ConcurrentLinkedHashMap设计与代码解析
来源:互联网 发布:光子 知乎 编辑:程序博客网 时间:2024/06/11 22:33
ConcurrentLinkedHashMap设计与代码解析
ConcurrentLinkedHashMap是google 开源的线程安全的方便并发的Map, Map利用LRU缓存机制(Least recent use 最近最少使用)对Map中存储对象进行换入换出管理,对项目中要求LRU缓存的可以利用.本文是在参阅原开源项目设计文档以及代码阅读的基础上的一个总结,由于能力有限,总结可能存在误差,读者在该开源项目主页下载源代码,阅读设计文档,以更深入熟悉ConcurrentLinkedHashMap的设计
1.总体设计
- 1.1 ConcurrentLinkedHashMap 的主要设计思路
- (1).为提高命中率,采用LRU策略进行存储对象的换入与换出,通过Weigher计算每一个Entry占用的存储单元数(对于分布均匀的,一般一个entry的weightedValue 为1),当存储单元超过预设的Capacity时,需要按照LRU策略换出最近最少使用的Entry, 以LinkedDeque(双向链表实现的队列数据结构) evictionDeque实现LRU策略,每次读写,将Entry移至队尾,换出时从队首依次换出。
- (2).为提高并发,减少进程在争取Map资源时产生的时间消耗, 采用两套资源控制机制,一套同步机制,使用ConcurrentMap对对象数据进行KV存储,保证多线程并发安全地调用Map资源,而对于存储对象的换入换出管理则采用异步机制,使用Queue buffer存储每次的因对象读写而产生的对象换入换出任务(为更好地并发,设置多个buffer, 线程根据线程号映射到不同buffer),当遇到读任务超过阈值或写任务或者时,加锁后,执行buffer中的多个任务,依次对evictionDeque进行节点调整,需要移除的数据,从map中移除。
2.代码解析
- 2.1相关类。
- (1)Weigher 是一个计算每条记录占用存储单元数接口,项目在类Weighers中给了许多针对不同需求的计算方式,如Byte 数组可以通过数组长度计算为存储单元个数,而就一般应用的存储对象,可以直接用SingletonWeigher,每条记录占用一个存储单元。
@ThreadSafepublic interface Weigher<V> { /** * Measures an object's weight to determine how many units of capacity that * the value consumes. A value must consume a minimum of one unit. * * @param value the object to weigh * @return the object's weight */ int weightOf(V value);}- : (2)**WeightedValue**是对Value的装饰,包含了Value占用的存储单元个数weight值,以及根据weight值计算状态(pos->active, kept in map and queue; 0->retire,deleted from map but not from queue; neg->dead, deleted from map and queue)
- (3)Node 实现了链接表中Linked Node,便于LinkedDeque的双向索引,是Map以及evictionDeque存储对象。
(4)Task 是针对存储对象LRU顺序操作的抽象类,继承自Task的有ReadTask, AddTask, UpdateTask,RemoveTask, 每一个Task有一个根据创建顺序分配的order.
/** A skeletal implementation of the <tt>Task</tt> interface. */ abstract class AbstractTask implements Task { final int order; Task task; AbstractTask() { order = nextOrdering(); } @Override public int getOrder() { return order; } @Override public Task getNext() { return task; } @Override public void setNext(Task task) { this.task = task; } }ReadTask 将当前read的记录移至evictionDeque队尾
AddTask 将记录插至evictionDeque队尾,并且查看插入后,将新纪录的weight值加到总的weight值中,判断更新后的weighted是否超过capacity, 如果超过,则从队首删除,直至不超
public void run() { weightedSize += weight; // ignore out-of-order write operations if (node.get().isAlive()) { evictionDeque.add(node); evict(); //queue的删除调整 } }UpdateTask 将更新后的记录移至evictionDeque队尾,并且查看插入后,将新纪录的差量weight值加到总的weight值中,判断更新后的weighted是否超过capacity, 如果超过,则从队首删除,直至不超。
public void run() { super.run(); weightedSize += weightDifference; evict();//queue的删除调整 }RemoveTask 将记录从队列中删除,并更新Node状态
public void run() { // add may not have been processed yet evictionDeque.remove(node); node.makeDead(); }2.2主要操作过程
get 操作,首先从Map中读取,再添加一个addTask用于调整queue中LRU order
public V get(Object key) { final Node node = data.get(key); if (node == null) { return null; } afterCompletion(new ReadTask(node)); //添加task return node.getValue(); }put 操作稍微复杂,需要判断是否只在缺少才插入(putIfAbsent),如果不存在,直接插入,如果存在, 而不是只在不存在的情况下插入,则更新。
