sql 面试题总结
来源:互联网 发布:淘宝什么评论有福利 编辑:程序博客网 时间:2024/05/16 05:36
查询时使用联合索引的一个字段,如果这个字段在联合索引中所有字段的第一个,那就会用到索引,否则就无法使用到索引。
例如联合索引 IDX(字段A,字段B,字段C,字段D),当仅使用字段A查询时,索引IDX就会使用到;如果仅使用字段B或字段C或字段D查询,则索引IDX都不会用到。
这个规则在oracle和mysql数据库中均成立。
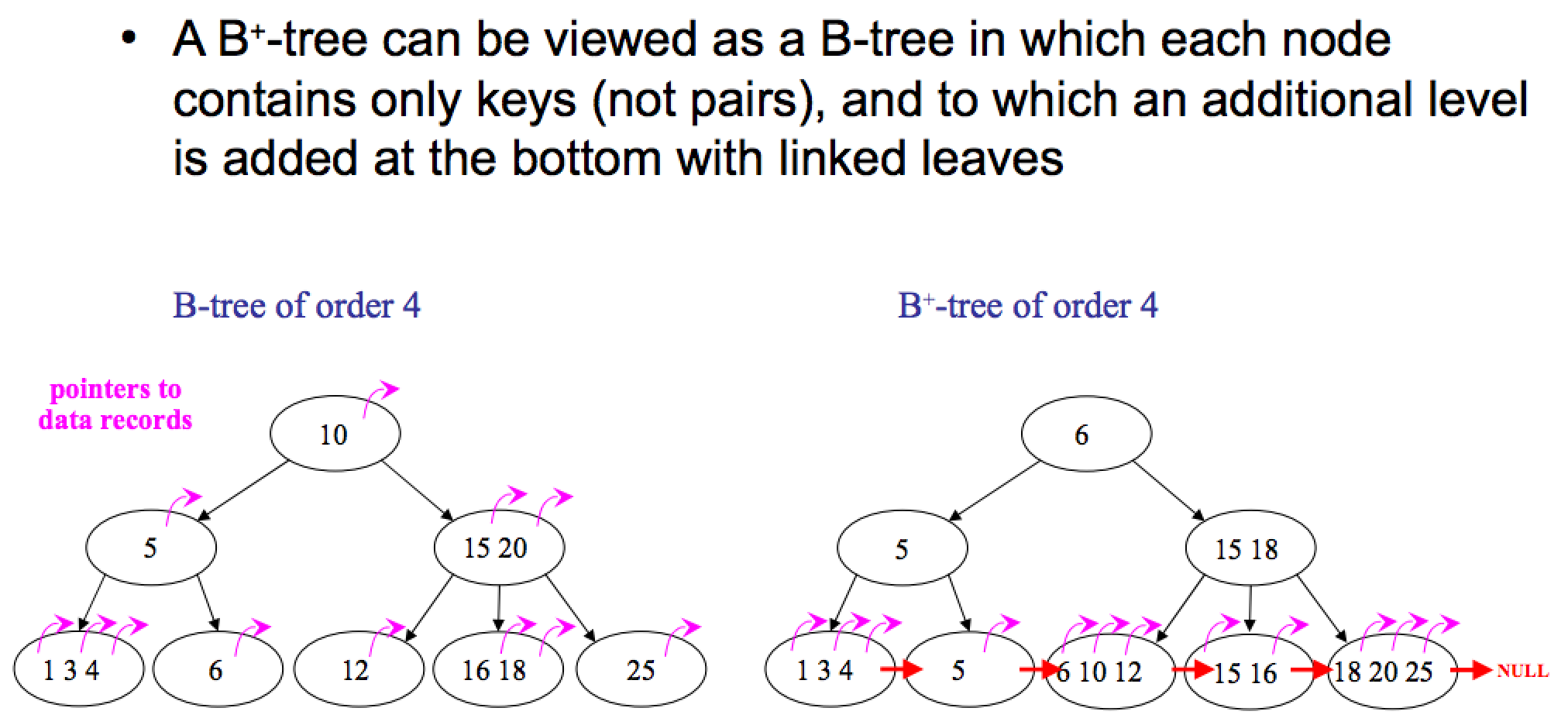
B树和B+树的区别
如图所示,区别有以下两点:
1. B+树中只有叶子节点会带有指向记录的指针(ROWID),而B树则所有节点都带有,在内部节点出现的索引项不会再出现在叶子节点中。
2. B+树中所有叶子节点都是通过指针连接在一起,而B树不会。
B+树的优点:
1. 非叶子节点不会带上ROWID,这样,一个块中可以容纳更多的索引项,一是可以降低树的高度。二是一个内部节点可以定位更多的叶子节点。
2. 叶子节点之间通过指针来连接,范围扫描将十分简单,而对于B树来说,则需要在叶子节点和内部节点不停的往返移动。
B树的优点:
对于在内部节点的数据,可直接得到,不必根据叶子节点来定位。
1.认识索引
索引是数据库对原始数据的一列或多列进行排序的一种结构,分为聚集索引和非聚集索引。聚集索引就像书的目录一样,排序结构和原表的一致;而非聚集索引就像字典的偏旁查找一样,排序顺序和字典的不一样,只是指出它在哪一页。
索引又分为单列索引和联合索引,单列索引很容易理解,就是对某一列进行排序。联合索引就是对多列排序,第一列为优先列,即优先按照这列排序,相同时再按下一列排序。
2.索引的影响
优点:我们建索引肯定是有目的的,目的就是为了更快的查询。对于索引的查找为什么比全表查询快呢?
- 索引的数据量比全表的少,需扫描的数据也就少。
- 索引对字段已经排序,可以进行二分法查询。
缺点:索引也不是越多越好的。如果我们对每一列都建立索引,那么需要的额外存储空间将加大,对于插入、更新等操作的速度将降低,因为这些操作都要维护索引,每插入一条,那么需要在每个索引都插入一条,这样效率就降低了。
结论:所谓钱要花在刀刃上,索引也不例外,只对经常查询的字段建索引,不建无用的索引。由于索引降低插入操作速度,因此:
- 查询频繁,插入少:建索引(一般网站数据都是)
- 查询少,插入频繁的或字段数据范围小的(如:性别):不建索引
- 查询多,插入也多:看需求(客户查询,员工插入,那么客户至上,当然速度慢让员工来忍受了)
3.索引的使用
(相关代码基于SQLite)
1.建立单列索引
- 1
2.建立联合索引
- 1
3.删除索引
- 1
4.重建索引
- 1
- 2
ps:为了健壮性考虑可以加上 IF NOT EXISTS等语句
4.索引的注意事项
- 对于联合索引,如果所查询字段不包含优先列,那么将不使用这索引。
- 对索引插入是在索引尾部插入的,所以在插入次数较多的情况下应重建索引。
