互联网利器 Redis内存数据库性能评测
来源:互联网 发布:剑三脸型数据不合法 编辑:程序博客网 时间:2024/05/21 04:43
Redis是一款开源的、高性能的键-值存储(key-value store)。它常被称作是一款数据结构服务器(data structure server)。Redis的键值可以包括字符串(strings)、哈希(hashes)、列表(lists)、集合(sets)和 有序集合(sorted sets)等数据类型。 对于这些数据类型,你可以执行原子操作。例如:对字符串进行附加操作(append);递增哈希中的值;向列表中增加元素;计算集合的交集、并集与差集等。
为了获得优异的性能,Redis采用了内存中(in-memory)数据集(dataset)的方式。根据使用场景的不同,你可以每隔一段时间将数据集转存到磁盘上来持久化数据,或者在日志尾部追加每一条操作命令。
Redis同样支持主从复制(master-slave replication),并且具有非常快速的非阻塞首次同步(non-blocking first synchronization)、网络断开自动重连等功能。同时Redis还具有其它一些特性,其中包括简单的check-and-set机制、pub/sub和配置设置等,以便使得Redis能够表现得更像缓存(cache)。
Redis还提供了丰富的客户端,以便支持现阶段流行的大多数编程语言。详细的支持列表可以参看Redis官方文档:http://redis.io/clients。Redis自身使用ANSI C来编写,并且能够在不产生外部依赖(external dependencies)的情况下运行在大多数POSIX系统上,例如:Linux、*BSD、OS X和Solaris等。
安装配置:
下载最新版:
解压缩:
安装C/C++的编译组件(非必须):
编译:
make
make命令执行完成后,会在当前目录下生成本个可执行文件,分别是redis-server、redis-cli、redis-benchmark、redis-stat,它们的作用如下:
· redis-server:Redis服务器的daemon启动程序;
· redis-cli:Redis命令行操作工具。当然,你也可以用telnet根据其纯文本协议来操作;
· redis-benchmark:Redis性能测试工具,测试Redis在你的系统及你的配置下的读写性能;
· redis-stat:Redis状态检测工具,可以检测Redis当前状态参数及延迟状况。
在后面会有这几个命令的说明:
修改配置文件:
添加:
刷新配置使之生效:
补充介绍:
**如果内存情况比较紧张的话,需要设定内核参数:
内核参数说明如下:
overcommit_memory文件指定了内核针对内存分配的策略,其值可以是0、1、2。
0. 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程;
1. 表示内核允许分配所有的物理内存,而不管当前的内存状态如何;
2. 表示内核允许分配超过所有物理内存和交换空间总和的内存。
**编辑redis.conf配置文件(/etc/redis.conf),按需求做出适当调整,比如:
save 60 1000 #减小改变次数,其实这个可以根据情况进行指定
maxmemory 256000000 #分配256M内存
在我们成功安装Redis后,我们直接执行redis-server即可运行Redis,此时它是按照默认配置来运行的(默认配置甚至不是后台运 行)。我们希望Redis按我们的要求运行,则我们需要修改配置文件,Redis的配置文件就是我们上面第二个cp操作的redis.conf文件,目前 它被我们拷贝到了/usr/local/redis/etc/目录下。修改它就可以配置我们的server了。如何修改?下面是redis.conf的主 要配置参数的意义:
• pidfile:pid文件位置;
• port:监听的端口号;
• timeout:请求超时时间;
• loglevel:log信息级别;
• logfile:log文件位置;
• databases:开启数据库的数量;
• save * *:保存快照的频率,第一个*表示多长时间,第三个*表示执行多少次写操作。在一定时间内执行一定数量的写操作时,自动保存快照。可设置多个条件;
• rdbcompression:是否使用压缩;
• dbfilename:数据快照文件名(只是文件名,不包括目录);
• dir:数据快照的保存目录(这个是目录);
• appendonly:是否开启appendonlylog,开启的话每次写操作会记一条log,这会提高数据抗风险能力,但影响效率;
• appendfsync:appendonlylog如何同步到磁盘(三个选项,分别是每次写都强制调用fsync、每秒启用一次fsync、不调用fsync等待系统自己同步)。
下面是一个略做修改后的配置文件内容:
pidfile /usr/local/redis/var/redis.pid
port 6379
timeout 300
loglevel debug
logfile /usr/local/redis/var/redis.log
databases 16
save 900 1
save 300 10
save 60 10000
rdbcompression yes
dbfilename dump.rdb
dir /usr/local/redis/var/
appendonly no
appendfsync always
glueoutputbuf yes
shareobjects no
shareobjectspoolsize 1024
将上面内容写为redis.conf并保存到/usr/local/redis/etc/目录下,然后在命令行执行:
即可在后台启动redis服务,这时你通过:
即可连接到你的redis服务。
启动服务并验证
启动服务器:
或:
查看是否成功启动:
或:
PONG
启动命令行客户端赋值取值:
./redis-cli get mykey
关闭服务:
#关闭指定端口的redis-server
$redis-cli -p 6380 shutdown
客户端也可以使用telnet形式连接:
Trying 127.0.0.1...
