Keras-2 Keras Mnist
来源:互联网 发布:windows资源管理器解锁 编辑:程序博客网 时间:2024/05/21 16:39
Keras Mnist
在这里,我们将利用Keras搭建一个深度学习网络对mnist数据集进行识别。
- 本文参考 keras-mnist-tutorial
- 整个代码分为三个部分:
- 数据准备
- 模型搭建
- 训练优化
让我们开始吧
首先先导入一些模块
%matplotlib inlineimport numpy as npimport matplotlib.pyplot as pltfrom keras.datasets import mnistfrom keras.models import Sequentialfrom keras.layers.core import Dense, Activation, Dropoutfrom keras.utils import np_utils数据准备
我们通过keras自带的数据集mnist进行导入数据,然后对其归一化处理,并且将原二维数据变成一维数据,作为网络的输入。
读入mnist数据集。可以看到每条样本是一个28*28的矩阵,共有60000个训练数据,10000个测试数据。
(X_train, y_train), (X_test, y_test) = mnist.load_data();print(x_train.shape)print(x_test.shape)(60000, 28, 28)(10000, 28, 28)将一些样本图像打印出来看看
for i in range(9): plt.subplot(3,3,i+1) plt.imshow(X_train[i], cmap='gray', interpolation='none') plt.title("Class {}".format(y_train[i]))
将二维数据变成一维数据
X_train = X_train.reshape(len(X_train), -1)X_test = X_test.reshape(len(X_test), -1)接下来对数据进行归一化。原来的数据范围是[0,255],我们通过归一化时靠近0附近。归一化的方式有很多,大家随意。
# uint不能有负数,我们先转为float类型X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = (X_train - 127) / 127X_test = (X_test - 127) / 127接下来 One-hot encoding
nb_classes = 10y_train = np_utils.to_categorical(y_train, nb_classes)y_test = np_utils.to_categorical(y_test, nb_classes)搭建网络
数据已经准备好了,接下来我们进行网络的搭建,我们的网络有三层,都是全连接网络,大概长的像这样 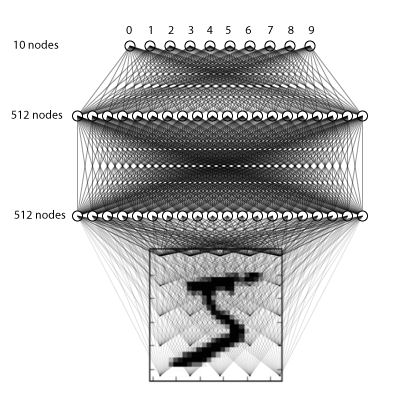
这里新遇到一个Dropout,这是一种防止过拟合(overfitting)的方法,详见Dropout层
model = Sequential()model.add(Dense(512, input_shape=(784,), kernel_initializer='he_normal'))model.add(Activation('relu'))model.add(Dropout(0.2)) model.add(Dense(512, kernel_initializer='he_normal'))model.add(Activation('relu'))model.add(Dropout(0.2)) model.add(Dense(nb_classes))model.add(Activation('softmax'))OK!模型搭建好了,我们通过编译对学习过程进行配置
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])那么我们进行训练吧
model.fit(X_train, y_train, epochs=20, batch_size=64, verbose=1, validation_split=0.05)Train on 57000 samples, validate on 3000 samplesEpoch 1/2057000/57000 [==============================] - 19s 327us/step - loss: 0.0811 - acc: 0.9761 - val_loss: 0.0702 - val_acc: 0.9810Epoch 2/2057000/57000 [==============================] - 19s 328us/step - loss: 0.0752 - acc: 0.9772 - val_loss: 0.0720 - val_acc: 0.9813Epoch 3/2057000/57000 [==============================] - 19s 331us/step - loss: 0.0687 - acc: 0.9788 - val_loss: 0.0670 - val_acc: 0.9830Epoch 4/2057000/57000 [==============================] - 20s 350us/step - loss: 0.0667 - acc: 0.9794 - val_loss: 0.0755 - val_acc: 0.9810Epoch 5/2057000/57000 [==============================] - 20s 353us/step - loss: 0.0688 - acc: 0.9794 - val_loss: 0.0671 - val_acc: 0.9820Epoch 6/2057000/57000 [==============================] - 20s 346us/step - loss: 0.0639 - acc: 0.9807 - val_loss: 0.0744 - val_acc: 