hadoop面试总结
来源:互联网 发布:达内 构java 编辑:程序博客网 时间:2024/05/22 10:51
1、简要描述如何安装配置一个开源的hadoop,只描述即可,列出完整步骤。
a、创建一个用户和用户组,用来管理hadoop项目
b、修改确定ip地址:vim /etc/sysconfig/network-scripts/ifcfg-eth0
c、修改主机名:vim /etc/sysconfig/network
d、修改host主机名和ip地址映射:vim /etc/hosts
e、查看防火墙状态并关闭防火墙:
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
f、安装ssh并配置免密码登录:ssh-keygen -t rsa
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免登陆的机器上
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
或
ssh-copy-id -i localhost
g、上传并安装jdk: tar -zxvf jdk**.tar.gz -C /user/java/ 修改/etc/profile文件,配置java环境变量
h、安装hadoop: tar -zxvf hadoop....tar.gz
i、配置conf文件下:
对于hadoop1.*版本(hadoop-env.sh,core-site.xml,hdfs-site.xml,mapred-site.xml)
对于hadoop2.*版本(hadoop-env.sh,core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml,slaves文件)
j、安装配置zookeeper集群
k、格式namenode
对于hadoop1.*版本 :hadoop namenode -format
对于hadoop2.*版本 :hdfs namenode -format
2、请列出正常的工作的hadoop集群中hadoop都分别需要启动哪些进程,他们的作用分别是什么。
对于hadoop1.*版本 :
a. NameNode
它是Hadoop 中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问。
b. SecondaryNameNode
它不是 namenode 的冗余守护进程,而是提供周期检查点和清理任务。
出于对可扩展性和容错性等考虑,我们一般将SecondaryNameNode运行在一台非NameNode的机器上。
c. DataNode
它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个 datanode 守护进程。
d. JobTracker和TaskTracker
JobTracker负责调度 DataNode上的工作。每个 DataNode有一个TaskTracker,它们执行实际工作。
JobTracker和 TaskTracker采用主-从形式,JobTracker跨DataNode分发工作,而TaskTracker执行任务。
JobTracker还检查请求的工作,如果一个 DataNode由于某种原因失败,JobTracker会重新调度以前的任务。
对于hadoop2.*版本 :
会启动NameNode、DFSZKFailoverController ,ResourceManager,DataNode、NodeManager、JournalNode
3、
4、请写出一下的执行命令
1)杀死一个job
kill -9 jobId
2)删除hdfs上的/tmp/aaa目录
hadoop fs -rmr /tmp/aaa
3)加入一个新的存储接口和删除一个计算机节点需要刷新集群状态命令
hadoop-daemon.sh start datanode
hadoop-daemon.sh start tasktracker
删除时:
hadoop mradmin -refreshnodes
hadoop dfsadmin -refreshnodes
5、请列出你所知道的hadoop调度器,并且简要说明其工作方法。
比较流行的三种调度器有:默认调度器FIFO,计算能力调度器Capacity Scheduler ,公平调度器Fair Scheduler
1) 默认调度器FIFO
hadoop中默认的调度器,采用先进先出的原则
2) 计算能力调度器Capacity Scheduler
选择占用资源小,优先级高的先执行
3) 公平调度器Fair Scheduler
同一队列中的作业公平共享队列中所有资源
6、请列出在你以前的工作中所使用过的开发map/reduce的语言。
java python,scala
7、当前的日志采样格式为:
a,b,c,d
b,b,f,e
a,a,c,f
请用你最熟悉的语言编写一个map/reduce程序,计算第四列每个元素出现的个数。
8、你认为用java,Streaming,pipe方式开发map/reduce,各有哪些缺点。
9、hive有哪些方式保存元素据,各有哪些特点。
1) 内存数据库derby,较小,不常用
2) 本地mysql,较常用
3) 远程mysql,不常用
10、请简述hadoop怎样实现二级排序。
在Hadoop中,默认情况下是按照key进行排序,如果要按照value进行排序怎么办?