- 触发索引的关键包括但不限于
select、where、join、order by.(like无效) - and、or连接词对索引来说,前后顺序无关。
作者注:以上皆是本人总结,若有错误遗漏之处,欢迎指出,共同讨论。
mysql单列索引、多列索引的使用
一、简介
数据库的索引可以加快查询速度,原因是索引使用特定的数据结构(B-Tree)对特定的列额外组织存放,加快存储引擎(索引是存储引擎实现)查找记录的速度。 索引优化是数据库优化的最重要手段。
如果查询语句使用索引(通常是where条件匹配索引)就会利用树的结构加快查找,索引会按值查找到要查找的行在表中位置,不需回表查询数据的就是聚簇索引(索引和数据存放在一起)。通常是需要回表再查数据,需要消耗额外的磁盘IO。所以有些时候(如按顺序读取数据)全表扫描会比使用索引快的原因就在于此。
查询条件只有一个字段时,在该字段建立索引即可,可优化的地方是对于text blob字段使用前缀索引。
当查询条件有多个字段时,单列索引和多列索引有很大的区别。如果使用多列索引,where条件中字段的顺序非常重要,需要满足最左前缀列。最左前缀:查询条件中的所有字段需要从左边起按顺序出现在多列索引中,查询条件的字段数要小于等于多列索引的字段数,中间字段不能存在范围查询的字段(<,like等),这样的sql可以使用该多列索引。
二、多列索引适合的场景
1.全字段匹配
2.匹配部分最左前缀
3.匹配第一列
4.匹配第一列范围查询(可用用like a%,但不能使用like %b)
5.精确匹配某一列和和范围匹配另外一列
order by操作中出现的字段同样适用于按值查找的规则,where+order by中出现的字段需可以建立满足如上五种规则多列索引。使用多列所需需要按照最左索引列查找;不能跳过中间列;如果某一列是范围查询,那么其右边所有列无法使用索引。IN什么情况下是范围查询,什么情况下是多个等值查询?如果有order by排序时,多个等于条件查询就是范围查询,没有order by排序就没有限制。
例如,建立多列索引(name, age, id),只能使用索引的前两列。in是范围查询... where name='nginx.cn' and age in(15,16,17) order by id
可以使用整个索引,in是按值查询... where name='nginx.cn' and age in(15,16,17) and id ='3'
三、复合索引的建立以及最左前缀原则
索引字符串值的前缀(prefixe)。如果你需要索引一个字符串数据列,那么最好在任何适当的情况下都应该指定前缀长度。例如,如果有CHAR(200)数据列,如果前面10个或20个字符都不同,就不要索引整个数据列。索引前面10个或20个字符会节省大量的空间。你可以索引CHAR、VARCHAR、BINARY、VARBINARY、BLOB和TEXT数据列的前缀。 假设你在表的state、city和zip数据列上建立了复合索引。