从RDD角度来剖析Spark内部原理
来源:互联网 发布:网络支付有哪些 编辑:程序博客网 时间:2024/05/29 03:29
从RDD角度来剖析Spark内部原理
1 Spark的核心 — RDD?
1.1 RDD的5个属性

1.2 RDD的特性

1.3 What's RDD?
- 在物理上,RDD对象实质上是一个 元数据结构,存储着 Block、Node等的映射关系,以及其他的元数据信息。
- 一个RDD就是一组分区,在物理存储上,RDD的每个分区对应的就是一个Block,Block可以存储在内存中,当内存不够时可以存储在磁盘上。
- 如果数据是从HDFS等外部存储作为输入数据源,数据按照HDFS中的数据分布策略进行数据分区,HDFS中的一个Block对应Spark的一个分区。
- RDD(Resilient Distributed Dataset):弹性分布式数据集
1.4 Spark的核心 — RDD
Spark建立在统一抽象的RDD之上,使得Spark可以容易扩展,比如 Spark Streaming、Spark SQL、Machine Learning、Graph都是在 Spark RDD上面进行的扩展,足以看出RDD的核心地位。
2 RDD的管理和操作(算子)
2.1 RDD的管理
- RDD是一个分布式数据集,即数据分布存储在多台机器上。从上面也可以看到,每个RDD的数据都以Block的形式存储于多台机器上。
- 在Spark任务运行时,Driver节点的BlockManagerMaster保存Block的元数据,并且管理RDD与Block的关系;Executor会启动一个BlockManagerSlave,管理Block数据并向BlockManagerMaster注册该Block。
- 当RDD不再需要存储时,BlockManagerMaster将向BlockManagerSlave发送指令删除相应的Block。
2.2 RDD的操作(算子)
RDD还提供了一组丰富的操作来操作这些数据,这种操作叫做算子。比如map、flatMap、filter、join、groupBy、reduceByKey等。
RDD算子有四大类:创建算子、Transformation算子、缓存算子、Action算子
- 创建算子:sc.textFile(),sc.makeRdd(),sc.parallelize()
- Transformation: 对value类型RDD进行转换的算子,对K/V类型RDD进行转换的算子
- 缓存算子:cache
- Action:count()、collect()等
3 常用的Spark算子

4 从RDD角度来剖析Spark内部原理 — WordCount
4.1 WordCount
val file = sc.textFile("hdfs://data/test.txt")val data = file.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
4.2 WordCount执行流程
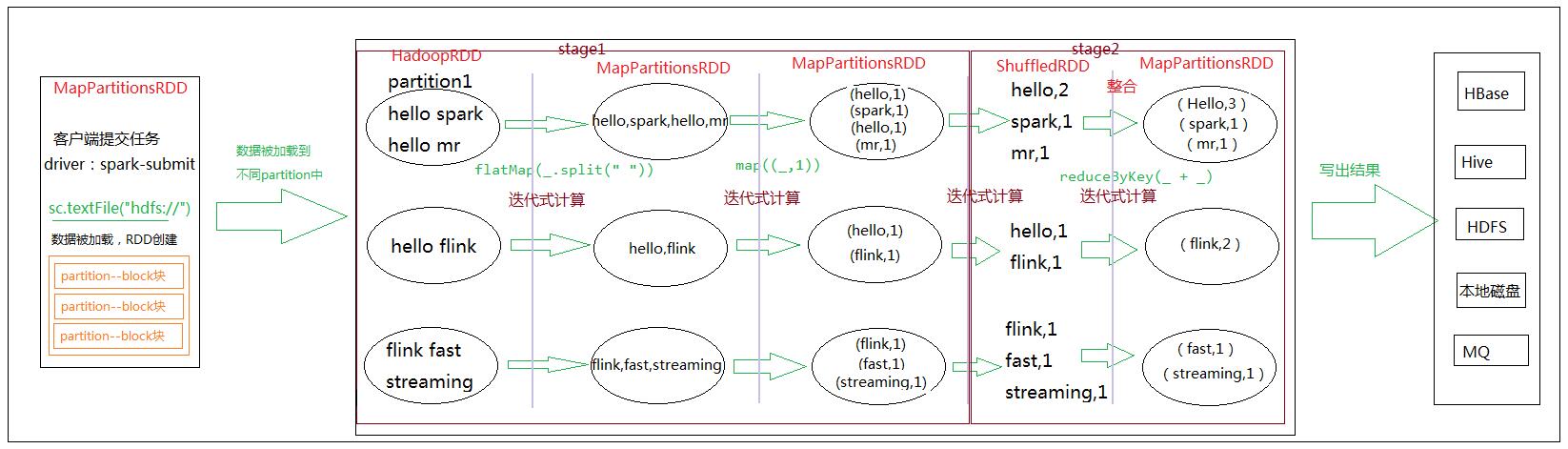
4.3 DAG(RDD的依赖关系)
4.3.1 两种依赖
Spark中的依赖分为两种: narrow 和 shuffle / wide。原因如下:
a) 首先,narrow dependencies 可以支持在同一个 cluster node 上,以 pipeline 形式执行多条命令,例如在执行了 map 后,紧接着执行 filter。
相反,shuffle / wide dependencies 需要所有的父分区都是可用的,可能还需要调用类似MR之类的操作进行跨节点传递。
b) 其次,则是从失败恢复的角度考虑。narrow dependencies 的失败恢复更有效,因为它只需要重新计算丢失的 parent partition 即可,而且是并行地在不同节点进行重计算。
相反,shuffle / wide dependencies 牵涉 RDD 各级的多个 parent partition。