有两种方法进行二次排序,分别为:buffer and in memory sort和 value-to-key conversion。
buffer and in memory sort
主要思想是:在reduce()函数中,将某个key对应的所有value保存下来,然后进行排序。
这种方法最大的缺点是:可能会造成out of memory。
value-to-key conversion
主要思想是:将key和部分value拼接成一个组合key(实现WritableComparable接口或者调 setSortComparatorClass函数),
这样reduce获取的结果便是先按key排序,后按value排序的结果,需要注意的是,
用户需 要自己实现Paritioner,以便只按照key进行数据划分。Hadoop显式的支持二次排序,
在Configuration类中有个 setGroupingComparatorClass()方法,可用于设置排序group的key值
11、简述hadoop实现join的几种方法。
1) reduce side join
reduce side join是一种最简单的join方式,其主要思想如下:
在map阶段,map函数同时读取两个文件File1和File2,为了区分两种来源的key/value数据对,对每条数据打一个标签 (tag),
比如:tag=0表示来自文件File1,tag=2表示来自文件File2。即:map阶段的主要任务是对不同文件中的数据打标签。
在reduce阶段,reduce函数获取key相同的来自File1和File2文件的value list, 然后对于同一个key,
对File1和File2中的数据进行join(笛卡尔乘积)。即:reduce阶段进行实际的连接操作。
2) map side join
之所以存在reduce side join,是因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中。
Reduce side join是非常低效的,因为shuffle阶段要进行大量的数据传输。
Map side join是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,
以至于小表可以直接存放到内存中。这样,我们可以将小表复制多 份,让每个map task内存中存在一份(比如存放到hash table中),
然后只扫描大表:对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。
为了支持文件的复制,Hadoop提供了一个类DistributedCache,使用该类的方法如下:
(1)用户使用静态方法DistributedCache.addCacheFile()指定要复制的文件,它的参数是文件的URI(如果是 HDFS上的文件,可以这样:hdfs://namenode:9000/home/XXX/file,
其中9000是自己配置的NameNode端口 号)。JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘上。
(2)用户使用 DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写API读取相应的文件。
3) SemiJoin
SemiJoin,也叫半连接,是从分布式数据库中借鉴过来的方法。它的产生动机是:对于reduce side join,跨机器的数据传输量非常大,
这成了join操作的一个瓶颈,如果能够在map端过滤掉不会参加join操作的数据,则可以大大节省网络IO。
实现方法很简单:选取一个小表,假设是File1,将其参与join的key抽取出来,保存到文件File3中,File3文件一般很小,
可以放 到内存中。在map阶段,使用DistributedCache将File3复制到各个TaskTracker上,然后将File2中不在File3中的 key对应的记录过滤掉,
剩下的reduce阶段的工作与reduce side join相同。
更多关于半连接的介绍,可参考:半连接介绍:
4) reduce side join + BloomFilter
在某些情况下,SemiJoin抽取出来的小表的key集合在内存中仍然存放不下,这时候可以使用BloomFiler以节省空间。
BloomFilter最常见的作用是:判断某个元素是否在一个集合里面。它最重要的两个方法是:add() 和contains()。
最大的特点是不会存在false negative,即:如果contains()返回false,则该元素一定不在集合中,但会存在一定的true negative,
即:如果contains()返回true,则该元素可能在集合中。
因而可将小表中的key保存到BloomFilter中,在map阶段过滤大表,可能有一些不在小表中的记录没有过滤掉(但是在小表中的记录一定不会过滤掉),
这没关系,只不过增加了少量的网络IO而已。
12、请用java实现非递归二分查找。
13、请简述mapReduce中combiner,partiton作用
14、某个目录下有两个文件a.txt和b.txt 文件格式为一下,列如:
a.txt
127.0.0.1 zhangsan
127.0.0.1 wangxiaoer
127.1.1.2 lisi
127.0.0.5 wangwu
b.txt
127.0.0.4 lixiaolu
127.0.0.1 lisi
每个文件至少有100万行,请使用linux命令行完成一下工作:
1)两个文件各自的ip数,以及总的ip数
2)出现在b.txt而没有出现在a.txt的ip
3) 每个username出现的次数,以及每个username对应的ip数。
15、hive内部表和外部表的区别
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,
不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,
而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
16、Hbase 的 rowkey 怎么创建比较好?列族怎么创建比较好?