索引中的数据行按照state/city/zip次序排列,因此它们也会自动地按照state/city和state次序排列。这意味着,即使你在查询中只指定了state值,或者指定state和city值,MySQL也可以使用这个索引。因此,这个索引可以被用于搜索如下所示的数据列组合: state, city, zip state, city state MySQL不能利用这个索引来搜索没有包含在最左前缀的内容。例如,如果你按照city或zip来搜索,就不会使用到这个索引。如果你搜索给定的state和具体的ZIP代码(索引的1和3列),该索引也是不能用于这种组合值的,尽管MySQL可以利用索引来查找匹配的state从而缩小搜索的范围。 如果你考虑给已经索引过的表添加索引,那么就要考虑你将增加的索引是否是已有的多列索引的最左前缀。如果是这样的,不用增加索引,因为已经有了(例如,如果你在state、city和zip上建立了索引,那么没有必要再增加state的索引)。
四、通过实例理解单例索引、多列索引以及最左前缀原则
实例:现在我们想查出满足以下条件的用户id: mysql>SELECT `uid` FROM people WHERE lname`='Liu' AND `fname`='Zhiqun' AND `age`=26 ; 因为我们不想扫描整表,故考虑用索引。 1、单列索引: ALTER TABLE people ADD INDEX lname (lname); 将lname列建索引,这样就把范围限制在lname='Liu'的结果集1上,之后扫描结果集1,产生满足fname='Zhiqun'的结果集2,再扫描结果集2,找到 age=26的结果集3,即最终结果。 由于建立了lname列的索引,与执行表的完全扫描相比,效率提高了很多,但我们要求扫描的记录数量仍旧远远超过了实际所需 要的。虽然我们可以删除lname列上的索引,再创建fname或者age 列的索引,但是,不论在哪个列上创建索引搜索效率仍旧相似。 2、多列索引: ALTER TABLE people ADD INDEX lname_fname_age (lame,fname,age);
为了提高搜索效率,我们需要考虑运用多列索引,由于索引文件以B-Tree格式保存,所以我们不用扫描任何记录,即可得到最终结果。 注:在mysql中执行查询时,只能使用一个索引,如果我们在lname,fname,age上分别建索引,执行查询时,只能使用一个索引,mysql会选择一个最严格(获得结果集记录数最少)的索引。 3.最左前缀:顾名思义,就是最左优先,上例中我们创建了lname_fname_age多列索引,相当于创建了(lname)单列索引,(lname,fname)组合索引以及(lname,fname,age)组合索引。 注:在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
SQL面试题(3)
1.触发器的作用?
