浅析java内存模型--JMM(Java Memory Model)
来源:互联网 发布:故宫博物馆淘宝 编辑:程序博客网 时间:2024/06/16 04:10
在并发编程中,多个线程之间采取什么机制进行通信(信息交换),什么机制进行数据的同步?
在Java语言中,采用的是共享内存模型来实现多线程之间的信息交换和数据同步的。
线程之间通过共享程序公共的状态,通过读-写内存中公共状态的方式来进行隐式的通信。同步指的是程序在控制多个线程之间执行程序的相对顺序的机制,在共享内存模型中,同步是显式的,程序员必须显式指定某个方法/代码块需要在多线程之间互斥执行。
在说Java内存模型之前,我们先说一下Java的内存结构,也就是运行时的数据区域:
Java虚拟机在执行Java程序的过程中,会把它管理的内存划分为几个不同的数据区域,这些区域都有各自的用途、创建时间、销毁时间。
Java运行时数据区分为下面几个内存区域:
1.PC寄存器/程序计数器:
严格来说是一个数据结构,用于保存当前正在执行的程序的内存地址,由于Java是支持多线程执行的,所以程序执行的轨迹不可能一直都是线性执行。当有多个线程交叉执行时,被中断的线程的程序当前执行到哪条内存地址必然要保存下来,以便用于被中断的线程恢复执行时再按照被中断时的指令地址继续执行下去。为了线程切换后能恢复到正确的执行位置,每个线程都需要有一个独立的程序计数器,各个线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存,这在某种程度上有点类似于“ThreadLocal”,是线程安全的。
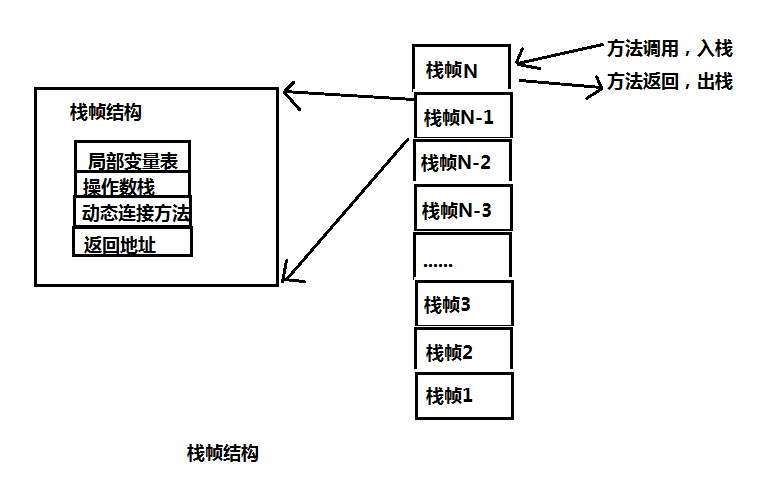
2.Java栈 Java Stack:
Java栈总是与线程关联在一起的,每当创建一个线程,JVM就会为该线程创建对应的Java栈,在这个Java栈中又会包含多个栈帧(Stack Frame),这些栈帧是与每个方法关联起来的,每运行一个方法就创建一个栈帧,每个栈帧会含有一些局部变量、操作栈和方法返回值等信息。每当一个方法执行完成时,该栈帧就会弹出栈帧的元素作为这个方法的返回值,并且清除这个栈帧,Java栈的栈顶的栈帧就是当前正在执行的活动栈,也就是当前正在执行的方法,PC寄存器也会指向该地址。只有这个活动的栈帧的本地变量可以被操作栈使用,当在这个栈帧中调用另外一个方法时,与之对应的一个新的栈帧被创建,这个新创建的栈帧被放到Java栈的栈顶,变为当前的活动栈。同样现在只有这个栈的本地变量才能被使用,当这个栈帧中所有指令都完成时,这个栈帧被移除Java栈,刚才的那个栈帧变为活动栈帧,前面栈帧的返回值变为这个栈帧的操作栈的一个操作数。
由于Java栈是与线程对应起来的,Java栈数据不是线程共有的,所以不需要关心其数据一致性,也不会存在同步锁的问题。
在Java虚拟机规范中,对这个区域规定了两种异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;如果虚拟机可以动态扩展,如果扩展时无法申请到足够的内存,就会抛出OutOfMemoryError异常。在Hot Spot虚拟机中,可以使用-Xss参数来设置栈的大小。栈的大小直接决定了函数调用的可达深度。
3.堆 Heap:
堆是JVM所管理的内存中国最大的一块,是被所有Java线程锁共享的,不是线程安全的,在JVM启动时创建。堆是存储Java对象的地方,这一点Java虚拟机规范中描述是:所有的对象实例以及数组都要在堆上分配。Java堆是GC管理的主要区域,从内存回收的角度来看,由于现在GC基本都采用分代收集算法,所以Java堆还可以细分为:新生代和老年代;新生代再细致一点有Eden空间、From Survivor空间、To Survivor空间等。
4.方法区Method Area:
方法区存放了要加载的类的信息(名称、修饰符等)、类中的静态常量、类中定义为final类型的常量、类中的Field信息、类中的方法信息,当在程序中通过Class对象的getName.isInterface等方法来获取信息时,这些数据都来源于方法区。方法区是被Java线程锁共享的,不像Java堆中其他部分一样会频繁被GC回收,它存储的信息相对比较稳定,在一定条件下会被GC,当方法区要使用的内存超过其允许的大小时,会抛出OutOfMemory的错误信息。方法区也是堆中的一部分,就是我们通常所说的Java堆中的永久区 Permanet Generation,大小可以通过参数来设置,可以通过-XX:PermSize指定初始值,-XX:MaxPermSize指定最大值。
5.常量池Constant Pool:
常量池本身是方法区中的一个数据结构。常量池中存储了如字符串、final变量值、类名和方法名常量。常量池在编译期间就被确定,并保存在已编译的.class文件中。一般分为两类:字面量和应用量。字面量就是字符串、final变量等。类名和方法名属于引用量。引用量最常见的是在调用方法的时候,根据方法名找到方法的引用,并以此定为到函数体进行函数代码的执行。引用量包含:类和接口的权限定名、字段的名称和描述符,方法的名称和描述符。
6.本地方法栈Native Method Stack:
本地方法栈和Java栈所发挥的作用非常相似,区别不过是Java栈为JVM执行Java方法服务,而本地方法栈为JVM执行Native方法服务。本地方法栈也会抛出StackOverflowError和OutOfMemoryError异常。
主内存和工作内存:
Java内存模型的主要目标是定义程序中各个变量的访问规则,即在JVM中将变量存储到内存和从内存中取出变量这样的底层细节。此处的变量与Java编程里面的变量有所不同步,它包含了实例字段、静态字段和构成数组对象的元素,但不包含局部变量和方法参数,因为后者是线程私有的,不会共享,当然不存在数据竞争问题(如果局部变量是一个reference引用类型,它引用的对象在Java堆中可被各个线程共享,但是reference引用本身在Java栈的局部变量表中,是线程私有的)。为了获得较高的执行效能,Java内存模型并没有限制执行引起使用处理器的特定寄存器或者缓存来和主内存进行交互,也没有限制即时编译器进行调整代码执行顺序这类优化措施。
JMM规定了所有的变量都存储在主内存(Main Memory)中。每个线程还有自己的工作内存(Working Memory),线程的工作内存中保存了该线程使用到的变量的主内存的副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量(volatile变量仍然有工作内存的拷贝,但是由于它特殊的操作顺序性规定,所以看起来如同直接在主内存中读写访问一般)。不同的线程之间也无法直接访问对方工作内存中的变量,线程之间值的传递都需要通过主内存来完成。
线程1和线程2要想进行数据的交换一般要经历下面的步骤:
1.线程1把工作内存1中的更新过的共享变量刷新到主内存中去。
2.线程2到主内存中去读取线程1刷新过的共享变量,然后copy一份到工作内存2中去。
Java内存模型是围绕着并发编程中原子性、可见性、有序性这三个特征来建立的,那我们依次看一下这三个特征:
原子性(Atomicity):一个操作不能被打断,要么全部执行完毕,要么不执行。在这点上有点类似于事务操作,要么全部执行成功,要么回退到执行该操作之前的状态。
基本类型数据的访问大都是原子操作,long 和double类型的变量是64位,但是在32位JVM中,32位的JVM会将64位数据的读写操作分为2次32位的读写操作来进行,这就导致了long、double类型的变量在32位虚拟机中是非原子操作,数据有可能会被破坏,也就意味着多个线程在并发访问的时候是线程非安全的。
下面我们来演示这个32位JVM下,对64位long类型的数据的访问的问题:

1 public class NotAtomicity { 2 //静态变量t 3 public static long t = 0; 4 //静态变量t的get方法 5 public static long getT() { 6 return t; 7 } 8 //静态变量t的set方法 9 public static void setT(long t) {10 NotAtomicity.t = t;11 }12 //改变变量t的线程13 public static class ChangeT implements Runnable{14 private long to;15 public ChangeT(long to) {16 this.to = to;17 }18 public void run() {19 //不断的将long变量设值到 t中20 while (true) {21 NotAtomicity.setT(to);22 //将当前线程的执行时间片段让出去,以便由线程调度机制重新决定哪个线程可以执行23 Thread.yield();24 }25 }26 }27 //读取变量t的线程,若读取的值和设置的值不一致,说明变量t的数据被破坏了,即线程不安全28 public static class ReadT implements Runnable{29 30 public void run() {31 //不断的读取NotAtomicity的t的值32 while (true) {33 long tmp = NotAtomicity.getT();34 //比较是否是自己设值的其中一个35 if (tmp != 100L && tmp != 200L && tmp != -300L && tmp != -400L) {36 //程序若执行到这里,说明long类型变量t,其数据已经被破坏了37 System.out.println(tmp);38 }39 ////将当前线程的执行时间片段让出去,以便由线程调度机制重新决定哪个线程可以执行40 Thread.yield();41 }42 }43 }44 public static void main(String[] args) {45 new Thread(new ChangeT(100L)).start();46 new Thread(new ChangeT(200L)).start();47 new Thread(new ChangeT(-300L)).start();48 new Thread(new ChangeT(-400L)).start();49 new Thread(new ReadT()).start();50 }51 }
我们创建了4个线程来对long类型的变量t进行赋值,赋值分别为100,200,-300,-400,有一个线程负责读取变量t,如果正常的话,读取到的t的值应该是我们赋值中的一个,但是在32的JVM中,事情会出乎预料。如果程序正常的话,我们控制台不会有任何的输出,可实际上,程序一运行,控制台就输出了下面的信息:
-4294967096
4294966896
-4294967096
-4294967096
4294966896
之所以会出现上面的情况,是因为在32位JVM中,64位的long数据的读和写都不是原子操作,即不具有原子性,并发的时候相互干扰了。
32位的JVM中,要想保证对long、double类型数据的操作的原子性,可以对访问该数据的方法进行同步,就像下面的:
1 public class Atomicity { 2 //静态变量t 3 public static long t = 0; 4 //静态变量t的get方法,同步方法 5 public synchronized static long getT() { 6 return t; 7 } 8 //静态变量t的set方法,同步方法 9 public synchronized static void setT(long t) {10 Atomicity.t = t;11 }12 //改变变量t的线程13 public static class ChangeT implements Runnable{14 private long to;15 public ChangeT(long to) {16 this.to = to;17 }18 public void run() {19 //不断的将long变量设值到 t中20 while (true) {21 Atomicity.setT(to);22 //将当前线程的执行时间片段让出去,以便由线程调度机制重新决定哪个线程可以执行23 Thread.yield();24 }25 }26 }27 //读取变量t的线程,若读取的值和设置的值不一致,说明变量t的数据被破坏了,即线程不安全28 public static class ReadT implements Runnable{29 30 public void run() {31 //不断的读取NotAtomicity的t的值32 while (true) {33 long tmp = Atomicity.getT();34 //比较是否是自己设值的其中一个35 if (tmp != 100L && tmp != 200L && tmp != -300L && tmp != -400L) {36 //程序若执行到这里,说明long类型变量t,其数据已经被破坏了37 System.out.println(tmp);38 }39 ////将当前线程的执行时间片段让出去,以便由线程调度机制重新决定哪个线程可以执行40 Thread.yield();41 }42 }43 }44 public static void main(String[] args) {45 new Thread(new ChangeT(100L)).start();46 new Thread(new ChangeT(200L)).start();47 new Thread(new ChangeT(-300L)).start();48 new Thread(new ChangeT(-400L)).start();49 new Thread(new ReadT()).start();50 }51 }
这样做的话,可以保证对64位数据操作的原子性。
可见性:一个线程对共享变量做了修改之后,其他的线程立即能够看到(感知到)该变量这种修改(变化)。
Java内存模型是通过将在工作内存中的变量修改后的值同步到主内存,在读取变量前从主内存刷新最新值到工作内存中,这种依赖主内存的方式来实现可见性的。
无论是普通变量还是volatile变量都是如此,区别在于:volatile的特殊规则保证了volatile变量值修改后的新值立刻同步到主内存,每次使用volatile变量前立即从主内存中刷新,因此volatile保证了多线程之间的操作变量的可见性,而普通变量则不能保证这一点。
除了volatile关键字能实现可见性之外,还有synchronized,Lock,final也是可以的。
使用synchronized关键字,在同步方法/同步块开始时(Monitor Enter),使用共享变量时会从主内存中刷新变量值到工作内存中(即从主内存中读取最新值到线程私有的工作内存中),在同步方法/同步块结束时(Monitor Exit),会将工作内存中的变量值同步到主内存中去(即将线程私有的工作内存中的值写入到主内存进行同步)。
使用Lock接口的最常用的实现ReentrantLock(重入锁)来实现可见性:当我们在方法的开始位置执行lock.lock()方法,这和synchronized开始位置(Monitor Enter)有相同的语义,即使用共享变量时会从主内存中刷新变量值到工作内存中(即从主内存中读取最新值到线程私有的工作内存中),在方法的最后finally块里执行lock.unlock()方法,和synchronized结束位置(Monitor Exit)有相同的语义,即会将工作内存中的变量值同步到主内存中去(即将线程私有的工作内存中的值写入到主内存进行同步)。
final关键字的可见性是指:被final修饰的变量,在构造函数数一旦初始化完成,并且在构造函数中并没有把“this”的引用传递出去(“this”引用逃逸是很危险的,其他的线程很可能通过该引用访问到只“初始化一半”的对象),那么其他线程就可以看到final变量的值。
有序性:对于一个线程的代码而言,我们总是以为代码的执行是从前往后的,依次执行的。这么说不能说完全不对,在单线程程序里,确实会这样执行;但是在多线程并发时,程序的执行就有可能出现乱序。用一句话可以总结为:在本线程内观察,操作都是有序的;如果在一个线程中观察另外一个线程,所有的操作都是无序的。前半句是指“线程内表现为串行语义(WithIn Thread As-if-Serial Semantics)”,后半句是指“指令重排”现象和“工作内存和主内存同步延迟”现象。
Java提供了两个关键字volatile和synchronized来保证多线程之间操作的有序性,volatile关键字本身通过加入内存屏障来禁止指令的重排序,而synchronized关键字通过一个变量在同一时间只允许有一个线程对其进行加锁的规则来实现,