Connected to dbcache (127.0.0.1).
Escape character is '^]'.
set foo 3
bar
+OK
get foo
$3
bar
^]
telnet> quit
Connection closed.
Benchmark测试
·测试环境
本次测试使用的软硬件环境如下:
硬件配置:Intel(R) Core(TM) i7 CPU 860 @ 2.80GHz,4核8线程, 内存8GB。
操作系统: Redhat Enterprise Linux 6.0 X64。
·测试假定
本次测试为充分展示内存数据库的性能,关闭了Redis写盘操作和日志功能。
插入测试
·单线程
首先进行单线程的插入测试,向数据库中插入10000000条记录,性能如下:
线程ID
记录数
耗时(毫秒)
1
10000000
4094211
每条记录所花费的时间(微秒)
409.4
每秒吞吐率(object/s)
2442.5
单线程插入10000000条记录的耗时为4094秒,每条记录的花费时间为409微秒,每秒处理的记录数为0.244万。
·4线程
之后我们增加线程数为4.
四个线程同时插入10000000条记录,性能如下:
线程ID
记录数
耗时(毫秒)
1
2500000
697759
2
2500000
699981
3
2500000
699994
4
2500000
700128
插入10000000条记录所花费的总时间(秒)
699.5
每条记录所花费的时间(微秒)
69.94655
每秒吞吐率(object/s)
14296.63078
四个线程插入10000000条记录的总耗时为699.5秒,平均每条记录耗时67微秒,每秒处理1.43万条数据。
·8线程
插入测试是通过八个线程,向数据库中添加10000000条记录,每个线程的性能和总体性能如下:
线程ID
记录数
耗时(毫秒)
1
1250000
700740
2
1250000
708551
3
1250000
709325
4
1250000
709935
5
1250000
711784
6
1250000
711913
7
1250000
712460
8
1250000
715165
插入10000000条记录所花费的总时间(秒)
710
每条记录所花费的时间(微秒)
71
每秒吞吐率(object/s)
14084.82197
可以看到8个并发写入10000000条记录所花费的时间大概为710秒,平均每秒可以添加1.4万条记录。
总结
插入操作的总体吞吐率:
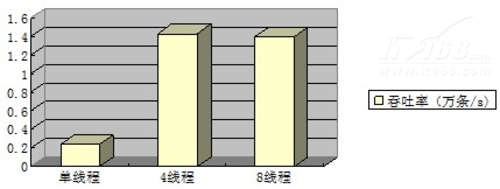
可以看到,插入操作的性能,4个线程并发操作时,吞吐率最大。
更新测试
·单线程
首先进行单线程的更新测试,在数据库中进行10000000次更新,每次更新一条记录的所有字段,性能如下:
线程ID
记录数
耗时(毫秒)
1
10000000
4447566
每条记录所花费的时间(微秒)
444.7566
每秒吞吐率(object/s)
2248.421
单线程更新10000000条记录的耗时为4448秒,每条记录的更新花费时间为444.8微秒,每秒处理的记录数为0.25万。
·4线程
之后我们增加线程数为4.
