Mysql总结2-mysql基础(DQL,DML,DDL,DCL)
来源:互联网 发布:杭州淘宝美工培训机构 编辑:程序博客网 时间:2024/05/17 23:51
1.数据库简介
DataBase System = 数据库管理系统(DBMS,DataBase Management System) + 数据库(DataBase) + 管理员
SQL:数据库管理系统,用来管理数据的语言。结构化查询语言(SQL,Structured Query Language)
1.1 数据库的四种语法
数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。
1.1.1 数据查询语言DQL
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句组成的查询块:
SELECT <字段名表>
FROM <表或视图名>
WHERE <查询条件>
1.1.2 数据操纵语言DML
数据操纵语言DML主要有三种形式:
1) 插入:INSERT
2) 更新:UPDATE
3) 删除:DELETE
1.1.3 数据定义语言DDL
数据定义语言DDL用来创建数据库中的各种对象—–表、视图、索引、同义词、聚簇等如:
DDL操作是隐性提交的!不能rollback
1.1.4 数据控制语言DCL
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等。如:
1.1.4.1 GRANT:授权。
1.1.4.2 ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。
回滚—ROLLBACK
回滚命令使数据库状态回到上次最后提交的状态。
其格式为: SQL>ROLLBACK;
1.1.4.3 COMMIT [WORK]:提交。
在数据库的插入、删除和修改操作时,只有当事务在提交到数据库时才算完成。在事务提交前,只有操作数据库的这个人才能有权看到所做的事情,别人只有在最后提交完成后才可以看到。提交数据有三种类型:显式提交、隐式提交及自动提交。下面分别说明这三种类型。
(1) 显式提交
用COMMIT命令直接完成的提交为显式提交。其格式为:
SQL>COMMIT;
(2) 隐式提交
用SQL命令间接完成的提交为隐式提交。这些命令是:
ALTER,AUDIT,COMMENT,CONNECT,CREATE,DISCONNECT,DROP,
EXIT,GRANT,NOAUDIT,QUIT,REVOKE,RENAME。
(3) 自动提交
若把AUTOCOMMIT设置为ON,则在插入、修改、删除语句执行后,
系统将自动进行提交,这就是自动提交。其格式为:
SQL>SET AUTOCOMMIT ON;
2.数据库操作
2.1 创建数据库
2.1.1 基本语法
Create database db_name [数据库选项];2.1.2 命令规则
数据库选项包括:
设定数据库字符集(character set utf8)和校对集(collate utf8_general_ci) ;
标识符(数据库名)命名规则:
大小写取决于当前操作系统。(认为是区分的)见名知意。推荐使用下划线方式。
标识符的字符:
使用任意字符,数字,符号,甚至是中文。但是一些特殊的组合,例如纯数字组合,特殊符号,包括mysql是内部关键字 应该使用标识符 限定符来包裹。
限定符: 反引号(“)。
中文可以:但是要求客户端编码 .
2.1.3 创建数据库结果
在mysql的数据目录,形成一个目录,目录名是数据库名。
如果是特殊字符(比如中文),则使用编码的形式保存.
2.2 事务操作
2.2.1 事务操作
首先确定存储引擎是支持事物的比如innodb支持事物.myisam引擎不支持事务, innodb和BDB引擎支持.//查看当前的事物是否开启自动提交,所以才会执行完slq后自动提交mysql> show variables like 'autocommit';+---------------+-------+| Variable_name | Value |+---------------+-------+| autocommit | ON |+---------------+-------+1 row in set, 1 warning (0.00 sec)//修改为off之后,可以试验手工提交数据start transaction 简写 begin //开启事务commit;//成功rollback;//失败:2.2.2 事务特点 ACID
- 1.原子性(Atomicity):是指某几句sql的影响,要么都发生,要么都不发生.
- 2.一致性(Consistency):事务前后的数据,保持业务上的合理一致.
- 3.隔离性(Isolation):在事务进行过程中, 其他事务,看不到此事务的任何效果. 持久性: 事务一旦发生,不能取消. 只能通过补偿性事务,来抵消效果.
- 4.持久性(Durability)。
2.2.3 隔离级别
- read uncommitted: 读未提交的事务内容,显然不符原子性, 称为”脏读”. 在业务中,没人这么用.
- read commited: 在一个事务进行过程中, 读不到另一个进行事务的操作,但是,可以读到另一个结束事务的操作影响.
- repeatable read: 可重复读,即在一个事务过程中,所有信息都来自事务开始那一瞬间的信息,不受其他已提交事务的影响. (大多数的系统,用此隔离级别)
- serializeable 串行化, 所有的事务,必须编号,按顺序一个一个来执行,也就取消了冲突的可能.这样隔离级别最高,但事务相互等待的等待长. 在实用,也不是很多.
