正则表达式及爬虫小案例
来源:互联网 发布:培训java三个月靠谱吗 编辑:程序博客网 时间:2024/06/06 20:50
正则表达式及爬虫小案例
正则表达式
正则表达式通常用来检索,替换,匹配符合某个规则的文本。在处理非结构化的文本数据时,需要匹配一定的规则,以获取需要的文本数据。
正则表达式的效率是非常高的,当然匹配规则也比较复杂。在Python是内置正则表达式(re模块)。
正则表达式匹配规则
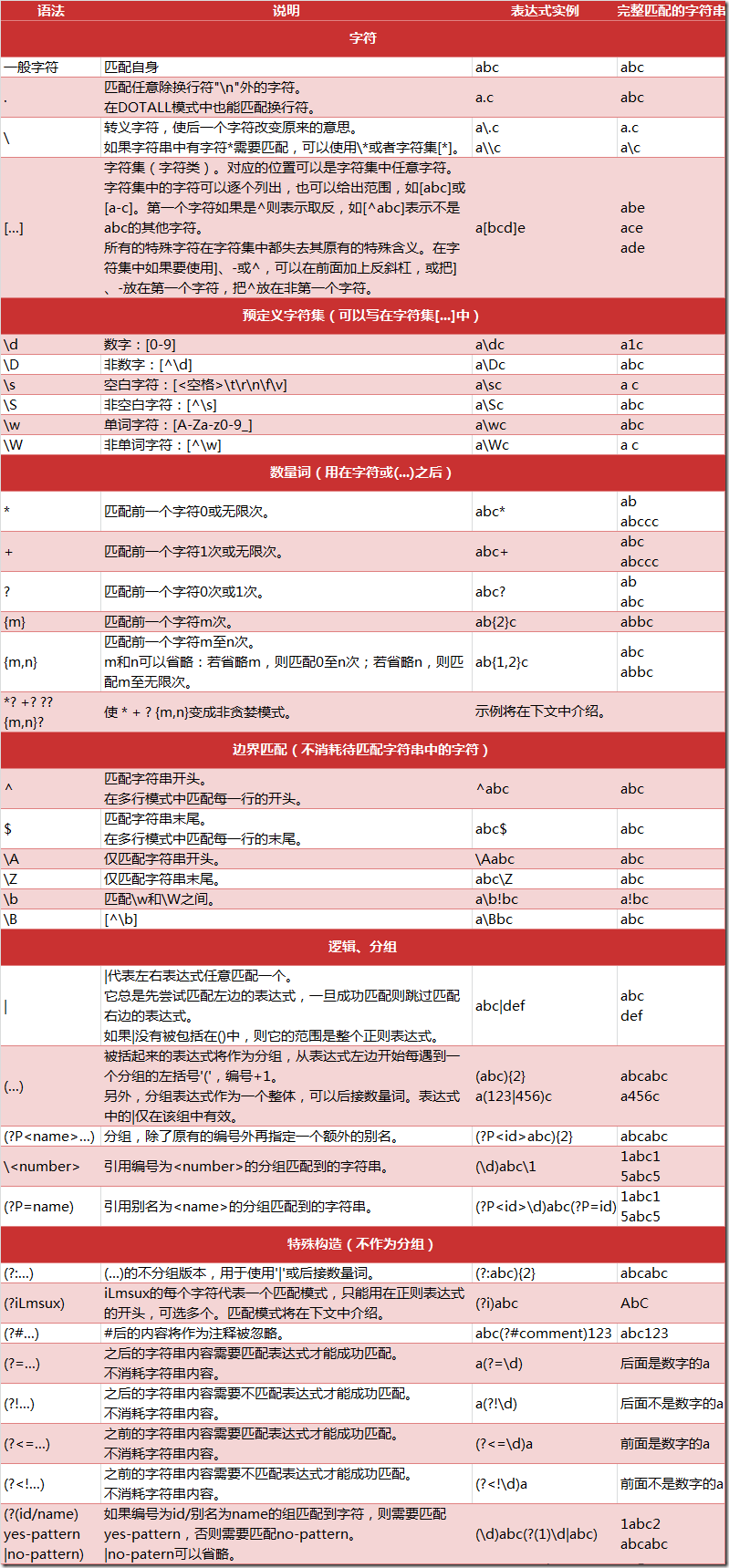
正则表达式常用函数
re模块一般使用步骤:
使用compile()函数,建立一个匹配模型
compile():制定匹配规则,用于生成一个Pattern对象。如:
import re# compile()的参数是匹配规则,返回一个模型对象patternpattern = re.compile(r'\d+')通过模型Pattern调用匹配方法,匹配具体文本内容
pattern的匹配方法有:
match():从起始位置开始查找,一次匹配
import reif __name__ == '__main__': # 匹配数字 pattern = re.compile(r'\d+') content = pattern.match('12abc3456dfg789') print(content) # <_sre.SRE_Match object; span=(0, 2), match='12'> 返回一个对象,匹配到了一个数据,是12(match='12'),范围是0-2 content2 = pattern.match('abc123def456') print(content2) # None:表示没有匹配到数据search():从任意位置开始查找,一次匹配
import reif __name__ == '__main__': # 匹配数字 pattern = re.compile(r'\d+') content = pattern.search('abc123def456') print(content) # <_sre.SRE_Match object; span=(3, 6), match='123'> 匹配到了'123',角标范围3-6 # 获取匹配的文本,正则匹配结果通过group获取匹配的结果 print(content.group()) # 123findall():全部查找匹配,返回全部匹配的数据列表
import reif __name__ == '__main__': # 匹配数字 pattern = re.compile(r'\d+') content = pattern.findall('abc123def456') print(content) # 输出 ['123', '456'] for item in content: print(item) #输出 123 和 456finditer():全部匹配,返回迭代器对象(不常用)。
import reif __name__ == '__main__': # 匹配数字 pattern = re.compile(r'\d+') content = pattern.finditer('abc123def456') print(content) #输出 <callable_iterator object at 0x0000018B3E7AF9E8> 返回一个迭代器对象 for item in content: print(item) # 输出 <_sre.SRE_Match object; span=(3, 6), match='123'> 和 <_sre.SRE_Match object; span=(9, 12), match='456'> print_content_result(item) # 输出 123 和分隔符 , 456 和分隔符split():分割字符串,返回列表
import reif __name__ == '__main__': # 匹配数字 pattern = re.compile(r'\d+') content = pattern.split('abc123def456') print(content) # 输出 ['abc', 'def', '']sub():检索和替换
sub函数用法:re.sub(pattern, repl, string, count=0)pattern参数:正则中模式字符串repl参数:替换的字符串,也可以是一个函数string参数:要被查找替换的原始字符串count参数:模式匹配后替换的最大次数,默认0表示替换所有的匹配eg1:if __name__ == '__main__': # 匹配数字 pattern = re.compile(r'\d+') num = re.sub(pattern, '-', 'abc123def456') # 匹配所有 print(num) # 输出 abc-def-eg1:if __name__ == '__main__': # 匹配数字 pattern = re.compile(r'\d+') num = re.sub(pattern, '-', 'abc123def456', count=1) # 匹配一个 print(num) # abc-def456
匹配内容结果返回及处理
re模块通过group()来获取匹配的结果的文本信息。如下:
“`
