【计算机视觉之二】人工神经网络
来源:互联网 发布:youtube 批量下载软件 编辑:程序博客网 时间:2024/05/16 17:33
目录
1. 线性分类器
1.1 线性分类器分类原理
1.2学习的误差—损失函数
2. 神经网络初步
2.1 什么是神经网络?
2.2 非线性可分问题
2.3 激活函数
3. 算法初步
3.1 BP算法
3.2 SGD(随机梯度下降)
3.3 反向传播详细栗子与运算过程
4. 练习案例—感知器案例+寒老师写的人工神经网络
1.线性分类器
1.1 分类原理
在分类问题中,提供了很多算法,比如LR,决策树,SVM,其中有一类称为线性分类器。比如,你要识别一张图片中的是猫,还是狗,还是图片中两者都有:

一般会把这张图片转变成[32x32x3]的向量矩阵,3为颜色通道,每一个维度的范围在0-255左右,然后把它拉成3072X1 的长列向量,用来表征这张图片中信息,用X表示,通过映射函数
小栗子: 
我们假设一张图片仅有图中
w中每一行代表了不同类别的权重参数,最后得到每个类别的得分。比如:
另外的理解:W的每一行,相当与其中一个类别的模版;得出每类的得分,相当于像素点与模版的匹配;匹配的方式为内积。
1.2学习的误差—损失函数
损失函数相当于一个衡量标准答案和模型学习的答案之间的差距,我们希望不断的调整W,使得模型学习的答案与标准的答案是一致的。
小栗子:
hinge loss/线性SVM的损失函数
假设上面那张猫的图片数据为
用公式表示:
代码实现:
def L_i(x, y, W): """ 计算svm中一个样本的多分类问题中的损失函数 - x是代表一张图片的一列向量(eg:3073 X 1 in CIFAR-10) 同时在第3073的位置上加上偏执值的维度 - y 是一个整型的类别标签 (e.g. between 0 and 9 in CIFAR-10) - W 是权值矩阵 (e.g. 10 x 3073 in CIFAR-10) """ delta = 1.0 # 相当于一个阀值 scores = W.dot(x) # 为每个类别打分 correct_class_score = scores[y] D = W.shape[0] # 标签的类别数量, e.g. 10 loss_i = 0.0 for j in xrange(D): # 迭代所有的错误类别 if j == y: # 跳过真正的类别标签(因为对的是没有损失的) continue # 计算所有样本的损失 loss_i += max(0, scores[j] - correct_class_score + delta) return loss_idef L_i_vectorized(x, y, W): """ A faster half-vectorized implementation. half-vectorized refers to the fact that for a single example the implementation contains no for loops, but there is still one loop over the examples (outside this function) """ delta = 1.0 scores = W.dot(x) # compute the margins for all classes in one vector operation margins = np.maximum(0, scores - scores[y] + delta) # on y-th position scores[y] - scores[y] canceled and gave delta. We want # to ignore the y-th position and only consider margin on max wrong class margins[y] = 0 loss_i = np.sum(margins) return loss_idef L(X, y, W): """ fully-vectorized implementation : - X holds all the training examples as columns (e.g. 3073 x 50,000 in CIFAR-10) - y is array of integers specifying correct class (e.g. 50,000-D array) - W are weights (e.g. 10 x 3073) """ # evaluate loss over all examples in X without using any for loops # left as exercise to reader in the assignment交叉熵损失(softmax分类器)
交叉熵损失函数会把得分向量转化为概率向量,转化方法如下:
工程小技巧:
C的选取一般可以选取分数最高的那个
f = np.array([123, 456, 789]) # example with 3 classes and each having large scoresp = np.exp(f) / np.sum(np.exp(f)) # Bad: Numeric problem, potential blowup# instead: first shift the values of f so that the highest number is 0:f -= np.max(f) # f becomes [-666, -333, 0]p = np.exp(f) / np.sum(np.exp(f)) # safe to do, gives the correct answer本质:评估两个概率向量之间的距离
更加详细的推导和动画演示可以参考:Michael Nielsen大牛的书
2.神经网络初步
2.1 什么是神经网络?

图为一个全连接的神经网络结构,数据在input layer中数据,通过一系列的隐藏层处理,然后在output layer中输出。
到底什么才是神经网络,我们可以拿一个简单,但本质性的东西出来看一下。

我们把右边的东西称之为感知器,x1,x2代表两个维度的数据,然后处理之后,通过一个S型函数,把
2.2 非线性可分问题
我们已经认识的LR处理的是线性可分的问题,但非线性问题应该怎么办呢?

如图所示,找不到一条直线,把原点和x点完全分开,但是可以用两条直线,就可以把他们完全分开了。这个操作,正是神经网络可以做的。
逻辑与

如图所示,神经网络可以在每个神经节点处训练一条边界线,然后通过最后的激活函数把这两条线合并在一起,让他们一起在分类任务中发挥作用。
逻辑或

用(-10,20,20)这组参数来计算,由右下表可以发现,只要由1,结果就会为1。以
即只要有1,就能分为正类,完成了逻辑或的操作。
神经网络对他们进行组合,最后可以得到:

利用and的操作可以取得很多分割的空间区域,然后用or的操作,可以把这些分割的区域中,颜色一样的区域作为同一类。
非常完美得解决了非线性可分问题。
2.3 激活函数
如图