四个线程同时更新10000000条记录,性能如下:
线程ID
记录数
耗时(毫秒)
1
2500000
705554
2
2500000
705673
3
2500000
706940
4
2500000
707046
插入10000000条记录所花费的总时间(秒)
706
每条记录所花费的时间(微秒)
70.6
每秒吞吐率(object/s)
14158.22
四个线程更新10000000条记录的总耗时为706秒,平均每条记录耗时70.6微秒,每秒处理1.415万条数据。
·8线程
更新测试是通过八个线程,同时更新数据库中记录,共10000000次操作,每个线程的性能和总体性能如下:
线程ID
记录数
耗时(毫秒)
1
1250000
712570
2
1250000
715721
3
1250000
717342
4
1250000
717414
5
1250000
717843
6
1250000
717882
7
1250000
718421
8
1250000
719851
更新10000000条记录的耗时(秒)
717.1
更新每条记录所的耗时(微秒)
71.7
每秒吞吐率(object/s)
13944.5
可以看到8个并发同时更新10000000条记录所花费的时间大概为717秒,平均每秒可以更新1.394万条记录。此处的更新为涉及到了每条记录的每个字段。
总结
更新操作的总体吞吐率:
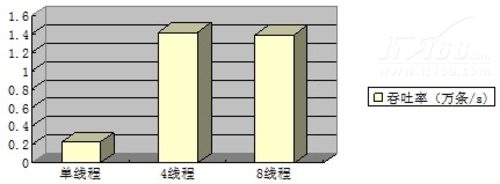
可以看到,更新操作的性能,同样也是4个线程并发操作时,吞吐率最大,但仅仅比8线程性能略高。
查询测试
·单线程
首先进行单线程的查询测试,在数据库中进行10000000次查找,性能如下:
线程ID
记录数
耗时(毫秒)
1
10000000
712896
每条记录所花费的时间(微秒)
71.2896
每秒吞吐率(object/s)
14027.2915
单线程进行10000000次查询的耗时为713秒,每次查询花费时间为71.3微秒,每秒处理的操作数为1.4万。
·4线程
之后我们增加线程数为4.
四个线程进行10000000次查找操作,性能如下:
线程ID
记录数
耗时(毫秒)
1
2500000
116418
2
2500000
116629
3
2500000
116649
4
2500000
116700
插入10000000条记录所花费的总时间(秒)
116.6
每条记录所花费的时间(微秒)
11.65
每秒吞吐率(object/s)
85764.02885
四个线程进行10000000次查找操作的总耗时为116.6秒,平均每条记录耗时11.6微秒,每秒处理8.5万次查询操作。
·8线程
查询测试是通过八个线程,同时查询数据库中记录,共10000000次查询,每个线程的性能和总体性能如下:
线程ID
记录数
耗时(毫秒)
1
1250000
117360
2
1250000
117655
3
1250000
117791
4
1250000
118174
5
1250000
118251
6
1250000
118288
7
1250000
118300
8
1250000
118594
查询10000000次的耗时(秒)
118
每次查询的耗时(微秒)
11.8
每秒吞吐率(object/s)
84708.70265
可以看到8个并发同时查询10000000条记录所花费的时间大概为118秒,平均每秒可以进行8.47万次查询。
总结
查询操作的总体吞吐率:
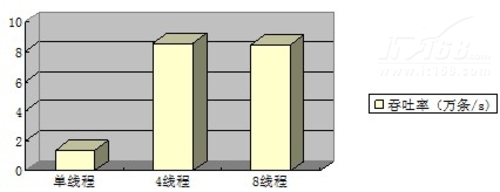
可以看到,查询操作的性能,同样也是4个线程并发操作时,吞吐率最大。
1:1读写测试
·4线程
首先进行四线程的读写测试,其中2个线程做更新操作,另外两个线程做查询操作,持续运行10秒钟,每个线程的性能和总体性能如下:
线程ID
操作
操作次数
1
查询
215854
2
查询
215317
3
更新
35727
4
更新
35715
每秒查询吞吐率(完成次数/s)
43117.1
每秒更新吞吐率(完成次数/s)
7144.2
总吞吐率(完成次数/s)
50261.3
在四个线程进行读写测试时,平均每秒可以进行4.3万次查询,0.7万次更新,总体吞吐率为5万。
·8线程
读写测试是通过八个线程,其中四个线程持续做更新操作,另外四个线程做查询操作,持续运行10秒中,每个线程的性能和总体性能如下:
线程ID
操作
操作次数
1
查询
101150
2
查询
97950
3
查询
97978
4
查询
93043
5
更新
15665
6
更新
15326
7
更新
15406
8
更新
15638
每秒查询吞吐率(完成次数/s)
39012.1
每秒更新吞吐率(完成次数/s)
6203.5
总吞吐率(完成次数/s)
45215.6
可以看到同时进行读写测试时,平均每秒可以进行39012次查询,6203次更新,总体吞吐率为45215。
总结
1:1读写操作的总体吞吐率:
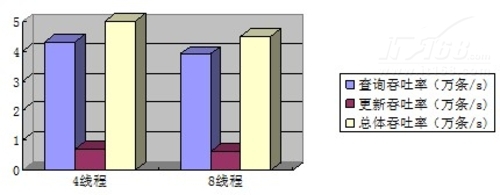
可以看到,1:1读写操作的性能,4线程比8线程的查询吞吐率和总体吞吐率高,而更新吞吐率几乎一致。
删除测试
·单线程
首先进行单线程的删除测试,在数据库中进行10000000次删除,每次删除一条记录,性能如下:
线程ID
记录数
耗时(毫秒)
1
10000000
626237
每条记录所花费的时间(微秒)
62.6
每秒吞吐率(object/s)
15968.4
单线程进行10000000次删除操作的耗时为626秒,每次查询花费时间为62.6微秒,每秒处理的操作数为1.6万。
·4线程
之后我们增加线程数为4.
