主成分分析(PCA)原理总结
来源:互联网 发布:合同软件 编辑:程序博客网 时间:2024/05/20 23:04
主成分分析(Principal components analysis,以下简称PCA)是最重要的降维方法之一。在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用。一般我们提到降维最容易想到的算法就是PCA,下面我们就对PCA的原理做一个总结。
1. PCA的思想
PCA顾名思义,就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。具体的,假如我们的数据集是n维的,共有m个数据
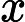
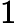
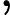

我们先看看最简单的情况,也就是n=2,n'=1,也就是将数据从二维降维到一维。数据如下图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向,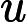
为什么
假如我们把n'从1维推广到任意维,则我们的希望降维的标准为:样本点到这个超平面的距离足够近,或者说样本点在这个超平面上的投影能尽可能的分开。
基于上面的两种标准,我们可以得到PCA的两种等价推导。
2. PCA的推导:基于小于投影距离
我们首先看第一种解释的推导,即样本点到这个超平面的距离足够近。
假设m个n维数据


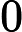
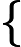
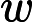
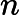
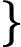
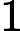
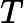
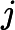
如果我们将数据从n维降到n'维,即丢弃新坐标系中的部分坐标,则新的坐标系为
如果我们用
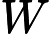
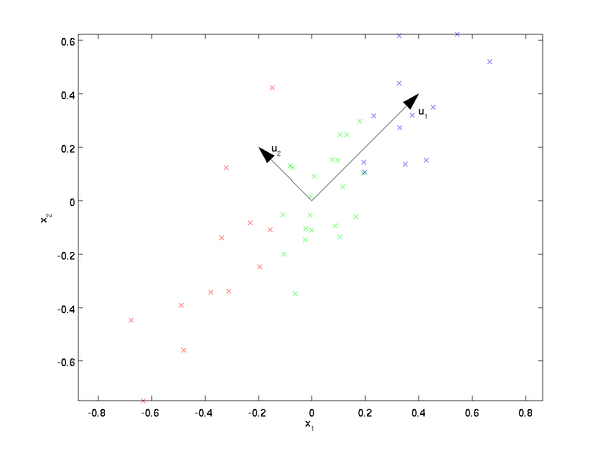
现在我们考虑整个样本集,我们希望所有的样本到这个超平面的距离足够近,即最小化下式:


将这个式子进行整理,可以得到:
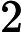


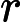 (
(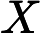
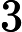
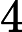
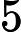
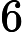
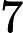
其中第(1)步用到了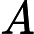

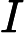
注意到

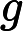
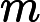
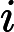
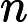
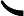
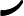
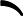
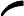

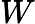
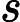
这个最小化不难,直接观察也可以发现最小值对应的W由协方差矩阵
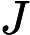
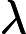
对W求导有
这样可以更清楚的看出,W为
如果你熟悉谱聚类的优化过程,就会发现和PCA的非常类似,只不过谱聚类是求前k个最小的特征值对应的特征向量,而PCA是求前k个最大的特征值对应的特征向量。
3. PCA的推导:基于最大投影方差
现在我们再来看看基于最大投影方差的推导。
假设m个n维数据
如果我们将数据从n维降到n'维,即丢弃新坐标系中的部分坐标,则新的坐标系为
对于任意一个样本
观察第二节的基于最小投影距离的优化目标,可以发现完全一样,只是一个是加负号的最小化,一个是最大化。
利用拉格朗日函数可以得到
对W求导有
() 和上面一样可以看出,W为
4. PCA算法流程
从上面两节我们可以看出,求样本
下面我们看看具体的算法流程。
输入:n维样本集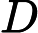
输出:降维后的样本集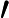
1) 对所有的样本进行中心化:
2) 计算样本的协方差矩阵
3) 对矩阵
4)取出最大的n'个特征值对应的特征向量
5)对样本集中的每一个样本
6) 得到输出样本集
有时候,我们不指定降维后的n'的值,而是换种方式,指定一个降维到的主成分比重阈值t。这个阈值t在(0,1]之间。假如我们的n个特征值为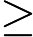
5. PCA实例
下面举一个简单的例子,说明PCA的过程。
假设我们的数据集有10个二维数据(2.5,2.4), (0.5,0.7), (2.2,2.9), (1.9,2.2), (3.1,3.0), (2.3, 2.7), (2, 1.6), (1, 1.1), (1.5, 1.6), (1.1, 0.9),需要用PCA降到1维特征。
首先我们对样本中心化,这里样本的均值为(1.81, 1.91),所有的样本减去这个均值后,即中心化后的数据集为(0.69, 0.49), (-1.31, -1.21), (0.39, 0.99), (0.09, 0.29), (1.29, 1.09), (0.49, 0.79), (0.19, -0.31), (-0.81, -0.81), (-0.31, -0.31), (-0.71, -1.01)。
现在我们开始求样本的协方差矩阵,由于我们是二维的,则协方差矩阵为:
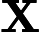


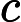

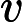

对于我们的数据,求出协方差矩阵为:
求出特征值为(0.490833989, 1.28402771),对应的特征向量分别为: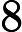
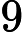
我们对所有的数据集进行投影
6. 核主成分分析KPCA介绍
在上面的PCA算法中,我们假设存在一个线性的超平面,可以让我们对数据进行投影。但是有些时候,数据不是线性的,不能直接进行PCA降维。这里就需要用到和支持向量机一样的核函数的思想,先把数据集从n维映射到线性可分的高维N>n,然后再从N维降维到一个低维度n', 这里的维度之间满足n'<n<N。
使用了核函数的主成分分析一般称之为核主成分分析(Kernelized PCA, 以下简称KPCA。假设高维空间的数据是由n维空间的数据通过映射
则对于n维空间的特征分解:
映射为:
通过在高维空间进行协方差矩阵的特征值分解,然后用和PCA一样的方法进行降维。一般来说,映射
7. PCA算法总结
这里对PCA算法做一个总结。作为一个非监督学习的降维方法,它只需要特征值分解,就可以对数据进行压缩,去噪。因此在实际场景应用很广泛。为了克服PCA的一些缺点,出现了很多PCA的变种,比如第六节的为解决非线性降维的KPCA,还有解决内存限制的增量PCA方法Incremental PCA,以及解决稀疏数据降维的PCA方法Sparse PCA等。
PCA算法的主要优点有:
1)仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
2)各主成分之间正交,可消除原始数据成分间的相互影响的因素。
3)计算方法简单,主要运算是特征值分解,易于实现。
PCA算法的主要缺点有:
1)主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
2)方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。
- 主成分分析(PCA)原理总结
- 主成分分析(pca)算法原理
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- 主成分分析(PCA)原理详解
- Python自动encoding
- windows上的tail指令使用
- Servlet 访问WEB资源的方式
- static
- Hadoop
- 主成分分析(PCA)原理总结
- canvas绘图基础
- Android SurfaceView 绘图覆盖刷新及脏矩形刷新方法
- C语言输入输出函数
- SQL存储过程批量插入
- 将字节转化成其他单位
- Postgres 10.1 安装步骤
- Leetcode 100 Liked Questions
- select、poll、epoll之间的区别总结


