机器学习(2) ---- 分类问题
来源:互联网 发布:大数据明细实时查询 编辑:程序博客网 时间:2024/05/29 10:26
机器学习(2) —- 分类问题
个人博客,欢迎参观:http://www.ioqian.top/
1.决策树(Decision Tree)
参考博客: https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html
根据一些 feature 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
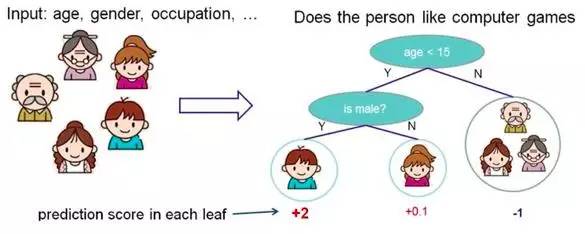
个人总结(不能保证正确),一组数据的特征用向量表示,比如[x1,x2,x3,x4]有4个特征,先通过x1特征分为2类,然后再接着使用x2特征分类,直到终止条件或特征使用完。可以看成把特征串行起来使用。根节点使用什么特征?什么时候终止?
2.随机森林(Random Forest)
参考博客:
http://blog.csdn.net/mao_xiao_feng/article/details/52728164
https://www.cnblogs.com/maybe2030/p/4585705.html
随机森林是为了解决决策树容易过拟合的缺点(见上述参考博客),采用了多个决策树的投票机制来改善决策树,我们假设随机森林使用了m棵决策树,那么就需要产生m个一定数量的样本集来训练每一棵树,如果用全样本去训练m棵决策树显然是不可取的,全样本训练忽视了局部样本的规律,对于模型的泛化能力是有害的。产生n个样本的方法采用Bootstraping法,这是一种有放回的抽样方法,产生n个样本而最终结果采用Bagging的策略来获得,即多数投票机制

随机森林的生成方法:
1.从样本集中通过重采样的方式产生n个样本
2.假设样本特征数目为a,对n个样本选择a中的k个特征,用建立决策树的方式获得最佳分割点
3.重复m次,产生m棵决策树
4.多数投票机制来进行预测
(需要注意的一点是,这里m是指循环的次数,n是指样本的数目,n个样本构成训练的样本集,而m次循环中又会产生m个这样的样本集)
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想–集成思想的体现。
其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
3.k-近邻,KNN(K-nearest neighbor classification)
参考博客:
https://www.cnblogs.com/ybjourney/p/4702562.html
给一个新的数据时,离它最近的 k 个点中,哪个类别多,这个数据就属于哪一类
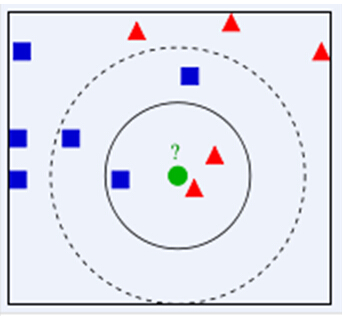
如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类
算法步骤:
1)计算测试数据与各个训练数据之间的距离; 
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
4. Adaboost
参考博客: http://blog.csdn.net/haidao2009/article/details/7514787
AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器。
5.SVM support vector machine)
参考博客: http://blog.csdn.net/macyang/article/details/38782399/
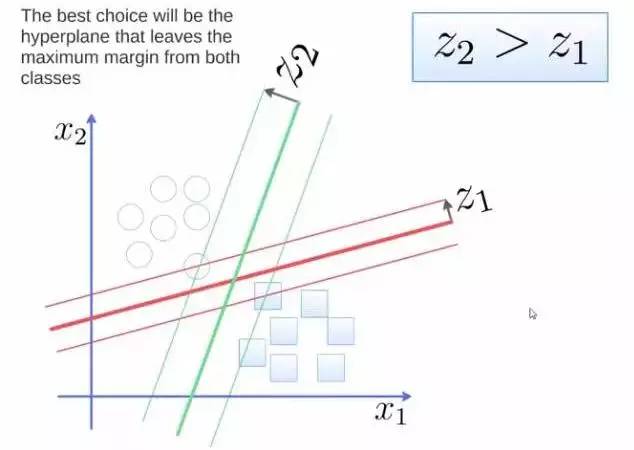
要将两类分开,想要得到一个超平面,最优的超平面是到两类的 margin 达到最大,margin就是超平面与离它最近一点的距离,如下图,Z2>Z1,所以绿色的超平面比较好
6.朴素贝叶斯 (Naive Bayesian classification)
参考博客: http://blog.csdn.net/amds123/article/details/70173402
贝叶斯分类算法是统计学的一种分类方法,它是一类利用概率统计知识进行分类的算法。在许多场合,朴素贝叶斯(Naïve Bayes,NB)分类算法可以与决策树和神经网络分类算法相媲美,该算法能运用到大型数据库中,而且方法简单、分类准确率高、速度快。
既然是朴素贝叶斯分类算法,它的核心算法又是什么呢?
是下面这个贝叶斯公式


7.总结
参考博客: http://blog.csdn.net/shuke1991/article/details/52056382

决策树,svm,knn,k-means源码下载(python实现,基本上都使用第三方库)
https://gitee.com/qianlilo/Machine-Learning-simple-arithmetic#machine-learning-simple-arithmetic
- 机器学习(2) ---- 分类问题
- 机器学习问题分类
- 机器学习----分类问题
- 机器学习(2)-SVM分类算法
- 机器学习(2)-分类问题_Classification and Representation
- 机器学习做二元分类问题(二)
- 使用pyspark进行机器学习(分类问题)
- 机器学习-回归及分类问题总结
- 机器学习 非均衡分类问题
- 机器学习中的非均衡分类问题
- Android加载机器学习分类器问题
- 机器学习中的二元分类问题
- 【01】台大机器学习L3 机器学习分类问题
- 机器学习问题分类--机器学习基石笔记
- 用Python开始机器学习(2:决策树分类算法)
- 用Python开始机器学习(2:决策树分类算法)
- 用Python开始机器学习(2:决策树分类算法)
- 2python机器学习--SVM(决策树分类算法)
- Spark编程指南入门之Java篇二-基本操作
- 11.14 新的开始
- 电脑问题
- 线性搜索linear search
- 一条Select语句引发的反思-续
- 机器学习(2) ---- 分类问题
- LinkedList和ArrayList异同点
- lucene的基本使用
- thinkphp 自定义sql语句如何分页
- 加1乘2平方
- 求Sn=a+aa+aaa+aaaa+aaaaa的前5项之和,其中a是一个数字,例如:2+22+222+2222+22222
- linux系统下,用emacs写c++并编译
- 卸载myeclipse时报failed to load JNI shared library,无法完成卸载
- 小白学PyQt5(0):笔者的话


