图像超分辨EnhanceNet- Single Image Super-Resolution Through Automated Texture Synthesis笔记
来源:互联网 发布:上瘾网络剧删减部分 编辑:程序博客网 时间:2024/04/29 22:55
图像超分辨EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis笔记
简介
- 作者写这篇文章,主要是提出了损失函数的改进。传统的损失函数是MSE,虽然很好优化,但它是所有可能的纹路取平均的结果,因此看起来较为平滑,很不自然。因此,作者将提出一个不同的损失函数,联合对抗训练,来提高SISR的感知质量。
SISR
- 文中列举了一个用不同损失函数超分辨的示意图:
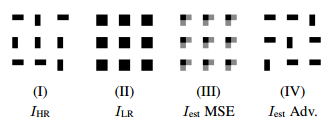
- 在降采样得到LR时,HR的细节信息已经丢失了,如果用MSE作为损失函数,只会估计出所有可能的平均值。而单纯使用对抗损失虽然不是像素级的精确,但可以生成更加真实的细节。
模型
- 作者使用的网络结构如下:
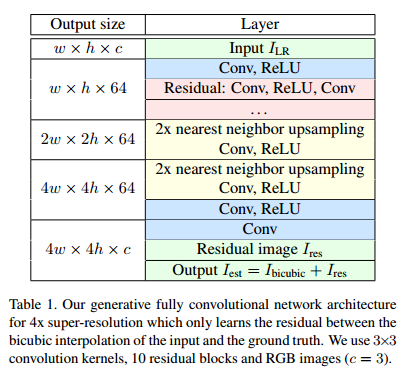
- 关于升采样部分,最自然想到的是一开始就用双三次插值,但这样会增加网络的计算量。如果在后面用解卷积,又会引入环状效应,还额外需要正则项。最后作者选择使用引入环状效应更小的最近邻升采样。
损失函数
- 除了MSE损失,作者还引入了其他损失函数。
Perceptual loss in feature space
- 这个损失的计算是把
Iest 和IHR 送入一个函数ϕ ,计算在ϕ 映射下的L2损失:LP=||ϕ(Iest)−ϕ(IHR)||22 。 - 一般
ϕ 可以用预训练好的VGG19在第二和第五池化层的输出。
Texture matching loss
- 该损失的表示为:
LT=||G(ϕ(Iest))−G(ϕ(IHR))||22 ,其中G为gram matrixG(F)=FFT 。 - 这个和分割迁移的损失类似,用在这的主要目的是生成和HR图像相似的局部纹路。经验是16*16生成的效果最好。
Adversarial training
- 没理解:we keep track of the average performance of the discriminator on true and generated images within the previous training batch and only train the discriminator in the subsequent step if its performance on either of those two samples is below a threshold.
实验
- 首先对比几个不同的损失函数:

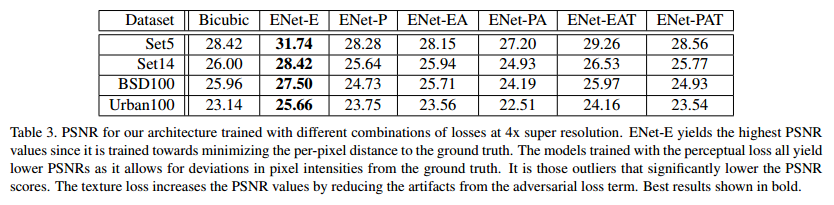
- 可以看出来,只用MSE生成的相当模糊,而只用Perceptual loss又会引入不必要的高频结构。但引入了Texture matching loss后,效果就好了非常多。虽然ENet-E的PSNR最高,但是视觉上的质量并不是最好的。
阅读全文
0 0
- 图像超分辨EnhanceNet- Single Image Super-Resolution Through Automated Texture Synthesis笔记
- 图像超分辨EDSR:Enhanced Deep Residual Networks for Single Image Super-Resolution,论文笔记
- 图像超分辨技术(Image Super Resolution)
- 图像超分辨LapSRN:Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution论文笔记
- “Single Image Super-resolution using Deformable Patches”
- 【超分辨率】Enhanced Deep Residual Networks for Single Image Super-Resolution
- 基于稀疏表示的图像超分辨率《Image Super-Resolution Via Sparse Representation》
- Single-Image Super-Resolution via Linear Mapping of Interpolated Self-Examples笔记
- 《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network》阅读笔记
- Seven ways to improve example-based single image super resolution笔记
- 《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network》阅读笔记
- Enhanced Deep Residual Networks for Single Image Super-Resolution
- Enhanced Deep Residual Networks for Single Image Super-Resolution
- 【超分辨率】Deeply-Recursive Convolutional Network for Image Super-Resolution
- 图像超分辨
- Poisson Image Editing & Texture Based Terrain Synthesis
- Deeply-Recursive Convolutional Network for Image Super-Resolution 笔记
- 论文阅读笔记:Image Super-Resolution Using Deep Convolutional Networks
- 一级购物车布局
- 事件分发机制
- HDFS_基本概念
- 查询添加2
- Android打开摄像头拍照,并显示出来
- 图像超分辨EnhanceNet- Single Image Super-Resolution Through Automated Texture Synthesis笔记
- APK瘦身全面总结——如何从32.6M到13.6M
- 文章标题
- java list或数组通过逗号分隔(类似split)
- iOS安装CocoaPods 实现第三方的快捷安全引入
- Spring学习总结——Spring实现AOP的多种方式
- 在线算命_周易占卜_生辰八字算命_姓名测试,免费算命【最准八字算命王网站-视频讲解】
- 【转载】重写与重载的关系
- Android Studio变量批量重命名快捷键


