myeclipse下搭建hadoop2.7.3开发环境
来源:互联网 发布:sql表添加列在某个字段 编辑:程序博客网 时间:2024/06/05 20:07
需要下载的文件:链接:http://pan.baidu.com/s/1i5yRyuh 密码:ms91
一 下载并编译 hadoop-eclipse-plugin-2.7.3.jar
二 将hadoop-eclipse-plugin-2.7.3.jar放到myeclipse的安装目录下的plugins目录下,并重启myeclipse
在windows->preferences下可看见hadoop Map/Reduce界面,路径选择你WINDOWS下的hadoop解压后的路径。

三 选择Windows->show view->others下的MapReduce Locations

四 新建一个配置 配置如下
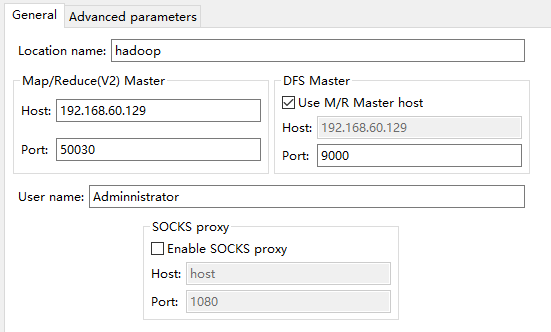
host为你的远程hadoop待连接的主机IP地址
Port:50030 对应mapred-site.xml下的jobtracher地址,如下

Port:9000对应core-site.xml下的fs.default.name的端口

user name 填你windows的用户名;
修改Advanced parameters下的参数

值对应 core-site.xml下的hadoop.tmp.dir参数

修改hdfs-site.xml下的dfs.permissions参数,允许连接

四 保存配置参数并重启myeclipse,可以看见如下的文件结构说明配置连接成功。
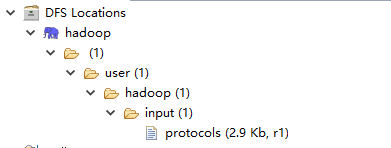
五 下载hadoop.ll和winutils.exe 到windows的hadoop/bin目录下

并将hadoop.dll添加到windows->system32目录下
五 环境测试
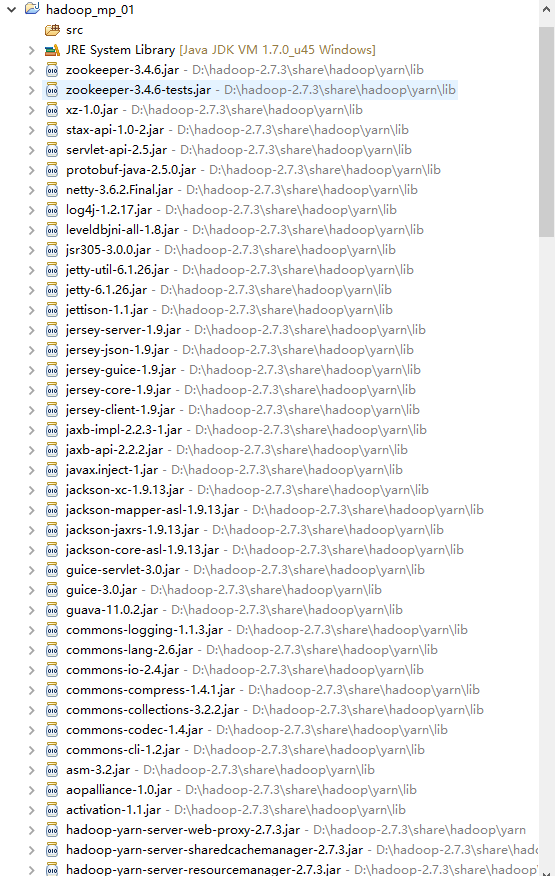
新建项目:File-->New-->Other-->Map/Reduce Project ,项目名可以随便取
它会自动添加依赖包,如下:
新建如下文件:
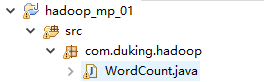
编写实现代码,与官方例子为例
package com.duking.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println(otherArgs.length);
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- myeclipse下搭建hadoop2.7.3开发环境
- myeclipse下搭建hadoop2.7.3开发环境
- Eclipse下搭建Hadoop2.7.3开发环境
- hadoop2.7.3-windows下开发环境搭建
- Eclipse下搭建Hadoop2.4.0开发环境
- Eclipse下搭建Hadoop2.4.0开发环境
- Eclipse下搭建Hadoop2.4.0开发环境
- Eclipse下搭建Hadoop2.7.0开发环境
- Eclipse下搭建Hadoop2.7.0开发环境
- Myeclipse下搭建Struts开发环境搭建
- CentOS7 + Hadoop2.7.3开发环境搭建
- Windows下SVN+MyEclipse开发环境搭建
- Windows下SVN+MyEclipse开发环境搭建
- Myeclipse 下搭建android 开发环境
- Windows下SVN+MyEclipse开发环境搭建
- windows下搭建MyEclipse开发环境
- Mac下搭建myEclipse开发环境
- MyEclipse下搭建SSH开发环境
- SAP Adobe form
- 短视频产品的必备功能:自动联播功能的设计
- ArrayList和LinkedList的区别
- 史上最简单的SpringCloud教程
- Treeview
- myeclipse下搭建hadoop2.7.3开发环境
- C++11时代的标准库快餐教程(4)
- poj 1573 Robot Motion 【模拟】【刷题计划】
- 安装redis并加入window服务
- BLE总结
- 商品入库、删除
- webpack开发环境与生产环境分离
- 翻译:Linux Graphics的现状
- JAVA字符串格式化-String.format()的使用


