利用docker搭建spark hadoop workbench
来源:互联网 发布:淘宝闲鱼官方下载 编辑:程序博客网 时间:2024/05/29 17:51
目的
- 用docker实现所有服务
- 在spark-notebook中编写Scala代码,实时提交到spark集群中运行
- 在HDFS中存储数据文件,spark-notebook中直接读取
组件
- Spark (Standalone模式, 1个master节点 + 可扩展的worker节点)
- Spark-notebook
- Hadoop name node
- Hadoop data node
- HDFS FileBrowser
实现
最初用了Big Data Europe的docker-spark-hadoop-workbench,但是docker 服务运行后在spark-notebook中运行代码会出现经典异常:
 View Code
View Code
发现是因为spark-notebook和spark集群使用的spark版本不一致. 于是fork了Big Data Europe的repo,在此基础上做了一些修改,基于spark2.11-hadoop2.7实现了一个可用的workbench.
运行docker服务
docker-compose up -d
扩展spark worker节点
docker-compose scale spark-worker=3
测试服务
各个服务的URL如下:
Namenode: http://localhost:50070Datanode: http://localhost:50075Spark-master: http://localhost:8080Spark-notebook: http://localhost:9001Hue (HDFS Filebrowser): http://localhost:8088/home
以下是各个服务的运行截图
HDFS Filebrower

Spark集群

Spark-notebook

运行例子
1. 上传csv文件到HDFS FileBrowser,
2. Spark notebook新建一个notebook
3. 在新建的notebook里操作HDFS的csv文件
具体的步骤参考这里
以下是spark-notebook运行的截图:
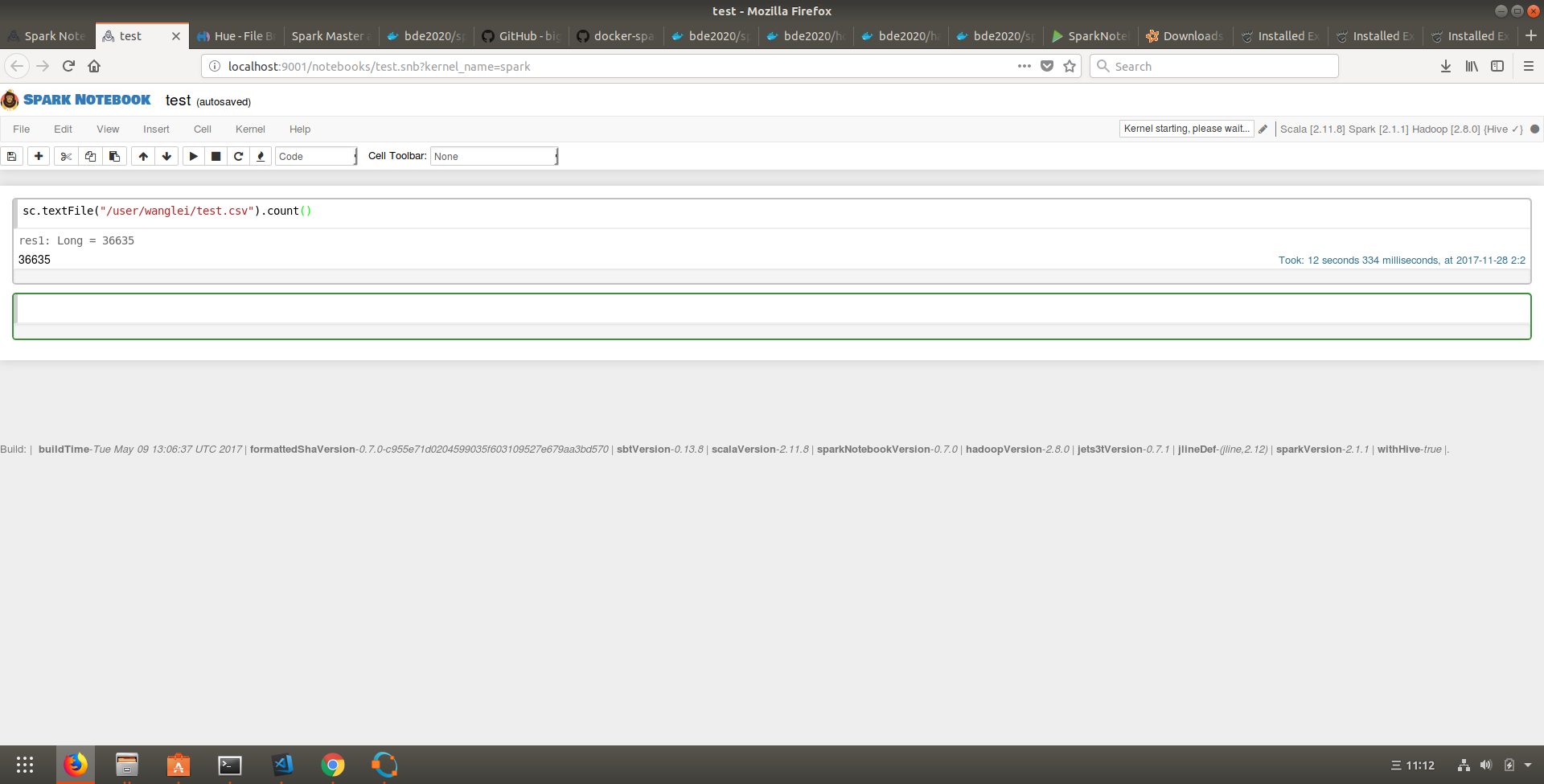
代码链接
阅读全文
0 0
- 利用docker搭建spark hadoop workbench
- 快速搭建docker spark+hadoop计算环境
- 利用Docker Compose 搭建Spark 集群
- 在基于docker的Hadoop集群上搭建Spark
- Docker搭建hadoop集群
- docker搭建hadoop
- 【hadoop+spark】搭建spark过程
- 搭建spark-hadoop集群
- hadoop+spark集群搭建
- Hadoop+Spark集群搭建
- Hadoop/Spark平台搭建
- hadoop spark 环境搭建
- Spark+Hadoop环境搭建
- Hadoop&Spark搭建
- 用docker搭建spark集群
- 用 Docker 搭建 Spark 集群
- 在Docker上使用Weave搭建Hadoop和Spark跨主机容器集群
- 利用Docker创建hadoop集群
- udev和mdev学习总结
- 直播技术简单介绍之直播协议
- flask模板
- [LeetCode]20_Valid Parentheses
- Scala-模式匹配
- 利用docker搭建spark hadoop workbench
- 一组PHP可逆加密解密算法
- javascript原型链的理解
- Android App插件式换肤实现方案
- Python中文编码问题(字符串前面加'u')
- 文案而已,咋就那么多戏?
- 桥接模式(Bridge Pattern)
- 12月课程表|线下实战演练,快速提升你的运营能力
- SQL中使用WITH AS提高性能-使用公用表表达式(CTE)简化嵌套SQL