//设置隔离级别set session transaction isolation level [read uncommitted | read committed | repeatable read |serializable]2.2 操作数据库
2.2.1 基本语法
//创建数据库Create database db_name [数据库选项];//查看数据库Show databases;//查看数据库创建语句Show create database db_name;//数据库删除Drop database db_name;//修改数据库信息(数据库属性的修改)Alter database db_name [修改指令]//切换数据库use database_new2.2.2 注意
数据库迁移
将数据库内容全部导出,新建一个数据库,将内容导入,删除旧数据库。
创建一个新数据库,将旧数据库内的表,都移动(重命名)到新数据库内,删除旧数据库
\G 格式化输出
删除数据库 删除一个数据库时,同时删除该数据库相关的目录及其目录内容
//格式化输出命令结果Show databases\G;3 表操作(数据定义语言DDL)
3.1 基本语法
//创建表create table tbl_name (列结构[列选项])[表选项];列选项包括: [是否为空] [Default 默认值] [是否为自动增长] [是否为主索引或唯一索引] [comment 注释] [引用定义]表选项: 表引擎:engine|type=引擎;表字符集与校对集 charset set=字符集 collate=校对集; 注释 comment=‘注释’eg:mysql> create table test_table( -> name varchar(20), -> score int -> );Query OK, 0 rows affected (0.03 sec)//查看表show tables;//模糊查看表show tables like 'exam_%';//查看表的创建信息show create table tbl_name;//\G可以格式化输出show create table tbl_name\G;//查看表结构describe tbl_name;//查看表结构(简写)desc tbl_name;//删除表drop table [if exists] tbl_name; 也可以删除多个,用逗号分隔开. //修改表名称Rename table old_tbl_name to new_tbl_name;//修改表名称(多个)Rename table old_tbl_name1 to new_tbl_name1,old_tbl_name2 to new_tbl_name2;//修改表内容(列定义)alter table tbl_name [add|drop|change|modify]//修改表内容-新增一列alter tablename add newcolumn varchar(10);//修改表内容-删除一列alter tablename drop onecolumn;//修改表内容-修改列属性alter tablename modify newcolumn varchar(20)://修改表内容-修改列名称alter tablename change old_column_name new_column_name varchar(30);3.2 其它基本语法
- Null | not null 可以规定当前列,是否可以为null。
- DEFAULT 默认值,如果sql不书写该列才用默认值.
- 主键 PRIMARY KEY
- 自动增长 Auto_increment
- 修改表名称支持跨数据库
3.3 列数据类型
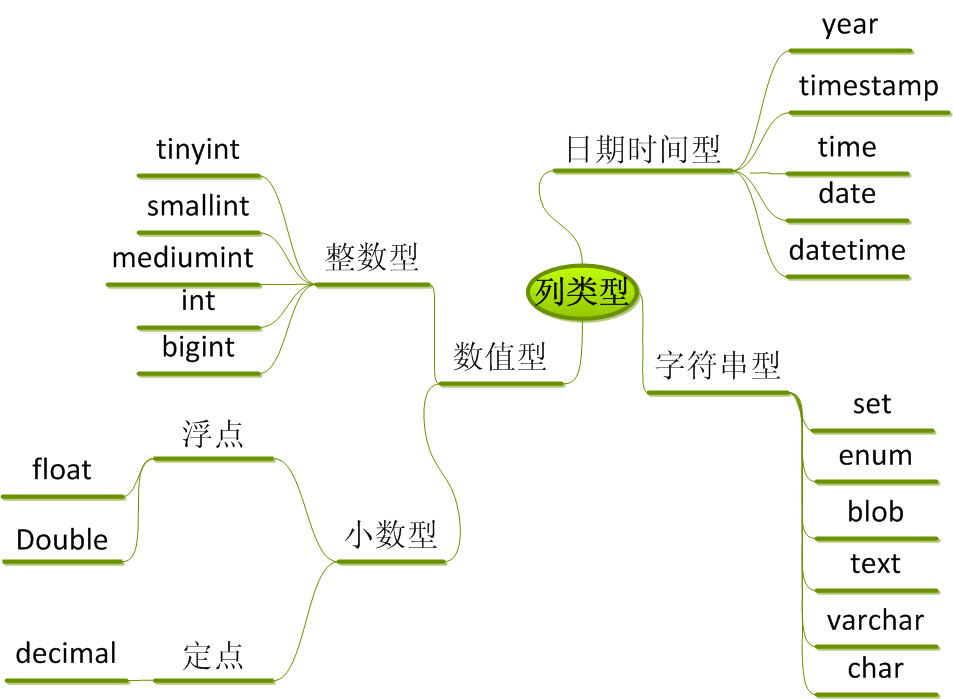
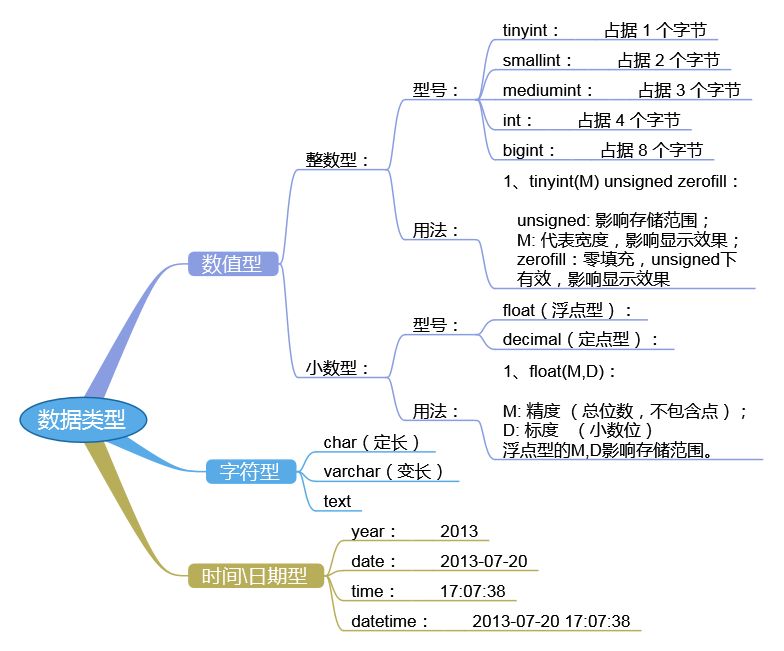
3.3.1 整型
3.3.1.1 整型分类
3.3.1.2 详解
- 是否有符号
默认不写就是有符号, 如果要符号见下列SQL. - 定义显示宽度
前导零填充达到目的。称之为 zerofill.(不影响数的范围,宽度大的不影响,不会截取) - 创建时的括号内int(10)的数值意义 创建列字段时的宽度意义为显示宽度,当数值过小用到zerofill时的补充0的后的总体宽度,如果数值过大,则不截取.和存储的数据大小没关系.默认不写会自动填写11.