在单线程程序中,不会发生“指令重排”和“工作内存和主内存同步延迟”现象,只在多线程程序中出现。
happens-before原则:
Java内存模型中定义的两项操作之间的次序关系,如果说操作A先行发生于操作B,操作A产生的影响能被操作B观察到,“影响”包含了修改了内存中共享变量的值、发送了消息、调用了方法等。
下面是Java内存模型下一些”天然的“happens-before关系,这些happens-before关系无须任何同步器协助就已经存在,可以在编码中直接使用。如果两个操作之间的关系不在此列,并且无法从下列规则推导出来的话,它们就没有顺序性保障,虚拟机可以对它们进行随意地重排序。
a.程序次序规则(Pragram Order Rule):在一个线程内,按照程序代码顺序,书写在前面的操作先行发生于书写在后面的操作。准确地说应该是控制流顺序而不是程序代码顺序,因为要考虑分支、循环结构。
b.管程锁定规则(Monitor Lock Rule):一个unlock操作先行发生于后面对同一个锁的lock操作。这里必须强调的是同一个锁,而”后面“是指时间上的先后顺序。
c.volatile变量规则(Volatile Variable Rule):对一个volatile变量的写操作先行发生于后面对这个变量的读取操作,这里的”后面“同样指时间上的先后顺序。
d.线程启动规则(Thread Start Rule):Thread对象的start()方法先行发生于此线程的每一个动作。
e.线程终于规则(Thread Termination Rule):线程中的所有操作都先行发生于对此线程的终止检测,我们可以通过Thread.join()方法结束,Thread.isAlive()的返回值等作段检测到线程已经终止执行。
f.线程中断规则(Thread Interruption Rule):对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测是否有中断发生。
g.对象终结规则(Finalizer Rule):一个对象初始化完成(构造方法执行完成)先行发生于它的finalize()方法的开始。
g.传递性(Transitivity):如果操作A先行发生于操作B,操作B先行发生于操作C,那就可以得出操作A先行发生于操作C的结论。
一个操作”时间上的先发生“不代表这个操作会是”先行发生“,那如果一个操作”先行发生“是否就能推导出这个操作必定是”时间上的先发生 “呢?也是不成立的,一个典型的例子就是指令重排序。所以时间上的先后顺序与happens-before原则之间基本没有什么关系,所以衡量并发安全问题一切必须以happens-before 原则为准。
-----------------------------------------------------------------------------------------------------------------------------------
Java内存模型即Java Memory Model,简称JMM。JMM定义了Java 虚拟机(JVM)在计算机内存(RAM)中的工作方式。JVM是整个计算机虚拟模型,所以JMM是隶属于JVM的。
如果我们要想深入了解Java并发编程,就要先理解好Java内存模型。Java内存模型定义了多线程之间共享变量的可见性以及如何在需要的时候对共享变量进行同步。原始的Java内存模型效率并不是很理想,因此Java1.5版本对其进行了重构,现在的Java8仍沿用了Java1.5的版本。
关于并发编程
在并发编程领域,有两个关键问题:线程之间的通信和同步。
线程之间的通信
线程的通信是指线程之间以何种机制来交换信息。在命令式编程中,线程之间的通信机制有两种共享内存和消息传递。
在共享内存的并发模型里,线程之间共享程序的公共状态,线程之间通过写-读内存中的公共状态来隐式进行通信,典型的共享内存通信方式就是通过共享对象进行通信。
在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过明确的发送消息来显式进行通信,在java中典型的消息传递方式就是wait()和notify()。
关于Java线程之间的通信,可以参考线程之间的通信(thread signal)。
线程之间的同步
同步是指程序用于控制不同线程之间操作发生相对顺序的机制。
在共享内存并发模型里,同步是显式进行的。程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行。
在消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。
Java的并发采用的是共享内存模型
Java线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。如果编写多线程程序的Java程序员不理解隐式进行的线程之间通信的工作机制,很可能会遇到各种奇怪的内存可见性问题。
Java内存模型
上面讲到了Java线程之间的通信采用的是过共享内存模型,这里提到的共享内存模型指的就是Java内存模型(简称JMM),JMM决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。

从上图来看,线程A与线程B之间如要通信的话,必须要经历下面2个步骤:
- 1
- 2
- 3
下面通过示意图来说明这两个步骤:

如上图所示,本地内存A和B有主内存中共享变量x的副本。假设初始时,这三个内存中的x值都为0。线程A在执行时,把更新后的x值(假设值为1)临时存放在自己的本地内存A中。当线程A和线程B需要通信时,线程A首先会把自己本地内存中修改后的x值刷新到主内存中,此时主内存中的x值变为了1。随后,线程B到主内存中去读取线程A更新后的x值,此时线程B的本地内存的x值也变为了1。
从整体来看,这两个步骤实质上是线程A在向线程B发送消息,而且这个通信过程必须要经过主内存。JMM通过控制主内存与每个线程的本地内存之间的交互,来为java程序员提供内存可见性保证。
上面也说到了,Java内存模型只是一个抽象概念,那么它在Java中具体是怎么工作的呢?为了更好的理解上Java内存模型工作方式,下面就JVM对Java内存模型的实现、硬件内存模型及它们之间的桥接做详细介绍。
JVM对Java内存模型的实现
在JVM内部,Java内存模型把内存分成了两部分:线程栈区和堆区,下图展示了Java内存模型在JVM中的逻辑视图: 
JVM中运行的每个线程都拥有自己的线程栈,线程栈包含了当前线程执行的方法调用相关信息,我们也把它称作调用栈。随着代码的不断执行,调用栈会不断变化。
线程栈还包含了当前方法的所有本地变量信息。一个线程只能读取自己的线程栈,也就是说,线程中的本地变量对其它线程是不可见的。即使两个线程执行的是同一段代码,它们也会各自在自己的线程栈中创建本地变量,因此,每个线程中的本地变量都会有自己的版本。
所有原始类型(boolean,byte,short,char,int,long,float,double)的本地变量都直接保存在线程栈当中,对于它们的值各个线程之间都是独立的。对于原始类型的本地变量,一个线程可以传递一个副本给另一个线程,当它们之间是无法共享的。
堆区包含了Java应用创建的所有对象信息,不管对象是哪个线程创建的,其中的对象包括原始类型的封装类(如Byte、Integer、Long等等)。不管对象是属于一个成员变量还是方法中的本地变量,它都会被存储在堆区。
下图展示了调用栈和本地变量都存储在栈区,对象都存储在堆区: 
一个本地变量如果是原始类型,那么它会被完全存储到栈区。
一个本地变量也有可能是一个对象的引用,这种情况下,这个本地引用会被存储到栈中,但是对象本身仍然存储在堆区。
对于一个对象的成员方法,这些方法中包含本地变量,仍需要存储在栈区,即使它们所属的对象在堆区。
对于一个对象的成员变量,不管它是原始类型还是包装类型,都会被存储到堆区。
Static类型的变量以及类本身相关信息都会随着类本身存储在堆区。
堆中的对象可以被多线程共享。如果一个线程获得一个对象的应用,它便可访问这个对象的成员变量。如果两个线程同时调用了同一个对象的同一个方法,那么这两个线程便可同时访问这个对象的成员变量,但是对于本地变量,每个线程都会拷贝一份到自己的线程栈中。
下图展示了上面描述的过程:

硬件内存架构
不管是什么内存模型,最终还是运行在计算机硬件上的,所以我们有必要了解计算机硬件内存架构,下图就简单描述了当代计算机硬件内存架构:

现代计算机一般都有2个以上CPU,而且每个CPU还有可能包含多个核心。因此,如果我们的应用是多线程的话,这些线程可能会在各个CPU核心中并行运行。
在CPU内部有一组CPU寄存器,也就是CPU的储存器。CPU操作寄存器的速度要比操作计算机主存快的多。在主存和CPU寄存器之间还存在一个CPU缓存,CPU操作CPU缓存的速度快于主存但慢于CPU寄存器。某些CPU可能有多个缓存层(一级缓存和二级缓存)。计算机的主存也称作RAM,所有的CPU都能够访问主存,而且主存比上面提到的缓存和寄存器大很多。
当一个CPU需要访问主存时,会先读取一部分主存数据到CPU缓存,进而在读取CPU缓存到寄存器。当CPU需要写数据到主存时,同样会先flush寄存器到CPU缓存,然后再在某些节点把缓存数据flush到主存。
Java内存模型和硬件架构之间的桥接
正如上面讲到的,Java内存模型和硬件内存架构并不一致。硬件内存架构中并没有区分栈和堆,从硬件上看,不管是栈还是堆,大部分数据都会存到主存中,当然一部分栈和堆的数据也有可能会存到CPU寄存器中,如下图所示,Java内存模型和计算机硬件内存架构是一个交叉关系:
当对象和变量存储到计算机的各个内存区域时,必然会面临一些问题,其中最主要的两个问题是:

- 1
- 2
- 3
共享对象的可见性
当多个线程同时操作同一个共享对象时,如果没有合理的使用volatile和synchronization关键字,一个线程对共享对象的更新有可能导致其它线程不可见。
想象一下我们的共享对象存储在主存,一个CPU中的线程读取主存数据到CPU缓存,然后对共享对象做了更改,但CPU缓存中的更改后的对象还没有flush到主存,此时线程对共享对象的更改对其它CPU中的线程是不可见的。最终就是每个线程最终都会拷贝共享对象,而且拷贝的对象位于不同的CPU缓存中。
下图展示了上面描述的过程。左边CPU中运行的线程从主存中拷贝共享对象obj到它的CPU缓存,把对象obj的count变量改为2。但这个变更对运行在右边CPU中的线程不可见,因为这个更改还没有flush到主存中: 
要解决共享对象可见性这个问题,我们可以使用java volatile关键字。 Java’s volatile keyword. volatile 关键字可以保证变量会直接从主存读取,而对变量的更新也会直接写到主存。volatile原理是基于CPU内存屏障指令实现的,后面会讲到。
竞争现象
如果多个线程共享一个对象,如果它们同时修改这个共享对象,这就产生了竞争现象。
如下图所示,线程A和线程B共享一个对象obj。假设线程A从主存读取Obj.count变量到自己的CPU缓存,同时,线程B也读取了Obj.count变量到它的CPU缓存,并且这两个线程都对Obj.count做了加1操作。此时,Obj.count加1操作被执行了两次,不过都在不同的CPU缓存中。