总的来说,RDD的每个partition,仅仅依赖于父 RDD中的一个partition,这才是窄。(子RDD的partition和父RDD的partition是一对一就是窄依赖)。

之前总感觉上图关系是窄依赖,其实RDD1的partition0依赖父RDD0的partition0和partition1,所以是宽依赖。
4.3.2 依赖的实现
所有的依赖都要实现 trait Dependency[T]:
abstract class Dependency[T] extends Serializable { def rdd: RDD[T]}4.3.2.1 窄依赖的实现
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] { //返回子RDD的partitionId依赖的所有的parent RDD的Partition(s) def getParents(partitionId: Int): Seq[Int] override def rdd: RDD[T] = _rdd}窄依赖有两种具体实现:
(1) 一对一的依赖,即OneToOneDependency:
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) { override def getParents(partitionId: Int) = List(partitionId)由此不难看出,RDD仅仅依赖于 parent RDD相同ID的Partition。
override def getParents(partitionId: Int) = { if(partitionId >= outStart && partitionId < outStart + length) { List(partitionId - outStart + inStart) } else { Nil }}其中,inStart是parent RDD中partition的起始位置,outStart是在UnionRDD中的起始位置,length就是parent RDD中Partition的数量。
4.3.2.2 宽依赖的实现
只有一种实现: ShuffleDependency。子RDD依赖于parent RDD的所有partition,因此需要Shuffle过程。
class ShuffleDependency[K, V, C]( @transient _rdd: RDD[_ <: Product2[K, V]], val partitioner: Partitioner, val serializer: Option[Serializer] = None, val keyOrdering: Option[Ordering[K]] = None, val aggregator: Option[Aggregator[K, V, C]] = None, val mapSideCombine: Boolean = false)extends Dependency[Product2[K, V]] { override def rdd = _rdd.asInstanceOf[RDD[Product2[K, V]]]//获取新的shuffleIdval shuffleId: Int = _rdd.context.newShuffleId()//向ShuffleManager注册Shuffle的信息val shuffleHandle: ShuffleHandle =_rdd.context.env.shuffleManager.registerShuffle( shuffleId, _rdd.partitions.size, this) _rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))}宽依赖支持两种Shuffle Manager:
org.apache.spark.shuffle.hash.HashShuffleManager(基于Hash的Shuffle机制)
org.apache.spark.shuffle.sort.SortShuffleManager(基于排序的Shuffle机制)
4.4 Stage的划分
Spark Application Job的Stage划分规则:
(1)RDD在调用 transformation 类型的函数时候形成 DAG 执行图(RDD的依赖)
(2)RDD在调用 action 类型函数时候会触发 job 的执行
(3)在 Driver 中使用 DAGScheduler 对 DAG图进行 Stage的划分
从DAG图的最后一步(结果输出的那一步)往前推,如果发现API是宽依赖(ShuffledRDD),就结束推断,将此时构成的DAG图称为一个 Stage,然后继续往前推断,直到第一个RDD ————> Stage与Stage之间的分割是宽依赖。
Reference Link
[1] Spark的算子的分类: https://www.cnblogs.com/zlslch/p/5723857.html
[2] 常见的RDD转换和行动算子:http://blog.csdn.net/bitbyteworld/article/details/53612089
[3] Spark函数详解系列之RDD基本转换: https://www.cnblogs.com/MOBIN/p/5373256.html
- 从RDD角度来剖析Spark内部原理
- 从RDD的角度来看Spark内部原理
- 从源码角度来剖析Rxjava的运行原理
- Spark Scheduler内部原理剖析
- Spark RDD源码剖析
- spark RDD的原理
- 3.Spark-RDD原理
- 从Spark组件来剖析Spark的执行流程
- Spark RDD使用详解1--RDD原理
- Spark RDD使用详解1--RDD原理
- Spark 原理及RDD理解
- Spark开发-spark运行原理和RDD
- spark源码剖析--RDD创建和本质
- Spark 核心 RDD 剖析(上)
- Spark 核心 RDD 剖析(下)
- Spark Scheduler 原理剖析
- Spark-scheduler原理剖析
- 3000门徒内部训练绝密视频(泄密版)第7课:实战解析Spark运行原理和Rdd解密
- Class类
- final关键字
- Devstack stable/pike local.conf 分析
- 俄罗斯方块
- 数据结构中缀转后缀笔记
- 从RDD角度来剖析Spark内部原理
- windows 导出模块获取及dos内存结构剖析
- 安卓事件分发机制
- jquery validate简单实例
- Flask使用SQLAlchemy时报字符集错误处理
- 16进制数与字符串转换函数
- Java内存泄露监控工具:JVM监控工具介绍
- day 19 Linux文件压缩与打包
- 俄罗斯方块