- boolean
布尔bool类型,但是就是tinyint(1)的别名
//整型带符号column_name int unsigned;//前导零填充,补充零的个数最终和括号中的10一致,默认不写会自动填写11coluemn_name int(10) zerofill;3.3.2 小数
3.3.2.1 小数分类
3.3.2.2 详解
- float单精度 默认精度(不是位数)为6位左右。
- double双精度 默认精度(不是位数)为16位左右。
- DECIMAL(M,D) M表示所有的数值位数(不包括小数点,和符号),D,表示允许的小数位数。默认为(10,0)
- 可以zerofill;可以无符号;可以使用科学计数法(写法为: 1.234E3)
3.3.3 日期时间
3.3.3.1 日期时间分类
3.3.3.2 详解
- timestamp 存储是整型,但是显示时都是时间格式;可用 t.
timestamp_column+0 来显示时间戳. - date 支持二位的年份70-69 1970 - 2069,70-99 19xx,0-69 20xx年(不支持使用).
- time 可以表示1)一天中的时间;2)表示时间间隔,在表示间隔时. D HH:MM:SS ; D天。
- year 范围是1901-2155;不是1000-9999。
- timestampe容易移植
3.3.4 字符串
3.3.4.1 字符串分类
3.3.4.2 字符串注意
- Char(M) 固定长度.表示允许的字符串长度.
- Varchar(M) 可变长度.M在varchar中的表示,是允许的最大长度.
- varchar(M)在保存字符串时,同时保存该字符串的长度,小于255采用一个字节保存,否则采用二个字节保存
- varchar(M),最大65535,如果是gbk,只能保存理论32767(65535/2=32767余1)字符,如果是utf8只能保存理论21845(65535/3)字符.
- varchar的真实长度
如果类型数据超过255个字符时,则最大长度变为65535-2=65533,这两个字段来保存字符串的长度.
整条数据会有一个字节来保存记录中的null值: 数据的整条记录需要1个字节来保存null记录(保存所有列的null记录).除非所有列都不为null才能忽略不计.不使用该字节.
也就是varchar的的最终长度为65535(整列所有字段属性都不能为空)/65534包含任一列字段可为空)-2(超过255的时候要占个字节) 除于 2(gbk)/或3(utf8)= (65533/65534 -2)除于 2/或3 = 65531/65532 除于2/或3.
- text text的长度是65535(字符),还有 Tinytext longtext,不占用 一行数据的 65535的长度限制.
- enum ENUM(“one”, “two”, “three”) ,实际存储的值为1,2,3. 最多65535
- set
set1set(‘ABC’,’1111’,’2222’,’XXX’) DEFAULT NULL, ABC的值1,1111的值2,2222的值4,XXX的值8. 如果多个用逗号隔开,存储的为值对应的数值的和.
3.4. 存储引擎
3.4.1 存储引擎介绍
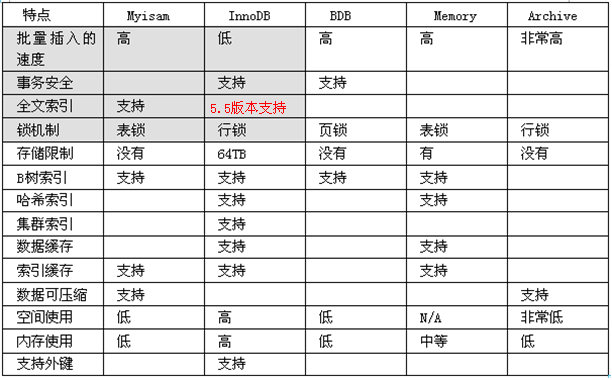
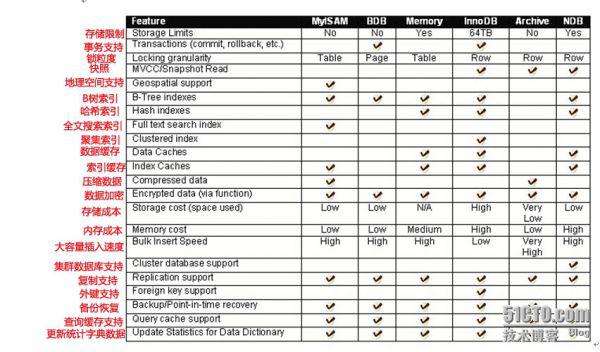
3.4.2 MyISAM和InnoDB对比
3.4.2.1
MyISAM 不支持事务、也不支持外键,但其访问速度快,对事务完整性没有要求.
InnoDB 存储引擎提供了具有提交、回滚和崩溃恢复能力的事 务安全。但是比起MyISAM存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引
MEMORY 存储引擎使用存在内存中的内容来创建表。 每个MEMORY表只实际对应一个磁盘文件。MEMORY类型的表访问非常得快,因为它的数据是放在内存中的,并且默认使用HASH索引。但是一旦服务关闭,表中的数据就会丢失掉.(Memory 存储,比如我们数据变化频繁,不需要入库,同时又频繁的查询和修改,我们考虑使用memory, 速度极快. )
3.4.2.2 存储数据格式
InnoDB:
数据保存在: ibdata1,
表名目录下: sys_role2.frm,sys_role2.idb
MyISAM:
表名: user.frm
数据: user.MYD
索引: user.MYI
索引中记录了磁盘的位置. 如果将数据frm和myd和myi复制到新的地方.数据都存在,但是索引需要重建,因为磁盘位置已经不一样了.
分区的时候MyISAM如下:
table1.frm,table1.par,table#P#t0.MYD,table#P#t0.MYI,table#P#t1.MYD,table#P#t1.MYI,table#P#t2.MYD,table#P#t2.MYI,
3.4.2.3 索引原理区别
(聚簇索引,b-tree索引)-将在mysql优化中总结.