如果这两个加1操作是串行执行的,那么Obj.count变量便会在原始值上加2,最终主存中的Obj.count的值会是3。然而下图中两个加1操作是并行的,不管是线程A还是线程B先flush计算结果到主存,最终主存中的Obj.count只会增加1次变成2,尽管一共有两次加1操作。

要解决上面的问题我们可以使用java synchronized代码块。synchronized代码块可以保证同一个时刻只能有一个线程进入代码竞争区,synchronized代码块也能保证代码块中所有变量都将会从主存中读,当线程退出代码块时,对所有变量的更新将会flush到主存,不管这些变量是不是volatile类型的。
volatile和 synchronized区别
首先需要理解线程安全的两个方面:执行控制和内存可见。
执行控制的目的是控制代码执行(顺序)及是否可以并发执行。
内存可见控制的是线程执行结果在内存中对其它线程的可见性。根据Java内存模型的实现,线程在具体执行时,会先拷贝主存数据到线程本地(CPU缓存),操作完成后再把结果从线程本地刷到主存。
synchronized关键字解决的是执行控制的问题,它会阻止其它线程获取当前对象的监控锁,这样就使得当前对象中被synchronized关键字保护的代码块无法被其它线程访问,也就无法并发执行。更重要的是,synchronized还会创建一个内存屏障,内存屏障指令保证了所有CPU操作结果都会直接刷到主存中,从而保证了操作的内存可见性,同时也使得先获得这个锁的线程的所有操作,都happens-before于随后获得这个锁的线程的操作。
volatile关键字解决的是内存可见性的问题,会使得所有对volatile变量的读写都会直接刷到主存,即保证了变量的可见性。这样就能满足一些对变量可见性有要求而对读取顺序没有要求的需求。
使用volatile关键字仅能实现对原始变量(如boolen、 short 、int 、long等)操作的原子性,但需要特别注意, volatile不能保证复合操作的原子性,即使只是i++,实际上也是由多个原子操作组成:read i; inc; write i,假如多个线程同时执行i++,volatile只能保证他们操作的i是同一块内存,但依然可能出现写入脏数据的情况。
在Java 5提供了原子数据类型atomic wrapper classes,对它们的increase之类的操作都是原子操作,不需要使用sychronized关键字。
对于volatile关键字,当且仅当满足以下所有条件时可使用:
- 1
- 2
- 3
volatile和synchronized的区别
- volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取; synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
- volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的
- volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性
- volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
- volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化
支撑Java内存模型的基础原理
指令重排序
在执行程序时,为了提高性能,编译器和处理器会对指令做重排序。但是,JMM确保在不同的编译器和不同的处理器平台之上,通过插入特定类型的Memory Barrier来禁止特定类型的编译器重排序和处理器重排序,为上层提供一致的内存可见性保证。
- 编译器优化重排序:编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序:如果不存l在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序:处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
数据依赖性
如果两个操作访问同一个变量,其中一个为写操作,此时这两个操作之间存在数据依赖性。
编译器和处理器不会改变存在数据依赖性关系的两个操作的执行顺序,即不会重排序。
as-if-serial
不管怎么重排序,单线程下的执行结果不能被改变,编译器、runtime和处理器都必须遵守as-if-serial语义。
内存屏障(Memory Barrier )
上面讲到了,通过内存屏障可以禁止特定类型处理器的重排序,从而让程序按我们预想的流程去执行。内存屏障,又称内存栅栏,是一个CPU指令,基本上它是一条这样的指令:
- 保证特定操作的执行顺序。
- 影响某些数据(或则是某条指令的执行结果)的内存可见性。
编译器和CPU能够重排序指令,保证最终相同的结果,尝试优化性能。插入一条Memory Barrier会告诉编译器和CPU:不管什么指令都不能和这条Memory Barrier指令重排序。
Memory Barrier所做的另外一件事是强制刷出各种CPU cache,如一个Write-Barrier(写入屏障)将刷出所有在Barrier之前写入 cache 的数据,因此,任何CPU上的线程都能读取到这些数据的最新版本。
这和java有什么关系?上面java内存模型中讲到的volatile是基于Memory Barrier实现的。
