[DeeplearningAI笔记]Batch NormalizationBN算法Batch归一化_02_3.4-3.7
来源:互联网 发布:java截屏网页 编辑:程序博客网 时间:2024/06/06 02:36
Batch Normalization
Batch归一化
觉得有用的话,欢迎一起讨论相互学习~Follow Me
3.4正则化网络的激活函数
- Batch归一化会使你的参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定.超参数的范围会更庞大,工作效果也更好.也会使你更容易的训练甚至是深层网络.
- 对于logistic回归来说
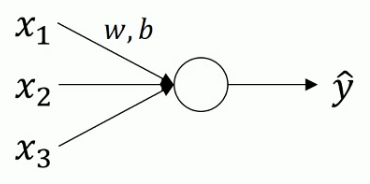
正则化原理
函数曲线会由类似于椭圆变成更圆的东西,更加易于算法优化.
- 深层神经网络
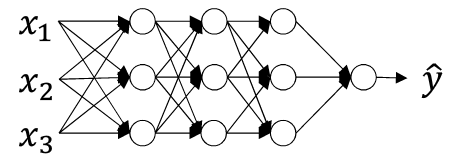
- 我们将每一层神经网络计算得到的z值(在计算激活函数之前的值)进行归一化处理,即将
Z[L]的值进行归一化处理,进而影响下一层W[L+1]和b[L+1] 的计算.

- 此时z的每个分量都含有平均值0和方差1,但我们不想让隐藏单元总是含有平均值0和方差1,例如在应用sigmoid函数时,我们不想使其绘制的函数图像如图所示,我们想要变换方差或者是不同的平均值.


第L层神经元正则化公式
3.5 将Batch Normalization拟合进神经网络
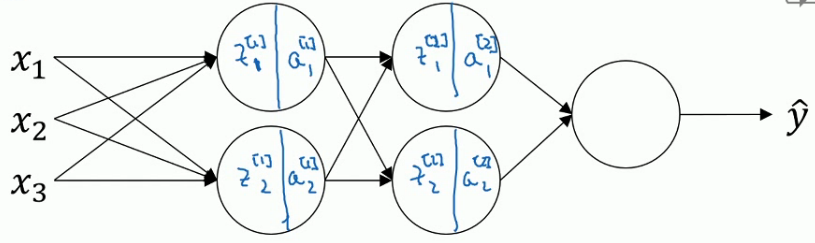
对于Batch Normalization算法而言,计算出一层的

实质上,BN算法是在每一层的
3.6 Batch Normalization为什么奏效
原因一
- 无论数据的范围是0~1之间还是1~1000之间,通过归一化,所有的输入特征X,都可以获得类似范围的值,可加速学习.
原因二
- 如果神经元的数据分布改变,我们也许需要重新训练数据以拟合新的数据分布.这会带来一种数据的不稳定的效果.(covariate shift)
- Batch Normalization做的是它减少了这些隐藏值分布变化的数量.因为随着训练的迭代过程,神经元的值会时常发生变化.batch归一化可以确保,无论其怎样变化,其均值和方差将保持不变.(由每一层的BN函数的参数
β[l],γ[l] 决定其方差和均值) - Batch Normalization减少了输入值改变的问题,它的确使这些值变的稳定,即是原先的层改变了,也会使后面的层适应改变的程度减小.也可以视为它减少了前层参数和后层参数之间的联系.
原因三
- Batch Normalization有轻微的正则化作用.
- BN算法是通过mini-batch计算得出,而不是使用整个数据集,所以会引入部分的噪音,即会在纵轴上有些许波动.
- 缩放的过程从
Z[l]→Z[l]ˇ 也会引入一些噪音. - 所以和Dropout算法一样,它往每个隐藏层的激活值上增加了噪音,dropout有噪音的模式,它使一个隐藏的单元以一定的概率乘以0,以一定得概率乘以1.BN算法的噪音主要体现在标准偏差的缩放和减去均值带来的额外噪音.这使得后面层的神经单元不会过分依赖任何一个隐藏单元.有轻微的正则化作用.如果你想获得更好的正则化效果,可以在使用Batch-Normalization的同时使用Dropout算法.
3.7测试时的Batch Normalization
- Batch-Normalization将你的数据以mini-batch的形式逐一处理,但在测试时,你可能需要对每一个样本逐一处理.我们应该怎么做呢~
Batch-Normalization公式
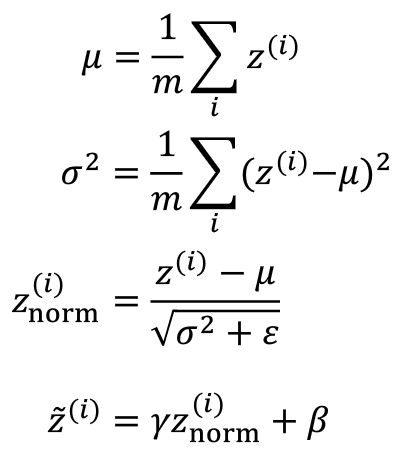
- 注意 对于u和
σ 是在整个mini-batch上进行计算,但是在测试时,你不会使用一个mini-batch中的所有数据(因为测试时,我们仅仅需要少量数据来验证神经网络训练的正确性即可.)况且如果我们只使用一个数据,那一个样本的均值和方差没有意义,因此我们需要用其他的方式来得到u和σ 这两个参数. - 运用覆盖所有mini-batch的指数加权平均数来估算u和
σ
利用指数加权平均来估算u和σ 对数据进行测试
对于第L层神经元层,标记mini-batch为x[1],x[2],x[3],x[4]...x[n] 在训练这个隐藏层的第一个mini-batch得到u[1][l] ,训练第二个mini-batch得到u[2][l] ,训练第三个mini-batch得到u[3][l] …训练第n个mini-batch得到u[n][l] .然后利用指数加权平均法估算u 的值,同理,以这种方式利用指数加权平均的方法估算σ2 .
总结
在训练时,u和σ2 在整个mini-batch上计算出来的,但是在测试时,我们需要单一估算样本,方法是根据你的训练集估算u和σ2 .常见的方法有利用指数加权平均进行估算.
阅读全文
0 0
- [DeeplearningAI笔记]Batch NormalizationBN算法Batch归一化_02_3.4-3.7
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.1_2.2_mini-batch梯度下降法
- Batch Normalization 梯度归一化
- Batch Normalization 梯度归一化
- 深度学习: Batch Normalization (归一化)
- batch
- Batch
- Batch
- Spring Batch学习笔记
- Spring batch笔记
- Batch Normalization 学习笔记
- Batch Normalization 学习笔记
- Batch Normalization 学习笔记
- 论文笔记-Batch Normalization
- Batch Normalization 学习笔记
- Batch Normalization 学习笔记
- spring batch 学习笔记
- Batch Normalization 学习笔记
- 如何保证主从复制数据一致性
- kruskal
- 深浅拷贝&引用计数写时拷贝
- 长方形的面积和周长
- 在Unity中创建可使用快捷键切换输入框的功能
- [DeeplearningAI笔记]Batch NormalizationBN算法Batch归一化_02_3.4-3.7
- Door_Interactiable(VR控制门)
- 个人基因组比对及其变异分析
- 二叉树计算
- Eclipse常用快捷键
- 这门电路画的也是没谁了
- 利用scatter绘制散点图
- 40-前置操作符++i和后置操作符i++
- 多个线程同时执行,每个线程分别打印出自己的名字