答:触发器是一中特殊的存储过程,主要是通过事件来触发而被执行的。它可以强化约束,来维护数据的完整性和一致性,可以跟踪数据库内的操作从而不允许未经许可的更新和变化。可以联级运算。如,某表上的触发器上包含对另一个表的数据操作,而该操作又会导致该表触发器被触发。
2。什么是存储过程?用什么来调用?
答:存储过程是一个预编译的SQL 语句,优点是允许模块化的设计,就是说只需创建一次,以后在该程序中就可以调用多次。如果某次操作需要执行多次SQL ,使用存储过程比单纯SQL 语句执行要快。可以用一个命令对象来调用存储过程。
3。索引的作用?和它的优点缺点是什么?
答:索引就一种特殊的查询表,数据库的搜索引擎可以利用它加速对数据的检索。它很类似与现实生活中书的目录,不需要查询整本书内容就可以找到想要的数据。索引可以是唯一的,创建索引允许指定单个列或者是多个列。缺点是它减慢了数据录入的速度,同时也增加了数据库的尺寸大小。
3。什么是内存泄漏?
答:一般我们所说的内存泄漏指的是堆内存的泄漏。堆内存是程序从堆中为其分配的,大小任意的,使用完后要显示释放内存。当应用程序用关键字new 等创建对象时,就从堆中为它分配一块内存,使用完后程序调用free 或者delete 释放该内存,否则就说该内存就不能被使用,我们就说该内存被泄漏了。
4。维护数据库的完整性和一致性,你喜欢用触发器还是自写业务逻辑?为什么?
答:我是这样做的,尽可能使用约束,如check, 主键,外键,非空字段等来约束,这样做效率最高,也最方便。其次是使用触发器,这种方法可以保证,无论什么业务系统访问数据库都可以保证数据的完整新和一致性。最后考虑的是自写业务逻辑,但这样做麻烦,编程复杂,效率低下。
5。什么是事务?什么是锁?
答:事务就是被绑定在一起作为一个逻辑工作单元的SQL 语句分组,如果任何一个语句操作失败那么整个操作就被失败,以后操作就会回滚到操作前状态,或者是上有个节点。为了确保要么执行,要么不执行,就可以使用事务。要将有组语句作为事务考虑,就需要通过ACID 测试,即原子性,一致性,隔离性和持久性。
锁:在所以的 DBMS中,锁是实现事务的关键,锁可以保证事务的完整性和并发性。与现实生活中锁一样,它可以使某些数据的拥有者,在某段时间内不能使用某些数据或数据结构。当然锁还分级别的。
6。什么叫视图?游标是什么?
答:视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,试图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表。它使得我们获取数据更容易,相比多表查询。
游标:是对查询出来的结果集作为一个单元来有效的处理。游标可以定在该单元中的特定行,从结果集的当前行检索一行或多行。可以对结果集当前行做修改。一般不使用游标,但是需要逐条处理数据的时候,游标显得十分重要。
7。为管理业务培训信息,建立3个表:
S(S#,SN,SD,SA)S#,SN,SD,SA分别代表学号,学员姓名,所属单位,学员年龄
C(C#,CN)C#,CN分别代表课程编号,课程名称
SC(S#,C#,G) S#,C#,G分别代表学号,所选的课程编号,学习成绩
(1)使用标准SQL嵌套语句查询选修课程名称为’税收基础’的学员学号和姓名?
答案:select s# ,sn from s where S# in(select S# from c,sc where c.c#=sc.c# and cn=’税收基础’)
(2) 使用标准SQL嵌套语句查询选修课程编号为’C2’的学员姓名和所属单位?
答:select sn,sd from s,sc where s.s#=sc.s# and sc.c#=’c2’
(3) 使用标准SQL嵌套语句查询不选修课程编号为’C5’的学员姓名和所属单位?