如果一个变量是volatile修饰的,JMM会在写入这个字段之后插进一个Write-Barrier指令,并在读这个字段之前插入一个Read-Barrier指令。这意味着,如果写入一个volatile变量,就可以保证:
- 一个线程写入变量a后,任何线程访问该变量都会拿到最新值。
- 在写入变量a之前的写入操作,其更新的数据对于其他线程也是可见的。因为Memory Barrier会刷出cache中的所有先前的写入。
happens-before
从jdk5开始,java使用新的JSR-133内存模型,基于happens-before的概念来阐述操作之间的内存可见性。
在JMM中,如果一个操作的执行结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系,这个的两个操作既可以在同一个线程,也可以在不同的两个线程中。
与程序员密切相关的happens-before规则如下:
- 程序顺序规则:一个线程中的每个操作,happens-before于该线程中任意的后续操作。
- 监视器锁规则:对一个锁的解锁操作,happens-before于随后对这个锁的加锁操作。
- volatile域规则:对一个volatile域的写操作,happens-before于任意线程后续对这个volatile域的读。
- 传递性规则:如果 A happens-before B,且 B happens-before C,那么A happens-before C。
注意:两个操作之间具有happens-before关系,并不意味前一个操作必须要在后一个操作之前执行!仅仅要求前一个操作的执行结果,对于后一个操作是可见的,且前一个操作按顺序排在后一个操作之前。
由于Java程序是交由JVM执行的,所以我们在谈Java内存区域划分的时候事实上是指JVM内存区域划分。在讨论JVM内存区域划分之前,先来看一下Java程序具体执行的过程:

如上图所示,首先Java源代码文件(.java后缀)会被Java编译器编译为字节码文件(.class后缀),然后由JVM中的类加载器加载各个类的字节码文件,加载完毕之后,交由JVM执行引擎执行。在整个程序执行过程中,JVM会用一段空间来存储程序执行期间需要用到的数据和相关信息,这段空间一般被称作为Runtime Data Area(运行时数据区),也就是我们常说的JVM内存。因此,在Java中我们常常说到的内存管理就是针对这段空间进行管理(如何分配和回收内存空间)。
在知道了JVM内存是什么东西之后,下面我们就来讨论一下这段空间具体是如何划分区域的,是不是也像C语言中一样也存在栈和堆呢?
一.运行时数据区包括哪几部分?
根据《Java虚拟机规范》的规定,运行时数据区通常包括这几个部分:程序计数器(Program Counter Register)、Java栈(VM Stack)、本地方法栈(Native Method Stack)、方法区(Method Area)、堆(Heap)。

如上图所示,JVM中的运行时数据区应该包括这些部分。在JVM规范中虽然规定了程序在执行期间运行时数据区应该包括这几部分,但是至于具体如何实现并没有做出规定,不同的虚拟机厂商可以有不同的实现方式。
二.运行时数据区的每部分到底存储了哪些数据?
下面我们来了解一下运行时数据区的每部分具体用来存储程序执行过程中的哪些数据。
1.程序计数器
程序计数器(Program Counter Register),也有称作为PC寄存器。想必学过汇编语言的朋友对程序计数器这个概念并不陌生,在汇编语言中,程序计数器是指CPU中的寄存器,它保存的是程序当前执行的指令的地址(也可以说保存下一条指令的所在存储单元的地址),当CPU需要执行指令时,需要从程序计数器中得到当前需要执行的指令所在存储单元的地址,然后根据得到的地址获取到指令,在得到指令之后,程序计数器便自动加1或者根据转移指针得到下一条指令的地址,如此循环,直至执行完所有的指令。
虽然JVM中的程序计数器并不像汇编语言中的程序计数器一样是物理概念上的CPU寄存器,但是JVM中的程序计数器的功能跟汇编语言中的程序计数器的功能在逻辑上是等同的,也就是说是用来指示 执行哪条指令的。
由于在JVM中,多线程是通过线程轮流切换来获得CPU执行时间的,因此,在任一具体时刻,一个CPU的内核只会执行一条线程中的指令,因此,为了能够使得每个线程都在线程切换后能够恢复在切换之前的程序执行位置,每个线程都需要有自己独立的程序计数器,并且不能互相被干扰,否则就会影响到程序的正常执行次序。因此,可以这么说,程序计数器是每个线程所私有的。
在JVM规范中规定,如果线程执行的是非native方法,则程序计数器中保存的是当前需要执行的指令的地址;如果线程执行的是native方法,则程序计数器中的值是undefined。
由于程序计数器中存储的数据所占空间的大小不会随程序的执行而发生改变,因此,对于程序计数器是不会发生内存溢出现象(OutOfMemory)的。
2.Java栈
Java栈也称作虚拟机栈(Java Vitual Machine Stack),也就是我们常常所说的栈,跟C语言的数据段中的栈类似。事实上,Java栈是Java方法执行的内存模型。为什么这么说呢?下面就来解释一下其中的原因。
