使用tesseract进行中文文字识别
来源:互联网 发布:html5网游源码 编辑:程序博客网 时间:2024/05/17 09:06
简介
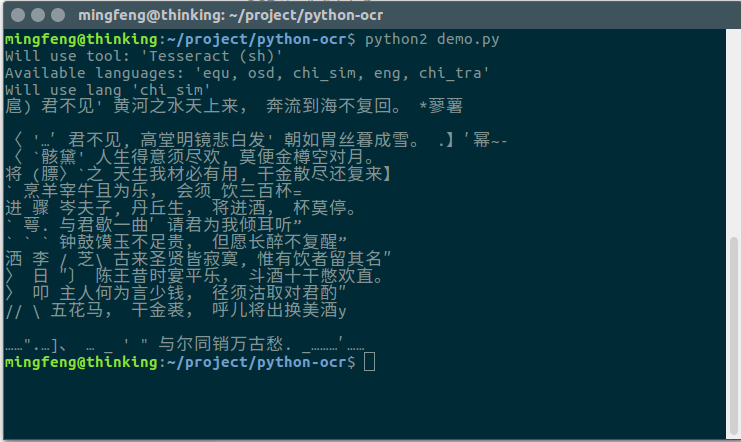
本文主要介绍如何通过tesseract进行文字识别,及其识别效果。效果图
图片 测试图测试结果
环境
- ubuntu
- python2.7
安装
- tesseract
sudo apt-get install tesseract-ocr- 安装tesseract tessdatahttps://github.com/tesseract-ocr/tessdata 下载对应语言文字学习数据,并保存到
/usr/share/tesseract-ocr/tessdata或/usr/share/tessdata位置 pyocr
sudo pip install pyocr测试代码
- demo.py
from PIL import Imageimport sysimport pyocrimport pyocr.buildersimport systools = pyocr.get_available_tools()if len(tools) == 0: print("Not found OCR tool") sys.exit(1)tool = tools[0]print("Will use tool: '%s'" % (tool.get_name()))langs = tool.get_available_languages()print("Available languages: '%s'" % ", ".join(langs))print("Will use lang '%s'" % ("chi_sim"))txt = tool.image_to_string( Image.open('images/jjj.jpg'), lang='chi_sim', builder=pyocr.builders.TextBuilder(tesseract_layout=6))print(txt)运行
python2 demo.py评价
文字识别的精度有待提升。一些像素低的,如标点符号都不能很好的解析出来。有兴趣的同学可以深入研究一下。
本文涉及代码
https://github.com/cangyan/python-ocr参考链接
https://qiita.com/it__ssei/items/fd804dcb10997566593b查看原文:https://www.huuinn.com/archives/410
更多技术干货:风匀坊
关注公众号:风匀坊
阅读全文
0 0
- 使用tesseract进行中文文字识别
- Tesseract-OCR 进行文字识别 VS2010
- 使用Tesseract OCR Engine识别图片文字
- 使用Tesseract-OCR训练文字识别记录
- 使用Tesseract-OCR训练文字识别记录
- Tesseract-OCR 进行文字识别 VS2010及不安装opencv,就可以使用opencv
- Tesseract ocr文字识别
- Python--文字识别--Tesseract
- 利用开源工具Tesseract进行文字识别
- OpenCV+Tesseract进行OCR学习(二)文字识别
- OpenCV+Tesseract进行OCR学习(二)文字识别
- java 利用 tesseract-ocr 进行文字识别技术
- Tesseract 进行图像识别
- tesseract 识别中文字符
- Mac下Tesseract-OCR文字识别新手使用入门
- Tesseract-ocr-图片文字识别
- python + tesseract OCR 文字识别
- 关于使用ImageMagick和Tesseract进行简单数字图像识别
- 【面向JS--DOM 操作API】
- Java面试题——索引解决什么问题?遵循怎样的原则?
- nginx 从入门到实践 -基础篇(1)
- synchronized和lock的区别
- UVA1585 得分score
- 使用tesseract进行中文文字识别
- IDEA配置SDK
- LeetCode基础-图-最小生成树
- 爬虫思路---原始版
- 51 nod 1135原根
- Git超级傻瓜教程[快速创建Git远程项目并上传本地代码]
- Java设计模式--工厂模式
- 自定义View测量模式解析
- 物理机(服务器)安装centos7系统