3.4.2.4 如何选择存储引擎
myisam 存储: 如果表对事务要求不高,同时是以查询和添加为主的,我们考虑使用myisam存储引擎.,比如 bbs 中的 发帖表,回复表.
INNODB 存储: 对事务要求高,保存的数据都是重要数据,我们建议使用INNODB,比如订单表,账号表.
3.4.3 存储引擎配置
- my.ini中额皮质默认
default-storage-engine=INNODB- 创建sql时指定
//1.创建表是指定CREATE TABLE `order_info` ( `id` INT(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `order_no` VARCHAR(64) DEFAULT NULL COMMENT '流水号' PRIMARY KEY (`id`)) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='订单表'//2.修改表的存储引擎ALTER TABLE `order_info` ENGINE=MYISAM;3.5 字符集&校对规则
3.5.1 构成部分:
字符的集合,展示
字符的编码,保存和处理
Show character set;mysql> show character set;+----------+---------------------------------+---------------------+--------+| Charset | Description | Default collation | Maxlen |+----------+---------------------------------+---------------------+--------+| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 || dec8 | DEC West European | dec8_swedish_ci | 1 || cp850 | DOS West European | cp850_general_ci | 1 || hp8 | HP West European | hp8_english_ci | 1 || koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 || latin1 | cp1252 West European | latin1_swedish_ci | 1 || latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 || swe7 | 7bit Swedish | swe7_swedish_ci | 1 || ascii | US ASCII | ascii_general_ci | 1 || ujis | EUC-JP Japanese | ujis_japanese_ci | 3 || sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 || hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 || tis620 | TIS620 Thai | tis620_thai_ci | 1 || euckr | EUC-KR Korean | euckr_korean_ci | 2 || koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 || gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 || greek | ISO 8859-7 Greek | greek_general_ci | 1 || cp1250 | Windows Central European | cp1250_general_ci | 1 || gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 || latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 || armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 || utf8 | UTF-8 Unicode | utf8_general_ci | 3 || ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 || cp866 | DOS Russian | cp866_general_ci | 1 || keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 || macce | Mac Central European | macce_general_ci | 1 || macroman | Mac West European | macroman_general_ci | 1 || cp852 | DOS Central European | cp852_general_ci | 1 || latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 || utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 || cp1251 | Windows Cyrillic | cp1251_general_ci | 1 || utf16 | UTF-16 Unicode | utf16_general_ci | 4 || utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 || cp1256 | Windows Arabic | cp1256_general_ci | 1 || cp1257 | Windows Baltic | cp1257_general_ci | 1 || utf32 | UTF-32 Unicode | utf32_general_ci | 4 || binary | Binary pseudo charset | binary | 1 || geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 || cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 || eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 || gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 |+----------+---------------------------------+---------------------+--------+41 rows in set (0.00 sec)mysql> show character set 常见的字符集&编码:
Ascii字符集,GB2312字符集,gbk字符集,latin1字符集,unicode字符集等
3.5.2工作原理
注意: 如果通过客户端操作服务器,那么客户端与服务器之间进行数据通信,要保证编码一致。可以将互相发送的数据,转换成 目标可以接收的编码。
//1.客户端通过mysql的配置(my.ini):Character_set_client 客户端发送数据编码Character_set_results客户端接收数据的编码通过 指令 show variables like 'character_set_%';设置变量:Set 变量名=值Set character_set_client = gbk;告知服务器,客户端发送的数据是gbk编码执行 没有返回数据的语句没有问题了。//2.服务端如果需要从服务器返回数据,还需要设置服务器发送给客户端的编码Set character_set_results = gbk;服务器在发送数据时,才能转成客户端认识的编码统一的操作可以用 set names gbk可以完成。(简单项目通用的做法)//3.连接层其实还有一个有影响:连接层编码。Set character_set_connection = gbk;Set names 可以设置上面的三个。典型的情况,setnames即可。如果情况复杂,需要分开设置。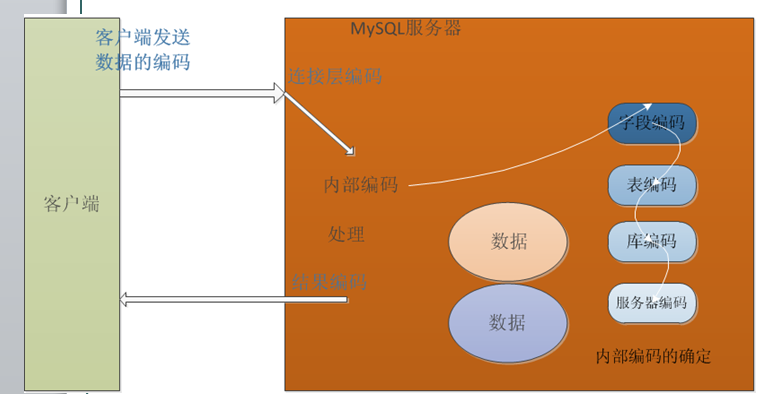
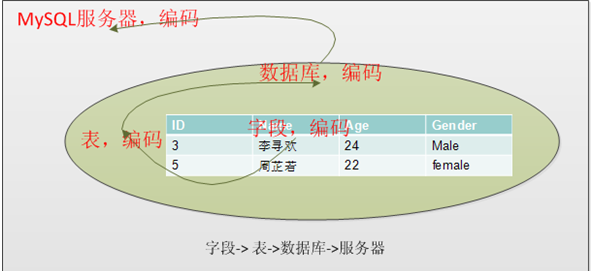
设置字符集类型的地方:
对字段,表,数据库,服务器进行字符集的设置,还可以设定连接字符集(客户端与服务器端交互时)
转换的过程
Client->connection->[服务器内部编码]->result
3.5.3 校对规则
校对规则: 当前字符集内,字符之间的比较关系, 默认都是_ci.