rowkey设计原则
1)Rowkey的长度原则: 是一个二进制码流,Rowkey 的长度被很多开发者建议说设计在10~100 个字节,不过建议是越短越好,不要超过16 个字节。
2)Rowkey散列原则:如果Rowkey 是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,
这样将提高数据均衡分布在每个Regionserver 实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个 RegionServer 上堆积的热点现象,
这样在做数据检索的时候负载将会集中在个别RegionServer,降低查询效率。
3)Rowkey唯一原则:必须在设计上保证其唯一性。
列族设计原则
1)一般不建议设计多个列族。具体原因如下
假如HBase表的表设置两个列族,若已一个列族1000万行,另一个列族100行。当一个要求region分裂时候,会导致100行的列会同样分布到多个region中。
这样就出现基数问题,会导致扫描列族A的性能低下。某个列族在flush的时候,它邻近的列族也会因关联效应出发flush,最终导致系统产生更多的I/O。
HBase本身的设计目标是支持稀疏表,而稀疏表通常会有很多列,但是每一行有值的列又比较少。在HBase中Column Family的数量通常很小,
同时HBase建议把经常一起访问的比较类似的列放在同一个Column Family中,这样就可以在访问少数几个列时,只读取尽量少的数据。
在设计Hbase schema的时候,要尽量只有一个column family,至于为什么主要从flush和compaction说起,它们触发的基本单位都是Region级别,
所以当一个column family有大量的数据的时候会触发整个region里面的其他column family的memstore(其实这些memstore可能仅有少量的数据,
还不需要flush的)也发生flush动作;另外compaction触发的条件是当store file的个数(不是总的store file的大小)达到一定数量的时候会发生,
而flush产生的大量store file通常会导致compaction,flush/compaction会发生很多IO相关的负载,这对Hbase的整体性能有很大影响,所以选择合适的column family个数很重要。
2)数据块缓存配置
如果经常顺序访问或者很少访问,可以关闭列族的缓存,让BLOCKCACHE 参数设置false,列族缓存默认打开。
>create 'mytable',{NAME=>'colfam1',BLOCKCACHE=>'false'}
3)激进缓存配置
可以选择一个列族赋予更高的缓存,该参数IN_MEMORY 设置true。列族默认的关闭的。如果你预期一个列族比另一个列族的随机读更多,这个特性迟早用的上。
>create 'mytable',{NAME=>'colfam1',IN_MEMORY=>'true'}
4)布隆过滤器(BLOOMFILTER)设置
减少硬盘读取数据带来的开销。对存储的数据块做反向测试,占用额外的空间。
布隆过滤器随着它们索引的对象数据的增长而增长,所以行级布隆过滤器比列限定符级布隆过滤器占用空间要少。当空间不是问题时,它们可以帮助你“榨干”系统的性能潜力。
>create 'mytable',{NAME=>'colfam1',BLOOMFILTER=>'ROWCOL'}
BLOOMFILTER默认参数为NONE。一个行级布隆过滤器用ROW启动,列限定级布隆过滤器用ROWCOL启动。行级布隆过滤器在数据快里检查特定行键是否存在,
列限定符级布隆过滤器检查行与列限定符组合是否不存在。ROWCOL布隆过滤器的开销高于ROW布隆过滤器。
5)生产时间配置
超过这个时间设置的就会在下一次大合并中被删除。TTL =>"18000"。你可以禁用TTL,或者通过设置其值为INT.MAX_VALUE(2147483647)让它永远启用(这是默认值)。
>create 'mytable',{NAME=>'colfam1',TTL=>'1800'}
6)列族压缩
压缩可以节省空间,读写数据会增加CPU的使用率 LZO,SNAPPY,GZIP(不常用)。
>create 'mytable',{NAME=>'colfam1',COMPRESSION=>'SNAPPY'}
注意,数据只在硬盘上是压缩的,在内存(MemStore或BlockCache)或通过网络传输是是没有压缩的。
7)单元时间版本
默认为3个版本,来保存历史数据。如果只需要哟个版本,推荐设置表时只维护一个版本。
>create 'mytable',{NAME=>'colfam1',VERSION=>1,TTL=>'1800'}
也可以指定列族存储的最少时间版本数:
>create 'mytable',{NAME=>'colfam1',VERSION=>5,MIN_VERSIONS=>'1'}
17、用 mapreduce 怎么处理数据倾斜问题?