答:select sn,sd from s where s# not in(select s# from sc where c#=’c5’)
(4)查询选修了课程的学员人数
答:select 学员人数=count(distinct s#) from sc
(5) 查询选修课程超过5门的学员学号和所属单位?
答:select sn,sd from s where s# in(select s# from sc group by s# having count(distinct c#)>5)
Select中DISTINCT关键字的用法?
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值。其原因是distinct只能返回它的目标字段,而无法返回其它字段,这个问题让我困扰了很久,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的站来说,无疑是会直接影响到效率的。所以我花了很多时间来研究这个问题,网上也查不到解决方案,期间把容容拉来帮忙,结果是我们两人都郁闷了。。。。。。。。。
下面先来看看例子:
table id name 1 a 2 b 3 c 4 c 5 b
库结构大概这样,这只是一个简单的例子,实际情况会复杂得多。
比如我想用一条语句查询得到name不重复的所有数据,那就必须使用distinct去掉多余的重复记录。
select distinct name from table得到的结果是:
name a b c
好像达到效果了,可是,我想要得到的是id值呢?改一下查询语句吧:
select distinct name, id from table
结果会是:
id name 1 a 2 b 3 c 4 c 5 b
distinct怎么没起作用?作用是起了的,不过他同时作用了两个字段,也就是必须得id与name都相同的才会被排除。。。。。。。
我们再改改查询语句:
select id, distinct name from table
很遗憾,除了错误信息你什么也得不到,distinct必须放在开头。难到不能把distinct放到where条件里?能,照样报错。。。。。。。
很麻烦吧?确实,费尽心思都没能解决这个问题。没办法,继续找人问。
拉住公司里一JAVA程序员,他给我演示了oracle里使用distinct之后,也没找到mysql里的解决方案,最后下班之前他建议我试试group by。
试了半天,也不行,最后在mysql手册里找到一个用法,用group_concat(distinct name)配合group by name实现了我所需要的功能,兴奋,天佑我也,赶快试试。
报错。。。。。。。。。。。。郁闷。。。。。。。连mysql手册也跟我过不去,先给了我希望,然后又把我推向失望,好狠哪。。。。
再仔细一查,group_concat函数是4.1支持,晕,我4.0的。没办法,升级,升完级一试,成功。。。。。。
终于搞定了,不过这样一来,又必须要求客户也升级了。
突然灵机一闪,既然可以使用group_concat函数,那其它函数能行吗?
赶紧用count函数一试,成功,我。。。。。。。想哭啊,费了这么多工夫。。。。。。。。原来就这么简单。。。。。。
现在将完整语句放出:
select *, count(distinct name) from table group by name
结果:
id name count(distinct name) 1 a 1 2 b 1 3 c 1
最后一项是多余的,不用管就行了,目的达到。。。。。
唉,原来mysql这么笨,轻轻一下就把他骗过去了,郁闷也就我吧(对了,还有容容那家伙),现在拿出来希望大家不要被这问题折腾。
哦,对,再顺便说一句,group by 必须放在 order by 和 limit之前,不然会报错,差不多了,发给容容放网站上去,我继续忙碌。。。。。。
- SQL面试题总结
- sql 面试题总结
- SQL 数据库 面试题 总结
- SQL面试题总结、解答
- Sql常见面试题(总结)
- sql面试题及答案总结
- Sql常用语句 and Sql常见面试题(总结)
- 我的Sql常见面试题(总结)
- 必知必会sql面试题练习总结之学生课程篇
- Tomcat和SQL优化的面试题总结
- 一道sql面试题
- SQL Server面试题
- sql面试题(转载)
- 一道sql面试题
- sql 2005 面试题
- 常见SQL面试题
- SQL面试题 (一)
- SQL面试题
- 栅栏
- 学习笔记--实现HashMap
- 面向对象--static静态关键字
- SCALA学习
- 习题5.3
- sql 面试题总结
- Java NIO及其常用API
- Tarjan 算法——求解有向图强连通分量
- 二阶指针的运用,字符串的交换
- 公众号后台开发上传文件功能
- Mysql分区
- 缘分天空之Mybatis学习
- Java —— interface接口
- SQUEEZENET