四个线程进行10000000次删除操作,性能如下:
线程ID
记录数
耗时(毫秒)
1
2500000
107475
2
2500000
107703
3
2500000
107840
4
2500000
107915
插入10000000条记录所花费的总时间(秒)
107.7
每条记录所花费的时间(微秒)
10.7
每秒吞吐率(object/s)
92821.85
四个线程进行10000000次删除操作的总耗时为107.7秒,平均删除每条记录耗时10.7微秒,每秒处理9.3万次删除操作。
·8线程
删除测试是通过八个线程,按照记录ID,同时删除数据库中记录,共10000000个对象,每个线程的性能和总体性能如下:
线程ID
记录数
耗时(毫秒)
1
1250000
109232
2
1250000
109709
3
1250000
109886
4
1250000
110114
5
1250000
110380
6
1250000
110476
7
1250000
110552
8
1250000
110563
查询10000000次的耗时(秒)
110.114
每次查询的耗时(微秒)
11
每秒吞吐率(object/s)
90814.97
可以看到8个并发同时删除10000000条记录所花费的时间大概为110秒,平均每秒可以进行9.08万次删除。
总结
查询操作的总体吞吐率:
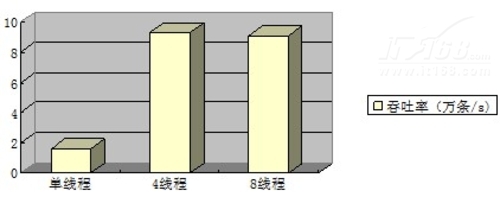
可以看到,删除操作的性能,同样也是4个线程并发操作时,吞吐率最大。
以上测试都是次操作都为一个事务,每次操作只涉及一条记录。
本文总结:
Redis为了获得优异的性能,底层实现上重新编写了epoll event loop部分,而没有采用开源的libevent等通用框架,读写效率较高,我们在测试中也看到了,从单线程到4线程有较高的提升,4线程到8线程性能几乎没有变化,基本保持10万/秒的吞吐量也是不错的性能,加之Redis是开源产品,并且支持多种开发语言,提供python、php、Ruby等客户端,使用非常方便,在高速度更新的互联网行业应用较广泛。
- 互联网利器 Redis内存数据库性能评测
- 互联网利器 Redis内存数据库性能评测
- 内存数据库性能评测之SQLite数据库
- Redis性能评测
- Redis性能评测
- redis性能评测
- 转 -- 内存数据库性能评测之SQLite数据库
- SQLite数据库操作速度和性能评测
- 转 实时数据管理 eXtremeDB内存数据库评测
- SAP HANA: 列式内存数据库评测
- SAP HANA: 列式内存数据库评测
- SAP HANA: 列式内存数据库评测
- 内存数据库-Redis介绍
- 内存数据库redis
- Redis 内存数据库
- redis内存数据库
- redis内存数据库
- Redis 高性能内存存储
- CUDA --- Fundamental Optimization Strategies
- ImportError: The Python Imaging Library (PIL) is required to load data from jpeg files
- next_permutation
- Win32创建一个简单的窗口
- Python——Excel文件读写
- 互联网利器 Redis内存数据库性能评测
- 11 个简单的 Java 性能调优技巧
- C&C++搭建环境——命令行IDE:git+MinGW
- DStream, DStreamGraph 详解
- Servlet拦截器基础知识
- 为什么我认为软件方法论无效
- SSSP-CRUD-添加
- Python的高级特征——切片
- linux-磁盘分区,加密以及磁盘阵列


