支持向量机SVM(一)
来源:互联网 发布:mac下制作黑苹果u盘 编辑:程序博客网 时间:2024/06/06 01:33
支持向量机,因其英文名为support vector machine,故一般简称SVM,是90年代中期发展起来的基于统计学习理论的一种机器学习方法,它是一种二类分类模型,其基本模型定义为特征空间上的间隔较大的线性分类器,其学习策略便是间隔较大化,最终可转化为一个凸二次规划问题的求解,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。
SVM最基本的应用是分类。 求解最优的分类面,然后用于分类。
最优分类面的定义: 对于SVM,存在一个分类面,两个点集到此平面的最小距离最大,两个点集中的边缘点到此平面的距离最大。
重新审视logistic回归
Logistic回归目的是从特征学习出一个0/1分类模型,而这个模型是将特性的线性组合作为自变量,由于自变量的取值范围是负无穷到正无穷。因此,使用logistic函数(或称作sigmoid函数)将自变量映射到(0,1)上,映射后的值被认为是属于y=1的概率。
形式化表示就是
假设函数 
其中x是n维特征向量,函数g就是logistic函数。
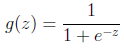 的图像是
的图像是
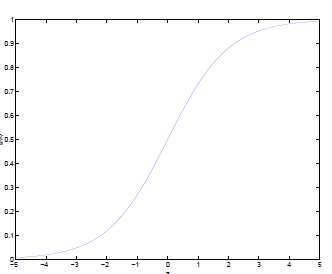
可以看到,将无穷映射到了(0,1)。
而假设函数就是特征属于y=1的概率。
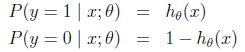
当我们要判别一个新来的特征属于哪个类时,只需求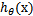 ,若大于0.5就是y=1的类,反之属于y=0类。
,若大于0.5就是y=1的类,反之属于y=0类。
再审视一下,发现只和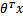 有关,>0,那么
有关,>0,那么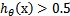 ,g(z)只不过是用来映射,真实的类别决定权还在。还有当
,g(z)只不过是用来映射,真实的类别决定权还在。还有当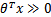 时,=1,反之=0。如果我们只从
时,=1,反之=0。如果我们只从![clip_image008[3]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131131459272.png) 出发,希望模型达到的目标无非就是让训练数据中y=1的特征,而是y=0的特征
出发,希望模型达到的目标无非就是让训练数据中y=1的特征,而是y=0的特征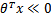 。Logistic回归就是要学习得到
。Logistic回归就是要学习得到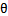 ,使得正例的特征远大于0,负例的特征远小于0,强调在全部训练实例上达到这个目标。
,使得正例的特征远大于0,负例的特征远小于0,强调在全部训练实例上达到这个目标。
图形化表示如下:

中间那条线是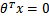 ,logistic回顾强调所有点尽可能地远离中间那条线。学习出的结果也就中间那条线。考虑上面3个点A、B和C。从图中我们可以确定A是×类别的,然而C我们是不太确定的,B还算能够确定。这样我们可以得出结论,我们更应该关心靠近中间分割线的点,让他们尽可能地远离中间线,而不是在所有点上达到最优。因为那样的话,要使得一部分点靠近中间线来换取另外一部分点更加远离中间线。我想这就是支持向量机的思路和logistic回归的不同点,一个考虑局部(不关心已经确定远离的点),一个考虑全局(已经远离的点可能通过调整中间线使其能够更加远离)。这是我的个人直观理解。
,logistic回顾强调所有点尽可能地远离中间那条线。学习出的结果也就中间那条线。考虑上面3个点A、B和C。从图中我们可以确定A是×类别的,然而C我们是不太确定的,B还算能够确定。这样我们可以得出结论,我们更应该关心靠近中间分割线的点,让他们尽可能地远离中间线,而不是在所有点上达到最优。因为那样的话,要使得一部分点靠近中间线来换取另外一部分点更加远离中间线。我想这就是支持向量机的思路和logistic回归的不同点,一个考虑局部(不关心已经确定远离的点),一个考虑全局(已经远离的点可能通过调整中间线使其能够更加远离)。这是我的个人直观理解。
- SVM-支持向量机算法(一)
- 支持向量机SVM(一)
- 支持向量机SVM(一)
- 支持向量机SVM(一)
- SVM支持向量机一(入门)
- 支持向量机SVM(一)
- 支持向量机SVM(一)
- 支持向量机SVM(一)
- 支持向量机SVM(一)
- 支持向量机SVM(一)
- 支持向量机SVM(一)
- 支持向量机SVM(一)
- 支持向量机SVM(一)
- 支持向量机SVM(一)
- 支持向量机SVM(一)
- 支持向量机(SVM)(一)
- 支持向量机SVM(一)
- 支持向量机SVM(一)
- Elon Musk公布特斯拉“下半场”目标:打造一个新能源公司 | 新智驾Weekly
- 乐视超级汽车智驾副总裁倪凯:为何被誉为“中国无人驾驶第一人”
- 浅谈C++中的重载、覆盖、隐藏
- leetcode5:最长回文子串
- 通过HTTP请求响应过程了解HTTP协议
- 支持向量机SVM(一)
- Understanding the JVM(三)对象的内存布局
- python—super
- 从软银本田联手打造智能汽车说开,看看AI如何造福汽车行业
- 360智能家庭总裁邓邱伟:由点及面构筑家庭生态
- MySQL与Python的交互
- monkey测试
- 深度学习基础之Python语法
- BZOJ 1012: [JSOI2008]最大数maxnumber


