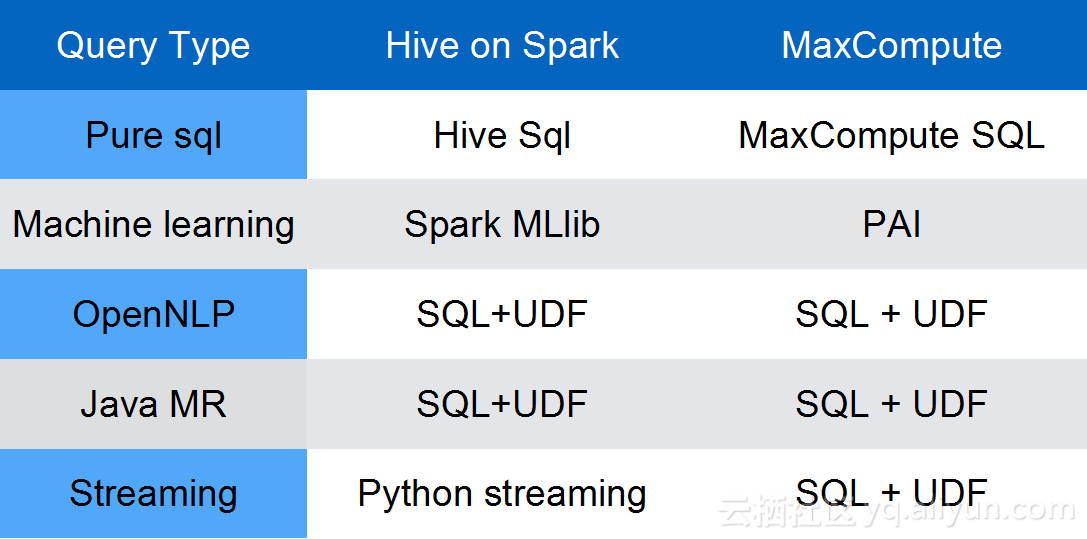
BigBench的默认大数据引擎是Hive on Spark,上表还提供了Hive on Spark与MaxCompute的软件栈对比,可以看出将BigBench从Hive on Spark迁移到MaxCompute的对应关系,说明将业务从Hive on Spark迁移到MaxCompute上的Gap不是很大。
BigBench on MaxCompute结果分析
数据规模达到100TB,性能达到7830Qpm,性价比达到$2.1/Qpm,以及第一个公共云服务Benchmark。BigBench on MaxCompute在数据规模、性能和性价比上能够取得这样的成绩,主要跟以下几个方面相关。
首先MaxCompute本身具有的海量数据处理能力。MaxCompute的总数据量已经达到EB级,并且在高速增长中。可以说MaxCompute的大数据能力是在海量数据中锤炼出来的。MaxCompute基于阿里云自主研发的Apsara分布式操作系统,单集群机器规模达到万台,具有业界领先的能力。其中最重要的组件是Fuxi和Pangu,Fuxi是飞天的分布式资源管理和调度系统,在2015年曾经打破GraySort世界纪录,Pangu是大规模分布式文件系统,可以支持10亿+文件条目。
MaxCompute高速增长的业务需求也带来了性能优化的压力和动力,因此在MaxCompute新一代执行引擎中,对Compiler、Optimizer、Runtime等模块进行了深度优化,比如使用range partition做distribute order by,对部分Bigbench作业的性能提升超过100%;使用auto mapjoin对join进行优化,使用shuffle remove减少不必要的stage等;另外我们与Intel有软硬件深度优化的全面合作,充分发挥至强R可扩展处理器架构优势。
同时,BigBench on MaxCompute还是第一个公共云服务Benchmark,包含完整的TCO和软硬件运维服务。事实上按照传统的购买软硬件的方式组建可以运行100T BigBench的集群是一个非常庞大的工程,可能需要几个团队长达几个月的合作才能完成。在公共云上运行100TB BigBench只需要两天的时间。云栖大会后的一个月内将会开放这部分资源给用户,让用户可以在两天的时间内在MaxCompute上完整运行100TB的BigBench。
除了获取方便,公共云服务的另一巨大优势是成本,公有云计价规则灵活,可以按需后付费、按月预付费、按年预付费等。所谓按需后付费是根据实际跑的作业收费,100TB BigBench在MaxCompute上的性价比达到2.1美元Per Qpm。预付费模式是提前预定好机器资源,传统的购买机器一般会有3年或者几年的生命周期,也就是说需要一次性购买三年以上的硬件。而公共云的预付费模式最短可以只购买一个月。实际上即使购买3年的硬件,在MaxCompute购买同样的硬件资源也有一定的价格优势。不过一般没有人会这样做,同样性能的硬件成本会逐年下降,按照现在的价格购买未来几年的硬件是不明智的。公共云按月、按年购买的方式可以避免这种不明智,而公共云平台大量硬件资源可以将这部分成本分摊掉。
测试开放
目前团队即将开放一个月的测试期,免费提供MaxCompute测试资源,让用户可以在2天内完整试跑100TB的BigBench。具体的Test kit和操作指南都已开源提供钉钉联系。
原文链接