为两种激活函数图,这种激活函数会分布在我们网络中的各个节点。
可以从两个角度来理解这样的激活函数:
A. 信号传递
假如现在有一阵风过来,你正在打电话,如果是微风,你会停止打电话这个动作吗?假如是龙卷风+雷阵雨,你会停止打电话吗?
用在这里,可以把激活函数理解为一种过滤网,它能把一些像微风这个的噪声数据去除掉,而让龙卷风这样的数据通过网络,让人最后作出合理的行动。
B.非线性变换
如果我们不在中间加一些非线性的变换,那如果是两层的神经元:
3.算法初步
3.1 BP算法
BP算法的本质有两个方面:正向传播求损失,反向传播回传误差。
举个小栗子:
假如你在做高考模拟题的时候发现有一道数列的题不会做,然后仔细看一下到底是哪些知识点没掌握呢?这时候就是损失的计算。计算完之后,考完了,再回去看一下到底是哪里不会,然后再学习一下,争取在下一次考试的时候,再遇到类似这道题可以做好。回去复习就类似回传误差。
整体的过程就是下面的图示了:

好吧,估计这个小栗子不怎么好吃,再来一个好吃一点的栗子吧。

假如这是一个回归的问题,最后预测的结果是一个连续值,分别是
本想用白话来说的,但还是数学表达式更形象。
3.2 SGD(随机梯度下降) 
这个方法主要是为了优化损失函数,假设损失函数是凸函数(也就是极值点就是最值点的函数)。随机梯度下降主要把握三个方面的内容:
当前所在的位置:也就是参数的取值与损失的表征。
方向:因为每次下山,可爱的孩子为了不迷路,都要看一下四周,那边是最快下山的,所以方向很重要。在数学上用梯度来表征方向。
步长:假设孩子是一个大个,如果步长太大了,有可能会就走几步,就走过最低点了,导致离最低点的比较远。也可能是孩子腿太短,哎呀,搞得走了很久才走到山脚。用计算机语言来说,就是步长太小,时间复杂度太高;步长太大,找不到山底究竟在哪里。这里表示学习率。
SGD:每个样本求损失
GD:所有样本求损失
minibatch:在一批数据上求损失
3.3 反向传播详细栗子与运算过程
为了简单起见,我们用个简单的网络结果:分别有两个输入节点,两个隐藏节点,两个输出节点,而且还带了偏执值,结构如图:

为了有一些数值运算,我们线初始化我们的输入,权重参数值如下:

反向传播的目标是优化权重参数,使得学习出一个最好的映射函数把输入映射到输出。
在本例中,我们给定了输入0.05,0.10,希望可以得到输出0.01,0.99。使用sigmoid函数作为激活函数,来算一下每个节点的值是怎么变化的。
第一步-计算节点输出值
计算隐层:
计算输出层:
把h1的输出作为o1的输入,再用同样的方法:
第二步-计算误差
得到输出之后,学的到底怎么样,还得和标准答案对比一下,因此计算一下它与标准答案的差距:
想学一下更高深的:这本书讲神经网络中的数学还是很不错的
我们的标准答案分别是:0.01,0.99,可以计算一下误差:
第三步-反向传播
我们的目标是调整权重参数,使得输出值接近我们的标准答案,因此最小化损失函数(误差)。
先考虑
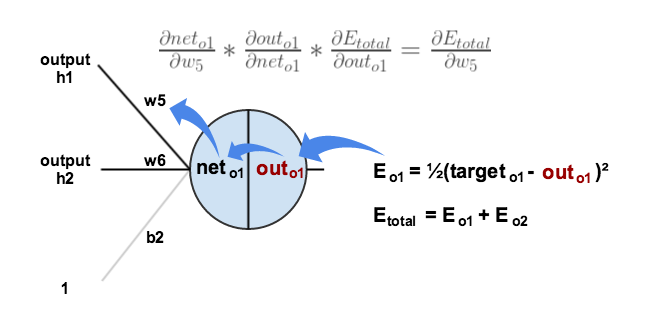
我们需要确定这条链中的每一个部分:
先看
然后再来算第二个:
再算最后一个:
终于得到总的了:
这样就能更新
计算隐层的时候方法也类似:

需要注意的是计算隐层的时候,误差是由两个结果的,因为隐层对两个输出均有影响。
这个栗子更加详细的推导可以查看:反向传播的详细栗子(英文的)
反向传播实例:python实现反向传播
反向传播可视化:点击start,看一下怎么传播的
4.练习案例
有一位大牛手写的,感觉挺不错
感知器实现
手写人工神经网络
参考:
七月深度学习课
斯坦福大学cs231n
反向传播栗子
- 【计算机视觉之二】人工神经网络
- 二十二、神奇算法之人工神经网络
- 人工智能之人工神经网络
- 人工神经网络之自适应神经网络
- 数据挖掘学习笔记之人工神经网络(二)
- 数据挖掘学习笔记之人工神经网络(二)
- 【计算机视觉】背景建模之PBAS<二>
- 机器学习之人工神经网络
- 人工神经网络之乳腺癌识别
- 人工智能之人工神经网络-纵览
- 人工神经网络之激活函数
- 人工神经网络之Python 实战
- 数据挖掘之人工神经网络
- 人工神经网络之我见-【神经网络的原理】
- 人工神经网络之BP神经网络模型
- 计算机视觉与卷积神经网络
- 计算机视觉与卷积神经网络
- 人工神经网络(二)单层感知器
- linux 使用pip3和pip安装numpy,scipy,matplotlib等第三方库
- java集合ArrayList<E>的自身嵌套
- HDU2844 Coins(多重背包)
- 【java】【开源代码分析】java并发编程与junit4
- 【java】--@PathParam 和@QueryParam
- 【计算机视觉之二】人工神经网络
- LeetCode 537. Complex Number Multiplication
- python 编写简单网页服务器
- 闭包中变量访问问题(笔试题)
- ITSM基础框架开发维护指南
- 第四第三公司小项目简单angularjs
- Linux中模拟shell实现ls命令(不加参数)
- Mysql01_基本类型与建表的sql
- C++并发编程学习——3.在线程间共享数据


