浏览器加载、解析、渲染的过程
来源:互联网 发布:ipad看tvb软件 编辑:程序博客网 时间:2024/06/08 01:04
刚看完一篇文章 How browsers work ,被里面浏览器加载解析文件中标签、CSS、javascript的顺序搞晕了……
最初困惑我的是一张图,下面这张。它解释了浏览器解析、渲染的过程:解析HTML,构建dom树 > 构建rander树 > 布局render树 > 绘制render树。但有一个细节引起了我的注意:这张图片的起点不止一个,有 HTML解析 和 CSS解析,但浏览器是同步的呀,所以按照 “自上而下”的解析原则,应该是遇到谁解析谁呗?
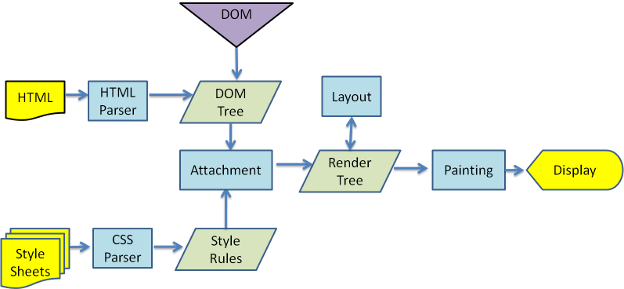
又翻到另一篇 博客 文章,结合起来理一下思路吧。
这段关于HTML页面加载执行流程的描述挺有意思哒……
1. 用户输入网址(假设是个html页面,并且是第一次访问),浏览器向服务器发出请求,服务器返回html文件;
2. 浏览器开始载入html代码,发现<head>标签内有一个<link>标签引用外部CSS文件;
3. 浏览器又发出CSS文件的请求,服务器返回这个CSS文件;
4. 浏览器继续载入html中<body>部分的代码,并且CSS文件已经拿到手了,可以开始渲染页面了;
5. 浏览器在代码中发现一个<img>标签引用了一张图片,向服务器发出请求。此时浏览器不会等到图片下载完,而是继续渲 染后面的代码;
6. 服务器返回图片文件,由于图片占用了一定面积,影响了后面段落的排布,因此浏览器需要回过头来重新渲染这部分代码;
7. 浏览器发现了一个包含一行Javascript代码的<script>标签,赶快运行它;
8. Javascript脚本执行了这条语句,它命令浏览器隐藏掉代码中的某个<div> (style.display=”none”)。突然少了这么一个元素,浏览器不得不重新渲染这部分代码;
9. 终于等到了</html>的到来,浏览器泪流满面……
10. 等等,还没完,用户点了一下界面中的“换肤”按钮,Javascript让浏览器换了一下<link>标签的CSS路径;
11. 浏览器召集了在座的各位<div><span><ul><li>们,“大伙儿收拾收拾行李,咱得重新来过……”,浏览器向服务器请求了新的CSS文件,重新渲染页面。
所以……总结如下,欢迎拍砖。
1. 浏览器获得一个HTML文件后,会 “自上而下” 开始加载,而且边加载边解析;
2. 考虑到用户的体验感,渲染引擎尽可能早地将内容呈现在屏幕上,浏览器不会等将html全部解析完后再构建render树来呈现,而是边解析边显示,其余部分可以继续下载;
3. 遇到<script>标签,渲染引擎会将控制权交由script引擎来执行脚本。因为脚本会通过DOM API操作DOM,如果一边执行脚本一边继续构建DOM树,二者会发生冲突;
4. 如果<script>引用了外部脚本,会停止document解析,转去下载外部脚本并执行,此处也是同步的。如果外链的js脚本设置了defer=" true" 属性(内置和动态生成的js脚本该属性不起作用),此时文档加载解析继续进行,不会被阻塞,js代码也会并行加载,但js会在所有元素解析完成以后,DOMContentLoaded事件触发之前执行;
5. 如果外链的js脚本设置了async (异步) 属性,加载js和渲染后续文档过程并行进行(异步),一旦js脚本加载完毕就会立即执行。这种方式不能保证按书写的顺序执行,因为浏览器解析到该属性时会认为该脚本不依赖其他的js和css;
6. 现在许多浏览器做了优化。当javascript引擎执行js脚本时,浏览器会开启其他线程继续解析下面的文档,发现其余需要下载的外部资源,如图片、外部js、样式表等,这些下载也是并行进行的;
7. 样式表在加载解析时会阻塞js的执行。虽然css (一般只会出现在head中) 并不会改变DOM结构,但js执行过程中可能会请求样式信息,如果二者同时执行js会得到错误信息,所以js会在前面的样式表全部解析完后再开始执行。但有一点,外链的css和js是并行下载的。
- 浏览器加载、解析、渲染的过程
- 浏览器加载、解析、渲染的过程
- 浏览器加载解析渲染网页的过程
- 浏览器加载、解析、渲染的过程
- 浏览器加载、解析、渲染的过程
- 浏览器加载、解析、渲染的过程
- 浏览器加载、解析、渲染的过程
- 浏览器加载、渲染和解析过程的黑箱分析
- 浏览器加载、渲染和解析过程的黑箱分析[ZT]
- 浏览器加载、渲染和解析过程的黑箱分析
- 浏览器对网页的加载 渲染 解析 过程 总结
- 浏览器的加载、解析、渲染
- 浏览器加载渲染网页过程解析
- 浏览器加载渲染网页过程解析
- 05-浏览器加载、解析、渲染这个过程
- 浏览器的解析渲染过程
- 浏览器解析渲染的过程
- 浏览器~加载,解析,渲染
- 动态sql
- Oracle EBS Interface/API(8)-标准展BOM存储过程
- UnityShader实例06:UV动画
- Python实现网络图节点大小随度数变化
- HDU 5935
- 浏览器加载、解析、渲染的过程
- log4cpp简单使用
- APICloud 开发app 之 工具:Sublime插件
- 802.11协议帧格式、Wi-Fi连接交互过程、无线破解入门研究
- 阿里云centos7.2安装mysql-5.7.20
- HTTP协议
- 类,超类和子类(一)
- 拦截器学习
- java基础