首先要定位到哪些数据 导致数据倾斜。确定完之后常见的处理方法有:
1. 在加个combiner函数,加上combiner相当于提前进行reduce,就会把一个mapper中的相同key进行了聚合,减少shuffle过程中数据量,
以及reduce端的计算量。这种方法可以有效的缓解数据倾斜问题,但是如果导致数据倾斜的key 大量分布在不同的mapper的时候,这种方法就不是很有效了。
2. 局部聚合加全局聚合。第二种方法进行两次mapreduce,第一次在map阶段对那些导致了数据倾斜的key 加上1-n的随机前缀,
这样之前相同的key 也会被分到不同的reduce中,进行聚合,这样的话就有那些倾斜的key进行局部聚合,数量就会大大降低。
然后再进行第二次mapreduce这样的话就去掉随机前缀,进行全局聚合。这样就可以有效地降低mapreduce了。
不过进行两次mapreduce,性能稍微比一次的差些。自己的想法,还请大家多多讨论,
18、Hbase内部机制
客户端连接hbase依赖于zookeeper,hbase存储依赖于hadoop
client:
1、包含访问 hbase 的接口, client 维护着一些 cache(缓存)来加快对 hbase 的访问,比如 region 的 位置信息。 (经常使用的表的位置信息)
zookeeper:
1、保证任何时候,集群中只有一个 master
2、存贮所有 Region 的寻址入口----root 表在哪台服务器上。 -root-这张表的位置信息
3、实时监控 RegionServer 的状态,将 RegionServer 的上线和下线信息实时通知给 Master
4、存储 Hbase 的 schema(表的描述信息),包括有哪些 table,每个 table 有哪些 column family
master职责:
1、为 RegionServer 分配 region
2、负责 RegionServer 的负载均衡
3、发现失效的 RegionServer 并重新分配其上的 region
4、 HDFS 上的垃圾文件( hbase)回收
5、处理 schema 更新请求(增加,删除,修改)( JDBC:crud)
RegionServer 职责
1、 RegionServer 维护 Master 分配给它的 region,处理对这些 region 的 IO 请求
2、 RegionServer 负责切分在运行过程中变得过大的 region
可以看到, client 访问 hbase 上数据的过程并不需要 master 参与(寻址访问 zookeeper 和 RegioneServer,数据读写访问 RegioneServer),
master 仅仅维护者 table 和 region 的元数据 信息,负载很低。
.meta. 存的是所有的 region 的位置信息,那么 RegioneServer 当中 region 在进行分裂之后 的新产生的 region,
是由 master 来决定发到哪个 RegioneServer,这就意味着,只有 master 知道 new region 的位置信息,
所以,由 master 来管理.meta.这个表当中的数据的 CRUD
19、hdfs数据压缩算法
Hadoop中常用的压缩算法有bzip2、gzip、lzo、snappy,其中lzo、snappy需要操作系统安装native库才可以支持
下面这张表,是比较官方一点的统计,不同的场合用不同的压缩算法。bzip2和GZIP是比较消耗CPU的,
压缩比最高,GZIP不能被分块并行的处理;Snappy和LZO差不多,稍微胜出一点,cpu消耗的比GZIP少。
20、hive 底层与数据库交互原理
1)用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是CLI,Cli启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,
用户连接至Hive Server。在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。 WUI是通过浏览器访问Hive。
2)Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
Hive将元数据存储在RDBMS中,
21、hbase 过滤器实现原则
Hbase为筛选数据提供了一组过滤器,通过这个过滤器可以在hbase中的数据的多个维度(行,列,数据版本)上进行对数据的筛选操作,
也就是说过滤器最终能够筛选的数据能够细化到具体的一个存储单元格上(由行键,列明,时间戳定位)。通常来说,通过行键,
值来筛选数据的应用场景较多。
22、datanode 在什么情况下不会备份
设置副本数只有1个时。
23、combine 出现在那个过程?