不同字符集有不同的校对规则,命名约定:以其相关的字符集名开始,通常包括一个语言名,并且以_ci(大小写不敏感)、_cs(大小写敏感)或_bin(二元)结束.
order by的时候会体现出来.
mysql> show collation like 'utf8%';+--------------------------+---------+-----+---------+----------+---------+| Collation | Charset | Id | Default | Compiled | Sortlen |+--------------------------+---------+-----+---------+----------+---------+| utf8_general_ci | utf8 | 33 | Yes | Yes | 1 || utf8_bin | utf8 | 83 | | Yes | 1 || utf8_unicode_ci | utf8 | 192 | | Yes | 8 || utf8_icelandic_ci | utf8 | 193 | | Yes | 8 || utf8_latvian_ci | utf8 | 194 | | Yes | 8 || utf8_romanian_ci | utf8 | 195 | | Yes | 8 || utf8_slovenian_ci | utf8 | 196 | | Yes | 8 || utf8_polish_ci | utf8 | 197 | | Yes | 8 || utf8_estonian_ci | utf8 | 198 | | Yes | 8 || utf8_spanish_ci | utf8 | 199 | | Yes | 8 || utf8_swedish_ci | utf8 | 200 | | Yes | 8 || utf8_turkish_ci | utf8 | 201 | | Yes | 8 || utf8_czech_ci | utf8 | 202 | | Yes | 8 || utf8_danish_ci | utf8 | 203 | | Yes | 8 || utf8_lithuanian_ci | utf8 | 204 | | Yes | 8 || utf8_slovak_ci | utf8 | 205 | | Yes | 8 || utf8_spanish2_ci | utf8 | 206 | | Yes | 8 || utf8_roman_ci | utf8 | 207 | | Yes | 8 || utf8_persian_ci | utf8 | 208 | | Yes | 8 || utf8_esperanto_ci | utf8 | 209 | | Yes | 8 || utf8_hungarian_ci | utf8 | 210 | | Yes | 8 || utf8_sinhala_ci | utf8 | 211 | | Yes | 8 || utf8_german2_ci | utf8 | 212 | | Yes | 8 || utf8_croatian_ci | utf8 | 213 | | Yes | 8 || utf8_unicode_520_ci | utf8 | 214 | | Yes | 8 || utf8_vietnamese_ci | utf8 | 215 | | Yes | 8 || utf8_general_mysql500_ci | utf8 | 223 | | Yes | 1 || utf8mb4_general_ci | utf8mb4 | 45 | Yes | Yes | 1 || utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 || utf8mb4_unicode_ci | utf8mb4 | 224 | | Yes | 8 || utf8mb4_icelandic_ci | utf8mb4 | 225 | | Yes | 8 || utf8mb4_latvian_ci | utf8mb4 | 226 | | Yes | 8 || utf8mb4_romanian_ci | utf8mb4 | 227 | | Yes | 8 || utf8mb4_slovenian_ci | utf8mb4 | 228 | | Yes | 8 || utf8mb4_polish_ci | utf8mb4 | 229 | | Yes | 8 || utf8mb4_estonian_ci | utf8mb4 | 230 | | Yes | 8 || utf8mb4_spanish_ci | utf8mb4 | 231 | | Yes | 8 || utf8mb4_swedish_ci | utf8mb4 | 232 | | Yes | 8 || utf8mb4_turkish_ci | utf8mb4 | 233 | | Yes | 8 || utf8mb4_czech_ci | utf8mb4 | 234 | | Yes | 8 || utf8mb4_danish_ci | utf8mb4 | 235 | | Yes | 8 || utf8mb4_lithuanian_ci | utf8mb4 | 236 | | Yes | 8 || utf8mb4_slovak_ci | utf8mb4 | 237 | | Yes | 8 || utf8mb4_spanish2_ci | utf8mb4 | 238 | | Yes | 8 || utf8mb4_roman_ci | utf8mb4 | 239 | | Yes | 8 || utf8mb4_persian_ci | utf8mb4 | 240 | | Yes | 8 || utf8mb4_esperanto_ci | utf8mb4 | 241 | | Yes | 8 || utf8mb4_hungarian_ci | utf8mb4 | 242 | | Yes | 8 || utf8mb4_sinhala_ci | utf8mb4 | 243 | | Yes | 8 || utf8mb4_german2_ci | utf8mb4 | 244 | | Yes | 8 || utf8mb4_croatian_ci | utf8mb4 | 245 | | Yes | 8 || utf8mb4_unicode_520_ci | utf8mb4 | 246 | | Yes | 8 || utf8mb4_vietnamese_ci | utf8mb4 | 247 | | Yes | 8 |+--------------------------+---------+-----+---------+----------+---------+53 rows in set (0.00 sec)mysql> 3.6.实体关系
3.6.1 实体关系分类
- 1:1
- 1:N
- M:N
3.6.2 外键
3.6.2.1 定义
如果一个实体的(people)的某个字段(people:country_id),指向(引用)另个实体(country)的主键(country:id),
就称 people实体的country_id是外键。 [人属于某个唯一国家]
被指向的实体,称之为 主实体(主表),也叫父实体(父表)。country
负责指向的实体,称之为 从实体(从表),也叫子实体(子表)。people
3.6.2.2 作用
保证数据的完整性。用于约束处于关系内的实体。
增加子表记录时,是否有与之对应的父表记录。
在删除或者更新主表记录时,从表应该如何处理相关的记录。
3.6.2.3 定义一个外键:
在从表上,增加一个外键字段,指向主表的主键。
使用关键字 foreign keyForeign Key (外键字段) references 主表名 (关联字段) [主表记录删除时的动作] [主表记录更新时的动作] //使用举例,table_people从表;table_contry主表create table_people(privty id int private key auto_increment,foreign_key_name foreign key (contry_id ) references table_contry(id))3.6.2.4 外键操作
- 类型:
On update
On delete 选项:
Cascade: 关联操作,如果主表被更新或删除,那么从表也会执行相应的操作。
Set null: 设置为null,表示从表不指向任何主表记录。
Restrict:拒绝主表的相关操作。修改外键
一般为先删除再新增.
