hadoop 更换数据目录
来源:互联网 发布:打印机无法配置该端口 编辑:程序博客网 时间:2024/06/06 02:18
一、扩容本地磁盘并挂载
机器都是阿里云的服务器,需要现在阿里云购买磁盘。然后挂载到服务器上
1、把新加的磁盘挂载到了/hdfs_data
2、原来默认的hdfs的数据目录为/usr/local/hadoop/hdfs/data/
<name>dfs.datanode.data.dir</name><value>二、停止Datanode
我这里有三台datanode,数量比较小,所以就一台一台的做操作了。
如果是小环境,就一台一台的Datanode操作,这样能保证数据不会丢,因为有3个副本,所以,即使停掉一台Datanode也没有问题,不影响使用。
注意:以下操作逐一在需要扩容的datanode服务器上都执行。
1、暴力停止(kill),因为./hadoop-daemon.sh stop datanode 不能停。
kill `ps -ef | grep datanode | grep -v grep | awk '{print $2}'`2、迁移数据
mv /usr/local/hadoop/hdfs/data/current /hdfs_data/3、修改hadoop配置文件
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml把:<name>dfs.datanode.data.dir</name><value>改成:<name>dfs.datanode.data.dir</name><value>file:///hdfs_data</value>三、启动Datanode
逐一在Datanode服务器上执行:
/usr/local/hadoop/sbin/hadoop-daemon.sh start datanode检测datanode是否正常启动:
ps -ef | grep datanode | grep -v grep四、平衡数据
逐一在Datanode服务器上执行:
/usr/local/hadoop/sbin/start-balancer.sh五、测试Datanode是否扩容成功
登陆::http://Namenode:50070查看。
或者,通过hdfs dfsadmin -report 命令进行查看。
然后测试各种读写操作。
最后上个图:
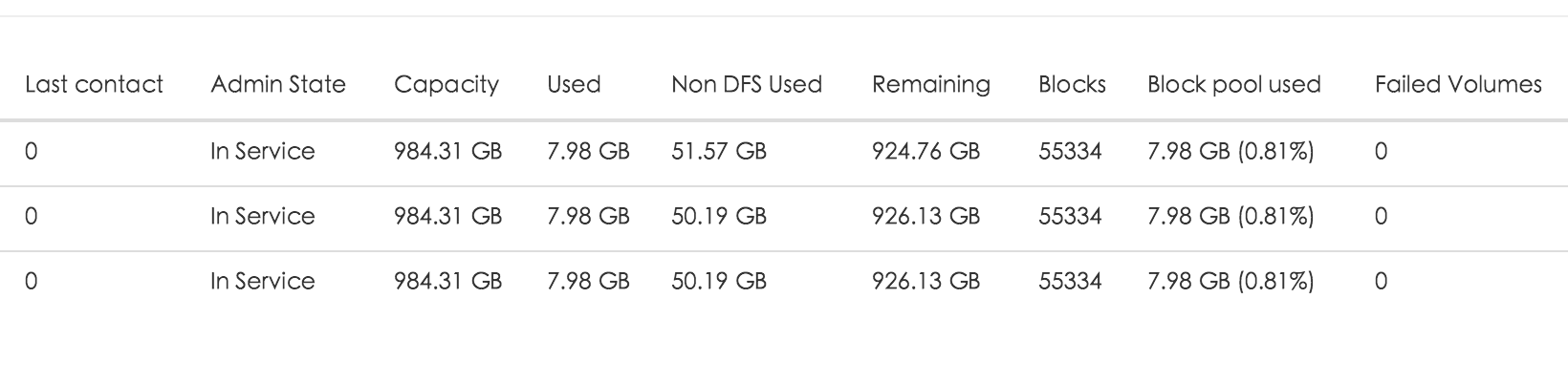
阅读全文
0 0
- hadoop 更换数据目录
- mysql更换数据存储目录
- mysql下的数据存储目录更换
- Hadoop数据目录迁移
- linux MySQL Community Server 5.7.9 更换数据目录位置
- MYSQL数据库的数据目录无缝更换记载
- 解决mysql更换数据存储目录的问题
- 解决mysql更换数据存储目录的问题
- hadoop更换硬盘
- Hadoop DataNode启动之数据目录校验
- hadoop hdfs 添加数据目录出错
- dedecms更换目录
- 更换mysql数据目录后出现ERROR 2002 (HY000): Can't connect to local MySQL serve
- 更换mysql数据目录后出现ERROR 2002 (HY000): Can't connect to local MySQL serve
- 更换mysql数据目录后出现ERROR 2002 (HY000): Can't connect to local MySQL serve
- vsftpd更换匿名登录目录
- SVN项目资源库目录更换
- SVN项目资源库目录更换
- ZOJ1157
- 线程控制(一)线程基础
- java-第5天
- 09全志r40m平台的SATA验证(分色排版)
- 《剑指offer》面试题17:打印从1到最大的n位数
- hadoop 更换数据目录
- hdu 1516 String Distance and Transform Process(编辑距离+记录路径)
- nginx做SSL并配合tomcat实现HTTPS访问
- 图像标注教程(使用LabelImg标注工具)
- asp.net数据库操作时出现错误 其他信息: 基础提供程序在 Open 上失败。
- Milking Cows 挤牛奶--贪心
- 【设计模式】(6)--最常用模式之观察者模式
- Photoshop中的一些简单操作及图片制作
- SSM POI---导出(含工具类)