Java栈中存放的是一个个的栈帧,每个栈帧对应一个被调用的方法,在栈帧中包括局部变量表(Local Variables)、操作数栈(Operand Stack)、指向当前方法所属的类的运行时常量池(运行时常量池的概念在方法区部分会谈到)的引用(Reference to runtime constant pool)、方法返回地址(Return Address)和一些额外的附加信息。当线程执行一个方法时,就会随之创建一个对应的栈帧,并将建立的栈帧压栈。当方法执行完毕之后,便会将栈帧出栈。因此可知,线程当前执行的方法所对应的栈帧必定位于Java栈的顶部。讲到这里,大家就应该会明白为什么 在 使用 递归方法的时候容易导致栈内存溢出的现象了以及为什么栈区的空间不用程序员去管理了(当然在Java中,程序员基本不用关系到内存分配和释放的事情,因为Java有自己的垃圾回收机制),这部分空间的分配和释放都是由系统自动实施的。对于所有的程序设计语言来说,栈这部分空间对程序员来说是不透明的。下图表示了一个Java栈的模型:

局部变量表,顾名思义,想必不用解释大家应该明白它的作用了吧。就是用来存储方法中的局部变量(包括在方法中声明的非静态变量以及函数形参)。对于基本数据类型的变量,则直接存储它的值,对于引用类型的变量,则存的是指向对象的引用。局部变量表的大小在编译器就可以确定其大小了,因此在程序执行期间局部变量表的大小是不会改变的。
操作数栈,想必学过数据结构中的栈的朋友想必对表达式求值问题不会陌生,栈最典型的一个应用就是用来对表达式求值。想想一个线程执行方法的过程中,实际上就是不断执行语句的过程,而归根到底就是进行计算的过程。因此可以这么说,程序中的所有计算过程都是在借助于操作数栈来完成的。
指向运行时常量池的引用,因为在方法执行的过程中有可能需要用到类中的常量,所以必须要有一个引用指向运行时常量。
方法返回地址,当一个方法执行完毕之后,要返回之前调用它的地方,因此在栈帧中必须保存一个方法返回地址。
由于每个线程正在执行的方法可能不同,因此每个线程都会有一个自己的Java栈,互不干扰。
3.本地方法栈
本地方法栈与Java栈的作用和原理非常相似。区别只不过是Java栈是为执行Java方法服务的,而本地方法栈则是为执行本地方法(Native Method)服务的。在JVM规范中,并没有对本地方发展的具体实现方法以及数据结构作强制规定,虚拟机可以自由实现它。在HotSopt虚拟机中直接就把本地方法栈和Java栈合二为一。
4.堆
在C语言中,堆这部分空间是唯一一个程序员可以管理的内存区域。程序员可以通过malloc函数和free函数在堆上申请和释放空间。那么在Java中是怎么样的呢?
Java中的堆是用来存储对象本身的以及数组(当然,数组引用是存放在Java栈中的)。只不过和C语言中的不同,在Java中,程序员基本不用去关心空间释放的问题,Java的垃圾回收机制会自动进行处理。因此这部分空间也是Java垃圾收集器管理的主要区域。另外,堆是被所有线程共享的,在JVM中只有一个堆。
5.方法区
方法区在JVM中也是一个非常重要的区域,它与堆一样,是被线程共享的区域。在方法区中,存储了每个类的信息(包括类的名称、方法信息、字段信息)、静态变量、常量以及编译器编译后的代码等。
在Class文件中除了类的字段、方法、接口等描述信息外,还有一项信息是常量池,用来存储编译期间生成的字面量和符号引用。
在方法区中有一个非常重要的部分就是运行时常量池,它是每一个类或接口的常量池的运行时表示形式,在类和接口被加载到JVM后,对应的运行时常量池就被创建出来。当然并非Class文件常量池中的内容才能进入运行时常量池,在运行期间也可将新的常量放入运行时常量池中,比如String的intern方法。
在JVM规范中,没有强制要求方法区必须实现垃圾回收。很多人习惯将方法区称为“永久代”,是因为HotSpot虚拟机以永久代来实现方法区,从而JVM的垃圾收集器可以像管理堆区一样管理这部分区域,从而不需要专门为这部分设计垃圾回收机制。不过自从JDK7之后,Hotspot虚拟机便将运行时常量池从永久代移除了。
java内存分两种:栈内存和堆内存
栈用来存储基本类型变量和指向对象的引用类型变量,对象本身总是在堆中被创建
堆内存用来存放由new创建的对象和数组以及成员变量
堆内存被所有线程共享,但每个线程有自己的栈

- 浅析java内存模型--JMM(Java Memory Model)
- 浅析java内存模型--JMM(Java Memory Model)
- 浅析java内存模型--JMM(Java Memory Model)
- 浅析java内存模型--JMM(Java Memory Model)
- 浅析java内存模型--JMM(Java Memory Model)
- 浅析java内存模型--JMM(Java Memory Model)
- 浅析java内存模型--JMM(Java Memory Model)
- Java 内存模型(Java Memory Model,JMM)
- Java内存模型JMM浅析
- Java 内存模型 JMM 浅析
- Java 内存模型 JMM 浅析
- 浅析java内存模型(JMM)
- JMM(java内存模型)
- Java 内存模型 JMM
- java内存模型-JMM
- Java 内存模型JMM
- Java内存模型JMM
- java内存模型jmm
- springboot定时器的使用 之 cron fixedRate initialDelay 探究
- JavaScript中的多维数组与对象
- Git常用命令
- 一个程序员送给大学生弟弟的那些话
- Nginx+Sticky实现负载均衡(1)
- 浅析java内存模型--JMM(Java Memory Model)
- C C++ 全套视频课程收录
- 什么是CDN劫持
- HDU
- 搞大数据,你不懂这三大数据处理趋势就OUT了
- springboot整合activemq,应答模式,消息重发机制,消息持久化
- Effect(十四)—— EffectManager
- SQL case when 遇到null值时的解决办法
- 解决tomcat端口被占用的问题