//可以同时书写修改和删除时的操作create table_people(privty id int private key auto_increment,foreign_key_name foreign key (contry_id ) references table_contry(id) on update set null on delete retrict)//修改alter table table_people drop foreign key;alter table table_people add foreign key(contry_id) references table_contry(id) on update restrict on delete cascade;3.7.视图
//创建视图Create view view_name AS select_statement; CREATE /*[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] [DEFINER = { user | CURRENT_USER }] [SQL SECURITY { DEFINER | INVOKER }]*/ VIEW `bobshutetest`.`viewa` AS(SELECT * FROM test_table t WHERE t.id <10);//删除视图Drop view [if exists] view_name;//修改视图修改是先删除然后新建//查看视图的创建语句 show create view viewname;//查看当前所有的视图select * from information_schema.VIEWS;- 视图的执行算法:
undefined:未定义(默认的),这不是一种实际使用的算法,是一种推卸责任的算法—-告诉系统,视图没有定义算法,你看着办。
temptable:临时表算法;系统应该先执行视图的select语句,后执行外部查询的语句。
merge:合并算法;系统应该先将视图对应的select语句与外部查询视图的select语句进行合并,然后执行(效率高),系统默认值。
//创建视图时指定算法create algorithm = 指定算法 view view_name as select ...3.8.触发器
//触发器必须有名字,最多64个字符,可能后面会附有分隔符.它和MySQL中其他对象的命名方式基本相象.
CREATE TRIGGER <触发器名称>
//触发器有执行的时间设置:可以设置为事件发生前或后。
{ BEFORE | AFTER }
//同样也能设定触发的事件:它们可以在执行insert、update或delete的过程中触发。
{ INSERT | UPDATE | DELETE }
//触发器是属于某一个表的:当在这个表上执行插入、 更新或删除操作的时候就导致触发器的激活. //我们不能给同一张表的同一个事件安排两个触发器。
ON <表名称>
//触发器的执行间隔:FOR EACH ROW子句通知触发器 每隔一行执行一次动作,而不是对整个表执行一次。
FOR EACH ROW
//触发器包含所要触发的SQL语句:这里的语句可以是任何合法的语句,包括复合语句,但是这里的语句受的限制和函数的一样,如果是修改前后的数据通过new和old来区分
<触发器SQL语句>
//创建触发器CREATE TRIGGER trigger_nametrigger_timetrigger_event ON tbl_nameFOR EACH ROWtrigger_stmt(可以用new或old)trigger_name:标识触发器名称,用户自行指定;trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句。对数据处理可以通过new或old来区分修改前后的数据Old:监听事件所在表上的数据,在事件发生之前时的数据。旧的数据。New:监听表上,事件发生之后,新处理完毕的数据。由此可见,可以建立6种触发器,即:BEFORE INSERT、BEFORE UPDATE、BEFORE DELETE、AFTER INSERT、AFTER UPDATE、AFTER DELETE。另外有一个限制是不能同时在一个表上建立2个相同类型的触发器,因此在一个表上最多建立6个触发器。//删除触发器Drop trigger trigger_name;//查看当前触发器sqlShow create trigger trigger_name; //查看当前数据库中的触发器SHOW TRIGGERS [FROM schema_name];//通过sqlyog自动生成的语法,可以添加多长的触发器,首先修改定义sql结束符$$,使用完之后再修改回去;DELIMITER $$CREATE /*[DEFINER = { user | CURRENT_USER }]*/ TRIGGER `bobshutetest`.`triggera` BEFORE/AFTER INSERT/UPDATE/DELETE ON `bobshutetest`.`<Table Name>` FOR EACH ROW BEGIN END$$DELIMITER ;举例DELIMITER $$create trigger tg4after update on ofor each rowbeginupdate g set num = num+old.much-new.much where id = old/new.gid;end$$DELIMITER ;3.9 分区
语法如下
create table table1 ( id int, name char(10) )engine myisam charset utf8 partition by range(id) ( partition p1 values less than (1000), partition p2 values less than (2000), partition p3 values less than MAXVALUE ); 分区后结果会发现如果mysiam类型,则会有多个myd和myi,此时文件分布如下: table1.frm,table1.par,table#P#t0.MYD,table#P#t0.MYI,table#P#t1.MYD,table#P#t1.MYI,table#P#t2.MYD,table#P#t2.MYI, create table table2 ( id int, type char(10) )engine myisam charset utf8 partition by list(type) ( partition type1 values in ('typea'), partition type2 values in ('typeb'), partition type3 values in ('typec','typed') ); 注意这种情况如果值是typea,typeb,typec,typed之外的值,插入会报错. 当然还可以根据时间来分区注意: 查询时需要带上分区的列才更快.