import redef print_content_result(content):
if content != None:
print(content.group())
print(‘-’ * 30)if name == ‘main‘:
# 匹配数字
pattern = re.compile(r’\d+’)
content = pattern.match(‘12abc3456dfg789’)
print(content) # <_sre.SRE_Match object; span=(0, 2), match=’12’> 返回一个对象,匹配到了一个数据,是12(match=’12’),范围是0-2
print_content_result(content) #输出 123 和分割线content2 = pattern.match('abc123def456')print(content2) # None:表示没有匹配到数据print_content_result(content2) #输出 分割线
“`
正则表达式的爬虫案例
import refrom urllib import request""" 正则表达式:爬虫小案例"""class ReSpider(object): def __init__(self): """ """ def loadPage(self, url, headers): """ load 需要爬取的页面 :param url: 页面的url :return: 返回抓取的网页 """ req = request.Request(url, headers=headers) resp = request.urlopen(req) return resp.read() def parsePage(self, content, pattern): """ 解析抓取的网页,进行一定的规则匹配 :param content: 网页内容 :param pattern: 解析模型 :return: 返回解析后的数据 """ list = pattern.findall(content) print(list) return list def writeFile(self, lists, filename): """ 将解析后的数据,写入到文件中 :param content: 解析后的数据 :return: 不返回数据 """ for item in lists: with open(filename, 'a', encoding='utf-8')as f: item = item.replace('<p>', '').replace('</p>', '').replace('<br>', '').replace('<br />', '') f.write(item)if __name__ == '__main__': """ 程序开始执行代码: """ url = 'http://www.neihan8.com/article/list_5_1.html' headers = { 'User-Agent': 'Mozilla/5.0(Windows NT 10.0; WOW64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.3427.400 QQBrowser/9.6.12513.400' } spider = ReSpider() # 加载页面 html = spider.loadPage(url, headers) gbk_html = html.decode('gbk') # 解析规则 pattern = re.compile(r'<div.*?class="f18 mb20">(.*?)</div>', re.S) # 解析页面 list = spider.parsePage(gbk_html, pattern) # 写入文件 spider.writeFile(list, 'content.txt')- 正则表达式及爬虫小案例
- 案例:使用正则表达式的爬虫
- 正则表达式,模拟网络爬虫小例子
- 正则表达式运用之小爬虫
- php正则表达式匹配字符串小案例
- javascript正则表达式(六)(小案例)
- javascript正则表达式(七)(小案例)
- Python笔记2--正则表达式与爬虫案例
- 正则表达式JS案例及相关语法
- Python 爬虫小程序(正则表达式的应用)
- python使用正则表达式编写网页小爬虫
- Java正则表达式—小应用—简易爬虫
- Java正则表达式—小应用—简易爬虫
- 《java入门第一季》之正则表达式小案例
- 《java入门第一季》正则表达式小案例
- 正则表达式,网页爬虫
- 爬虫 正则表达式
- Python爬虫 正则表达式
- day15Set接口
- (译)从全卷积网络到大型卷积核:深度学习的语义分割全指南
- EXTENDED LIGHTS OUT POJ
- 某项目网站频繁出现503问题解决
- VC生成不依赖高版本msvcrtXX.dll程序之方法一——完全抛弃CRT库
- 正则表达式及爬虫小案例
- 关于CaffeOnSpark 集群效率低下的问题解决方案
- 最小的K个数
- 实用框架收藏
- LInux设备驱动之按键轮询方式的
- 上机练习2 类与对象(3)
- Java中的八种锁
- nginx+keepalived实现主备服务器的高可用
- 记笔记--orm