0.9790Epoch 7/2057000/57000 [==============================] - 20s 342us/step - loss: 0.0626 - acc: 0.9805 - val_loss: 0.0685 - val_acc: 0.9837Epoch 8/2057000/57000 [==============================] - 21s 365us/step - loss: 0.0669 - acc: 0.9796 - val_loss: 0.0988 - val_acc: 0.9757Epoch 9/2057000/57000 [==============================] - 20s 345us/step - loss: 0.0605 - acc: 0.9819 - val_loss: 0.0769 - val_acc: 0.9833Epoch 10/2057000/57000 [==============================] - 19s 338us/step - loss: 0.0592 - acc: 0.9820 - val_loss: 0.0576 - val_acc: 0.9870Epoch 11/2057000/57000 [==============================] - 19s 336us/step - loss: 0.0600 - acc: 0.9822 - val_loss: 0.0689 - val_acc: 0.9847Epoch 12/2057000/57000 [==============================] - 20s 345us/step - loss: 0.0625 - acc: 0.9813 - val_loss: 0.0689 - val_acc: 0.9843Epoch 13/2057000/57000 [==============================] - 20s 346us/step - loss: 0.0573 - acc: 0.9829 - val_loss: 0.0679 - val_acc: 0.9853Epoch 14/2057000/57000 [==============================] - 19s 342us/step - loss: 0.0555 - acc: 0.9833 - val_loss: 0.0642 - val_acc: 0.9850Epoch 15/2057000/57000 [==============================] - 20s 359us/step - loss: 0.0571 - acc: 0.9831 - val_loss: 0.0779 - val_acc: 0.9833Epoch 16/2057000/57000 [==============================] - 21s 361us/step - loss: 0.0564 - acc: 0.9831 - val_loss: 0.0610 - val_acc: 0.9867Epoch 17/2057000/57000 [==============================] - 20s 354us/step - loss: 0.0574 - acc: 0.9834 - val_loss: 0.0669 - val_acc: 0.9867Epoch 18/2057000/57000 [==============================] - 20s 353us/step - loss: 0.0526 - acc: 0.9848 - val_loss: 0.0863 - val_acc: 0.9830Epoch 19/2057000/57000 [==============================] - 20s 349us/step - loss: 0.0548 - acc: 0.9832 - val_loss: 0.0726 - val_acc: 0.9847Epoch 20/2057000/57000 [==============================] - 20s 352us/step - loss: 0.0512 - acc: 0.9845 - val_loss: 0.0735 - val_acc: 0.9860<keras.callbacks.History at 0x2904822cd30>训练完毕,测试测试
loss, accuracy = model.evaluate(X_test, y_test)print('Test loss:', loss)print('Accuracy:', accuracy)10000/10000 [==============================] - 1s 80us/stepTest loss: 0.0864374790877Accuracy: 0.9817阅读全文
1 0
- Keras-2 Keras Mnist
- Keras MNIST
- kaggle mnist tensorflow+keras
- keras mnist cnn example
- DCGAN+keras生成mnist
- keras 识别Mnist
- keras
- keras
- keras
- Keras
- keras
- Keras
- keras
- 用keras实验mnist数据
- Keras-4 mnist With CNN
- Keras入门课2 -- 使用CNN识别mnist手写数字
- Keras 浅尝之MNIST手写数字识别
- 深度學習 Keras MNIST 數據可視化
- Description(关于如何取好二分)
- 开始的开始
- php数组排序(1)
- java集合Vector的功能
- python assert断言的用法
- Keras-2 Keras Mnist
- 习题6.13
- 一致性HASH算法详解
- 解决数据库中列名带特殊字符导致查询报错的问题
- 2017年NOIP普及组第三题“chess”题解
- PHP制作验证码
- ios-UITextView和UILabel遇到的问题
- zookeeper环境搭建(1)
- 关于css的规范