4 表数据操作(DQL,DML)
4.1 基本语法
//插入insert into table_name (字段列表) value(值列表)//查询slect * from table_name;//删除delete from table_name 条件//修改Update 表名 set 字段=新值, … 条件。4.2 插入数据
插入多条数据1.基本语法insert into table_name (字段列表) value(值列表);//没用写到的列用默认值,如果不能为空则报错2.插入多条数据insert into tableA (columnA,columnB) values ('columnAvalue1', 'columnBvalue1'),('columnAvalue2', 'columnBvalue2');3.插入部分字段(set的方式),注意:插入式不能用别名INSERT INTO test_table SET NAME = 'name1',score_new = 100 ;4.插入失败(主键冲突时)可以改成执行修改INSERT INTO test_table (`id`, `name`, `score_new`) VALUES (10, 'name', 100) ON DUPLICATE KEY UPDATE name = 'newname', score_new = 100 ;5.insert into select 查询结果直接插入,查询的结果的个数和类型与插入保持一致insert into tableA(column1, column2) select column1,column2from tableB;6.replace,如果主键冲突则修改替换,替换结果是全部字段替换(也就是说如果有的列没写,那就是这些列为空值了)REPLACE INTO test_table (id,NAME,score_new)VALUES(7, 'name7', 30);7.load file 见后面load file;4.3 修改数据
//修改基础语法Update 表名 set 字段=新值, … 条件。//修改多条数据UPDATE tablea JOIN tableb ON tablea.public_column = tableb.public_column SET tablea.column1 = 'value1', talbeb.column2 = 'valueb' WHERE tablea.column2 = '1' ;//插入失败(主键冲突时)可以改成执行修改INSERT INTO test_table (`id`, `name`, `score_new`) VALUES (10, 'name', 100) ON DUPLICATE KEY UPDATE name = 'newname', score_new = 100 ;4.4 删除数据
//删除全表数据DELETE FROM test_table;//删除第一条DELETE FROM test_table LIMIT 1; //删除排序后的第一条,如果要排序删除,必须limit,否则排序无效DELETE FROM test_table ORDER BY id DESC LIMIT 1; //删除多表中的数据delete from tabalea,tableb using tablea join tableb on tablea.public_column = tableb.public_column where xxx//删除整张表数据,删除表并重建Truncate table ;- Truncate和delete的区别
4.5 查询数据
4.5.1 基本查询详解
4.5.1.1 基础
select [查询选项] [查询表达式(字段表达式)] [from 子句] [where 子句] [group by 子句] [having 子句] [order by 子句] [limit 子句]
[as] 别名,
dual 虚表
where 数据过滤,理解上,数据安装交叉连接连接完成后,再做数据过滤。
having
using Using 要求,负责连接的两个实体之间的字段名称,一致。
on 在连接时,就对数据进行判断。
Order by Order by 字段 升序|降序(asc|desc) 默认 升序,asc
limit Limit offset(偏移量,默认0,可以忽略),row_count(查询显示记录数),从offset开始查询后面row_count行
distinct 去重
Union 结果去重,需要上线语句列数及类型一致
Union all 结果不去重. 如果需要排序order by,则各子句需要limit,否则各自排序忽略. 或查出来之后在最后加order by 即可.
select tableA,tableB using(public_field)4.5.1.2 运算符
关系运算符
= > < >= <= != like _ % \% \_ (查%或_用\转义)Is null is not nullBetween andIn|not in (集合元素)<=> 功能与 =一致,特别的功能在于 可以比较null值。 select null<=>null,1<=>null 返回 1 ,0Interval(值, 元素1, 元素2, 元素N);依次判断值,与元素之间的大小关系,如果值,小于元素1,则返回0;如果值小于元素2 则返回1,依次类推。SELECT INTERVAL(5,10,3,15,1); ##//0,大于5的坐标,从0开始坐标SELECT INTERVAL(5,2,3,15,1); ##//2SELECT INTERVAL(5,2,3,2,6); ##//3逻辑运算符
And && Or || Not ! Xor非:not !,非null 为null。与:and &&,有0就是0,都是非零为1,存在null与非零则为null。或:or || , null||null=null null||1=1 null||0=null异或: xor ,有null,就是null优先级最好通过()来区分
4.5.2 聚合分组查询
groupby ( with rollup )Sum() Avg() Max(); Min(); Count() Group_concat()[分组结果通过,连接]where先执行,group by 后执行//根据dep,pos统计平均值mysql> select dep,pos,avg(sal) from employee group by dep,pos; +------+------+-----------+ | dep | pos | avg(sal) | +------+------+-----------+ | 01 | 01 | 1500.0000 | | 01 | 02 | 1950.0000 | | 02 | 01 | 1500.0000 | | 02 | 02 | 2450.0000 | | 03 | 01 | 2500.0000 | | 03 | 02 | 2550.0000 | +------+------+-----------+ 6 rows in set (0.02 sec) //with rollup 是根据dep,pos统计平均值后,再根据dep统计一次平均值mysql> select dep,pos,avg(sal) from employee group by dep,pos with rollup; +------+------+-----------+ | dep | pos | avg(sal) | +------+------+-----------+ | 01 | 01 | 1500.0000 | | 01 | 02 | 1950.0000 | | 01 | NULL | 1725.0000 | | 02 | 01 | 1500.0000 | | 02 | 02 | 2450.0000 | | 02 | NULL | 2133.3333 | | 03 | 01 | 2500.0000 | | 03 | 02 | 2550.0000 | | 03 | NULL | 2533.3333 | | NULL | NULL | 2090.0000 | +------+------+-----------+ 10 rows in set (0.00 sec) 4.5.3 Exists
4.5.3.1 Exists语法
Exists(subquery) 判断依据:如果子查询的 可以返回数据,则认为 exists 表达式 返回真。否者,返回假4.5.3.2 exist与in的区别
- exists: 先获得每一条 teacher_class的数据,然后获得id字段,去teacher表内查找对应值,找到,
说明符合条件。 - in:先获得所有的id的可能性。再在检索teacher_class数据时,判断当前的id是否在id集合内。
4.5.4 连接查询
- join = inner join ** On
- cross join ** on
- (left/right)outer join ** on
- Using
- 自然连接 笛卡尔
