Feature Pyramid Networks for Object Detection 阅读笔记
来源:互联网 发布:lms软件介绍 编辑:程序博客网 时间:2024/06/01 07:53
Feature Pyramid Networks for Object Detection 阅读笔记
标签(空格分隔): 论文笔记 物体检测
该论文主要提出了top-down的思想,对图像进行进行多尺度物体检测,尝试解决尺度不变性的问题Feature pyramids(多尺度特征金字塔)在传统的计算机视觉算法中进场被用到,而在深度学习中,都尽量避免使用多尺度相关的算法,因为一旦涉及多尺度,计算量将成倍增加。
在这篇论文中,作者认为在卷积网络中的每一层,就对应一个尺度的特征,然而在目前的网络中,只是用到了最后一层尺度的特征,于是作者提出了Feature Pyramid Network(FPN). FPN结构在进行物体检测时,不光用到了最后卷积层的feature map,同时也将之前层的feature map结合起来。该结构是结合了Faster RCNN。
- In this paper, we exploit the inherent multi-scale, pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost.
- A top-down architecture with lateral connections is developed for building high-level semantic feature maps at all scales.
作者给出了目前四种常见利用多尺度信息的方法:
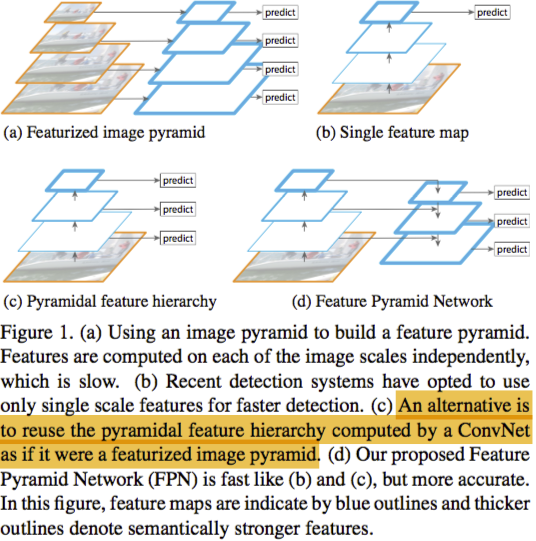
(a)该方法是现将输入图像进行resize后喂入算法,进行分类和回归,早期的深度学习算法基本上都是这样做的;
(b)这是目前最常见的,将图像送入网络,去最后一层的feature map进行分类回归;
(c)这是利用每一层的feature map进行分类回归最后,进行融合,这种形式代表性的是SSD,但是SSD中,是在基础网络中添加了几个卷积层,然后添加的几个卷积层的feature map进行分类回归;
(d)这是作者提出来的。
这篇论文给出了两个关键的词语bottom-up和top-down
bottom-up:就是底层信息向高层传播,在深度学习中,网络结构是以层级结构进行排布的,图像从输入到输出,信息是由底层到高层传播的,所谓底层信息就是图像的轮廓,纹理等底层的形状信息;所谓高层信息就是图像的类别,物体的关键部位等高层的语义信息,故bottom-up就是网络的前向传播过程。
top-down:就是高层信息往底层传播,这里的信息是每层的fearure map而非梯度
在这里要解释为什么会存在top-down这样的操作?
因为图像需要检测比较小的物体,直接说就是细粒度的问题,这篇论文(Beyond Skip Connections: Top-Down Modulation for Object Detection)给了个说法,它是这样解释的:高层信息往往语义层面的,是粗糙的,对物体的性状描述是不细腻的;而底层信息是对图像的形状描述是精致的,于是在进行微小物体检测时,最好的方法,是将高层的语义信息和底层的形状信息结合起来。
再来说说,作者是怎么个结合的。。
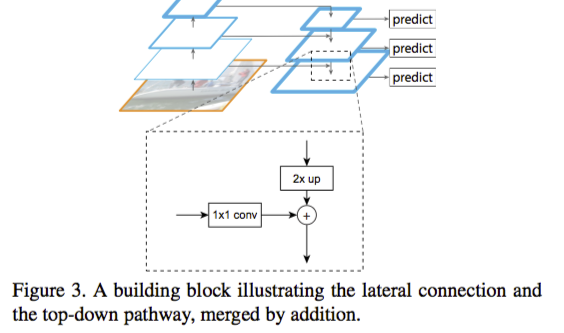
(1)左边箭头依次朝上是bottom-up, 右边的箭头朝下是top-down的过程
(2)网络传至卷积最后一层之后,进行上采样(caffe 中进行反卷积操作)还原层上一层的尺度,然后 与上一层的feature map相加,如此下去;
(3)作者还提出为了保证top-down过程中,feature map的channel一致,进行了
Github:https://github.com/unsky/FPN-caffe
网络可视化:http://ethereon.github.io/netscope/#/editor
- Feature Pyramid Networks for Object Detection 阅读笔记
- Feature Pyramid Networks for Object Detection 论文笔记
- 论文笔记:Feature Pyramid Networks for Object Detection
- Feature Pyramid Networks for Object Detection 学习笔记
- Feature Pyramid Networks for Object Detection
- Feature Pyramid Networks for Object Detection
- Feature Pyramid Networks for Object Detection 总结
- READING NOTE: Feature Pyramid Networks for Object Detection
- [Paper note] Feature Pyramid Networks for Object Detection
- 目标检测--Feature Pyramid Networks for Object Detection
- 目标检测“Feature Pyramid Networks for Object Detection”
- 论文解读之Feature Pyramid Networks for Object Detection
- FPN(Feature Pyramid Networks for Object Detection)安装与训练
- [水水文]Feature Pyramid Networks for Object Detection
- 目标检测 Feature Pyramid Networks for Object Detection(FPN)论文笔记
- Object Detection -- 论文FPN(Feature Pyramid Networks for Object Detection)解读
- FPN Feature Pyramid Network for Object Detection
- 论文阅读笔记:Object Detection Networks on Convolutional Feature Maps
- 机器学习_初识神经网络
- xml---4种解析方式dom,sax,jdom,dom4j
- cron 表达式详解
- Error updating database. Cause: java.sql.SQLException: Could not retrieve transation read-only stat
- 简单的冒泡排序实现
- Feature Pyramid Networks for Object Detection 阅读笔记
- 【OpenCV入门教程之十】 形态学图像处理(一):膨胀与腐蚀
- JavaWeb中filter的详解及应用案例
- java笔记2
- Jenkins实现测试环境到生产环境一键部署(Windows)
- Bootstrap学习
- Windows操作pip+selenium(python环境)
- Listener监听器
- Oracle脱库脚本