Combiner 所做的事情:
每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量;
Combiner 的意义:
在MapReduce中,当map生成的数据过大时,带宽就成了瓶颈,当在发送给 Reduce 时对数据进行一次本地合并,
减少数据传输量以提高网络IO性能;
Combiner 的时机:
Combiner 最基本的是实现本地key的聚合,有本地 Reduce 之称
,实际上是现实就继承来 Reducer ,本质上就是一个 Reducer。
24、hdfs的体系结构。
我们首先介绍HDFS的体系结构,HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。
其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。
HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存放在一组DataNode上。
NameNode执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,
它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,
并在NameNode的统一调度下进行数据块的创建、删除和复制工作。图1-3给出了HDFS的体系结构。

NameNode和DataNode都被设计成可以在普通商用计算机上运行。
这些计算机通常运行的是GNU/Linux操作系统。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署NameNode和DataNode。
一个典型的部署场景是集群中的一台机器运行一个NameNode实例,其他机器分别运行一个DataNode实例。
当然,并不排除一台机器运行多个DataNode实例的情况。集群中单一的NameNode的设计则大大简化了系统的架构。
NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
25、MapReduce的主要的六个类讲解
a、InputFormat类。该类的作用是将输入的文件和数据分割成许多小的split文件,
并将split的每个行通过LineRecorderReader解析成<Key,Value>,通过job.setInputFromatClass()函数来设置,
默认的情况为类TextInputFormat,其中Key默认为字符偏移量,value是该行的值。
b、Map类。根据输入的<Key,Value>对生成中间结果,默认的情况下使用Mapper类,
该类将输入的<Key,Value>对原封不动的作为中间按结果输出,通过job.setMapperClass()实现。实现Map函数。
c、Combine类。实现combine函数,该类的主要功能是合并相同的key键,通过job.setCombinerClass()方法设置,
默认为null,不合并中间结果。实现map函数
d、partitioner类。 该该主要在Shuffle过程中按照Key值将中间结果分成R份,其中每份都有一个Reduce去负责,
可以通过job.setPartitionerClass()方法进行设置,默认的使用hashPartitioner类。实现getPartition函数
e、Reducer类。 将中间结果合并,得到中间结果。通过job.setReduceCalss()方法进行设置,默认使用Reducer类,实现reduce方法。
f、OutPutFormat类,该类负责输出结果的格式。可以通过job.setOutputFormatClass()方法进行设置。
默认使用TextOUtputFormat类,得到<Key,value>对。
note:hadoop主要是上面的六个类进行mapreduce操作,使用默认的类,处理的数据和文本的能力很有限,
具体的项目中,用户通过改写这六个类(重载六个类),完成项目的需求。说实话,我刚开始学的时候,
我怀疑过Mapreudce处理数据功能,随着学习深入,真的很钦佩mapreduce的设计,基本就二个函数,通过重载,
可以完成所有你想完成的工作。
26、WordCount处理过程
本节将对WordCount进行更详细的讲解。详细执行步骤如下:
1)将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,如图4-1所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)。

图4-1 分割过程
2)将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如图4-2所示。
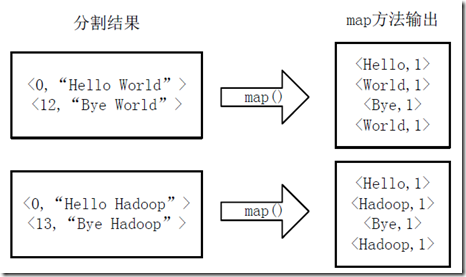
图4-2 执行map方法
3)得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果。如图4-3所示。

图4-3 Map端排序及Combine过程
4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如图4-4所示。
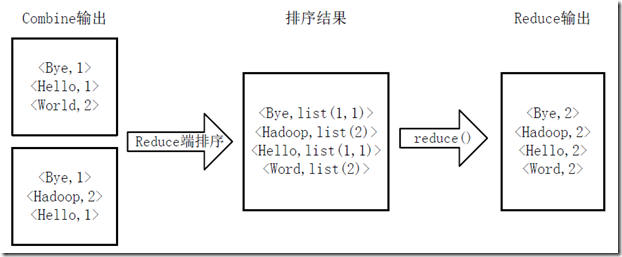
图4-4 Reduce端排序及输出结果
阅读全文
0 0
- hadoop面试总结
- hadoop知识总结(面试)
- Hadoop/Spark相关面试问题总结
- Hadoop/Spark相关面试问题总结
- Hadoop/Spark相关面试问题总结
- Hadoop/Spark相关面试问题总结
- Hadoop/Spark相关面试问题总结
- hadoop面试常见问题及相关总结
- 面试hadoop
- Hadoop面试
- Hadoop面试
- Hadoop面试
- Hadoop面试
- hadoop面试小结
- hadoop 面试 相关
- hadoop面试-1
- hadoop面试题目
- hadoop面试整理
- Tomcat源码学习--Cookie创建和销毁
- 上传图片demo
- SSH框架的增、删、查、改的实现
- 图片自动轮播(仿淘宝??)
- 17/10/31——最近感悟
- hadoop面试总结
- C# 获取系统时间及时间格式
- Android屏幕亮度调节
- 如何在Idea中安装运行才能js文件
- java用axis方式调用webservice接口
- 谷歌AVA数据库的1705.08421论文(2)
- hibernate.cfg.xml 配置格式
- Retrofit的POST方法上传头像
- 咸鱼翻身?iPhone X预售火爆,苹果自己也惊讶,说...