V put(K key, V value, boolean onlyIfAbsent) { checkNotNull(value); final int weight = weigher.weightOf(key, value); //计算weight final WeightedValue<V> weightedValue = new WeightedValue<V>(value, weight); final Node node = new Node(key, weightedValue); //创建新node for (;;) { final Node prior = data.putIfAbsent(node.key, node); //插入 if (prior == null) { afterCompletion(new AddTask(node, weight)); //插入成功(第一次插入) return null; } else if (onlyIfAbsent) { //对于只有在空缺时插入的情况,已经存在,则添加调整queue任务后返回 afterCompletion(new ReadTask(prior)); return prior.getValue(); } for (;;) { final WeightedValue<V> oldWeightedValue = prior.get(); if (!oldWeightedValue.isAlive()) { break; } if (prior.compareAndSet(oldWeightedValue, weightedValue)) { //更新值 final int weightedDifference = weight - oldWeightedValue.weight; final Task task = (weightedDifference == 0) ? new ReadTask(prior) //weight没变,按照read逻辑 : new UpdateTask(prior, weightedDifference); afterCompletion(task); return oldWeightedValue.value; } } } }remove
final Node node = data.remove(key); if (node == null) { return null; } node.makeRetired(); //retrire, will remove from queue after task afterCompletion(new RemovalTask(node)); return node.getValue();2.3 LRU 管理
LRU的管理是对通过task的调度与执行完成的。在2.2中看到,每个人物的执行都是由afterCompletion装饰,改函数会根据task类型以及buffer中task数量决定是否要进行一次queue 中对象的LRU order调整,代码如下
void afterCompletion(Task task) { boolean delayable = schedule(task); if (shouldDrainBuffers(delayable)) { //status 判定 tryToDrainBuffers(AMORTIZED_DRAIN_THRESHOLD); } notifyListener(); }schedule 函数负责将task 根据线程id映射到不同task buffer队列中,并判断, 如果是写类型的task,则需要调整, 如果是都类型并且buffer中task量超过阈值也需要调整(drain)。
tryToDrainBuffers将会执行所有task,实现LRU调整。
void drainBuffers(int maxToDrain) { // A mostly strict ordering is achieved by observing that each buffer // contains tasks in a weakly sorted order starting from the last drain. // The buffers can be merged into a sorted list in O(n) time by using // counting sort and chaining on a collision. // The output is capped to the expected number of tasks plus additional // slack to optimistically handle the concurrent additions to the buffers. Task[] tasks = new Task[maxToDrain]; // Moves the tasks into the output array, applies them, and updates the // marker for the starting order of the next drain. int maxTaskIndex = moveTasksFromBuffers(tasks); runTasks(tasks, maxTaskIndex); updateDrainedOrder(tasks, maxTaskIndex); }3.效率
读效率 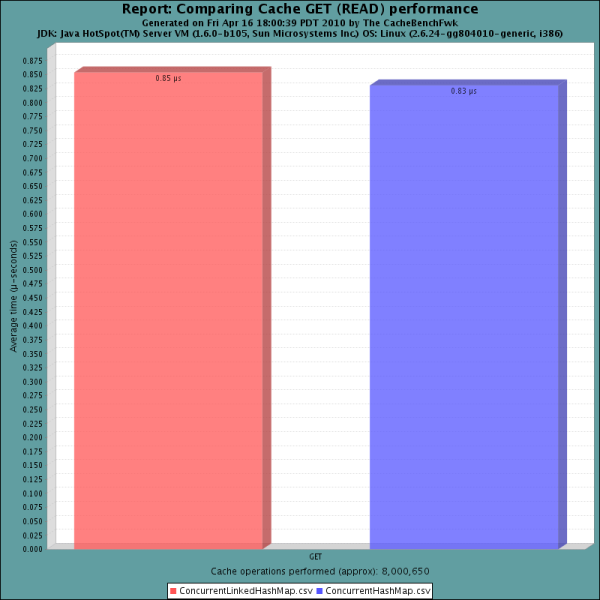
写效率 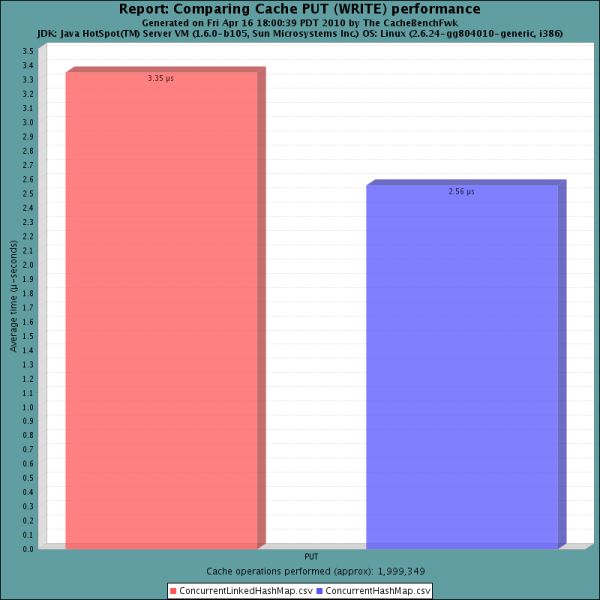
- ConcurrentLinkedHashMap设计与代码解析
- google的ConcurrentLinkedHashmap源代码解析
- concurrentlinkedhashmap
- concurrentlinkedhashmap 使用用例
- 重构与设计解析
- 双边滤波器解析与代码
- Karto_slam框架与代码解析
- 权限表设计之代码解析
- 设计视图与代码视图
- C++代码设计与重用
- 测试代码 与 设计文档
- 代码设计与敏捷开发
- 设计模式解析与实现(备忘)
- UML面向对象分析与设计解析
- 解析Android Widget设计与开发(1)
- 图片缓存框架解析与设计
- LED平板灯结构解析与设计
- Android源码设计模式解析与实战
- Python的元组被设计成不可变的影响
- 从菜鸡到咸鱼(二)
- 静态成员变量静态代码块和构造方法的执行顺序
- okhttp3相关封装配置(一):OkHttpClient的参数配置
- 模拟实现vcetor库
- ConcurrentLinkedHashMap设计与代码解析
- 中国独立游戏简史
- 表格内外边框属性测试
- General Thread States
- Java基础知识-9、对象继承和多态
- 2017-11-28
- Matlab中计算程序运行时间的三种方法
- MapReduce原理与设计思想
- plot函数属性(转自matplotlib)