select tableA left join tableB ;//外连接多次查询SELECT s.*, si.* FROM tableA AS ta LEFT JOIN tableB AS tb ON ta.id = tb.class_id LEFT JOIN tableC AS tc ON ta.id = tci.id WHERE ta.class_name = 'searchvalue' ;4.6 备份还原数据
4.6.1 OUTFILE
- 导出数据
SELECT ... FROM TABLE_A where INTO OUTFILE "/path/to/file"FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' //修改每列的分隔符,行之间列的分隔符,和数据结束符 LINES TERMINATED BY '\n'; //修改行结束符号 也可以 SELECT INTO OUTFILE "/path/to/file" .. FROM TABLE_A where FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' //修改每列的分隔符 ,行之间列的分隔符,和数据结束符 LINES TERMINATED BY '\n'; //修改行结束符号 select * into dumpfile path 导出二进制数据,格式同上 - 导入数据
LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name' [REPLACE | IGNORE] INTO TABLE tbl_name [PARTITION (partition_name,...)] [CHARACTER SET charset_name] [{FIELDS | COLUMNS} [TERMINATED BY 'string'] [[OPTIONALLY] ENCLOSED BY 'char'] [ESCAPED BY 'char'] ] [LINES [STARTING BY 'string'] [TERMINATED BY 'string'] ] [IGNORE number {LINES | ROWS}] [(col_name_or_user_var,...)] [SET col_name = expr,...]LOAD DATA INFILE “/path/to/file” INTO TABLE table_name;
注意:如果导出时用到了FIELDS TERMINATED BY ‘,’ OPTIONALLY ENCLOSED BY ‘”’ LINES TERMINATED BY ‘\n’语句,那么LODA时也要加上同样的分隔限制语句。还要注意编码问题
//导出数据 执行的时候发生的提示 mysql> select * from test_table where id<10 into outfile 'd:/fileout/ourdata' ;ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementmysql>//解决办法:mysql> SHOW GLOBAL VARIABLES LIKE '%secure%';+--------------------------+------------------------------------------------+| Variable_name | Value |+--------------------------+------------------------------------------------+| require_secure_transport | OFF || secure_auth | ON || secure_file_priv | C:\ProgramData\MySQL\MySQL Server 5.7\Uploads\ |+--------------------------+------------------------------------------------+3 rows in set, 1 warning (0.00 sec)//所以说明只能导入到secure_file_priv目录下,这么操作执行完成mysql> select * into outfile 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/ourdata' from test_table where id<10;Query OK, 2 rows affected (0.00 sec)//这么写也能成功mysql>select * from test_table where id<10 into outfile 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/ourdata2' ;//数据导出后如下(\N是空字段)1,"a",444444444,"2",\N,0000000000000000001234,"2017-10-22 11:32:01",\N,\N2,"b",00022,"44",\N,000011111.333333333334,\N,"2017-10-22 11:34:45","85:32:33"//导出二进制数据(同导出普通数据)select t.blob into dumpfile 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/ourdata2' from table t where t.column='' limit 1; //数据导入,删除备份的表后重新导入数据mysql>load data infile 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/ourdata4' into table test_table fields terminated by ',' enclosed by '"' lines terminated by '\n' ; 4.6.2 mysqldump
mysqldump导出数据
通过source恢复数据
//基本语法mysqldump -u -p --no-create-info --tab=. --fields-terminated-by=, --fields-optionally-enclosed-by=\" db_name tb_name//备份某一个完整的数据库C:\Users\user>mysqldump -uroot -p bobshutetest >d:\\bobshutetest.sqlEnter password: ******//备份某个数据库中的某个表 C:\Users\shubb>mysqldump -uroot -p bobshutetest test_table >d:\\test_table.sqlEnter password: ******//备份某个数据库中的多个表 C:\Users\shubb>mysqldump -uroot -p bobshutetest test_table test_table2 test_table3 >d:\\test_table.sqlEnter password: ******//恢复数据mysql> use bobshutetest;Database changedmysql> source d:\\test_table.sqlQuery OK, 0 rows affected (0.00 sec)4.6.3 mysiam存储引擎的方式复制备份
直接将 tbl_name.frm, Tbl_name.myd,Tbl_name.myi 三个文件,保存,备份即可。
恢复后注意的是索引需要重建(磁盘位置已经不一样)
- Mysql总结2-mysql基础(DQL,DML,DDL,DCL)
- MySQL之DDL,DQL,DML,DCL
- MySQL中的DDL、DML、DCL、DQL
- DML-DDL-DQL-DCL
- DDL,DQL,DCL,DML
- dml dcl ddl dql
- DDL、DML、DCL、DQL
- DDL&DML&DQL&DCL
- MySQL-基础-DDL、DML、DCL、TCL详解
- mysql 基础 ddl dml 总结
- 什么是DQL、DML、DDL、DCL
- 什么是DQL、DML、DDL、DCL
- 什么是DQL、DML、DDL、DCL
- 什么是DQL、DML、DDL、DCL
- 什么是DQL、DML、DDL、DCL
- 什么是DQL、DML、DDL、DCL
- 什么是DQL、DML、DDL、DCL
- 区分DML,DDL,DCL,DQL
- Super this 关键字
- 设计模式(单例设计模式)
- 面向对象知识点小记(2)
- 安装laravel-admin产生不了app\Admin文件问题
- final finalize 关键字
- Mysql总结2-mysql基础(DQL,DML,DDL,DCL)
- java基础之认识内部类(未修订)
- 15.14
- 自然语言处理快速入门
- Linux命令集合二
- 20171030
- python学习(3)anaconda的介绍 以及 Spyder 的 IPython 的%魔术命令
- HTML基础 超链接基础2
- 使用sysbench对Mysql进行压力测试查询性能


