PersonalRank:一种基于图的推荐算法
来源:互联网 发布:mac如何装win10 编辑:程序博客网 时间:2024/05/18 01:08
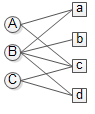
上面的二部图表示user A对item a和c感兴趣,B对a b c d都感兴趣,C对c和d感兴趣。本文假设每条边代表的感兴趣程度是一样的。
现在我们要为user A推荐item,实际上就是计算A对所有item的感兴趣程度。在personal rank算法中不区分user节点和item节点,这样一来问题就转化成:对节点A来说,节点A B C a b c d的重要度各是多少。重要度用PR来表示。
初始赋予 

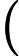
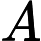




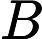
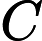

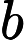
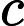
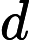

然后开始在图上游走。每次都是从PR不为0的节点开始游走,往前走一步。继续游走的概率是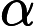

第一次游走, 从A节点以各自50%的概率走到了a和c,这样a和c就分得了A的部分重要度,

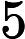
第二次游走,分别从节点A a c开始,往前走一步。这样节点a分得A 


经过以上推演,可以概括成公式:
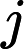









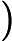
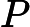



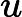
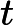

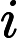
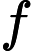
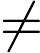
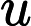

personalrank.py
#coding=utf-8__author__ = 'orisun'import timedef PersonalRank(G, alpha, root, max_step): rank = dict() rank = {x:0 for x in G.keys()} rank[root] = 1 #开始迭代 begin=time.time() for k in range(max_step): tmp = {x:0 for x in G.keys()} #取节点i和它的出边尾节点集合ri for i, ri in G.items(): #取节点i的出边的尾节点j以及边E(i,j)的权重wij, 边的权重都为1,归一化之后就上1/len(ri) for j, wij in ri.items(): #i是j的其中一条入边的首节点,因此需要遍历图找到j的入边的首节点, #这个遍历过程就是此处的2层for循环,一次遍历就是一次游走 tmp[j] += alpha * rank[i] / (1.0 * len(ri)) #我们每次游走都是从root节点出发,因此root节点的权重需要加上(1 - alpha) tmp[root] += (1 - alpha) rank = tmp end=time.time() print 'use time', end - begin li = sorted(rank.items(), cmp=lambda x, y: cmp(x[1], y[1]), reverse=True) for ele in li: print "%s:%.3f, \t"%(ele[0], ele[1]), print return rankif __name__ == '__main__' : alpha = 0.8 G = {'A' : {'a' : 1, 'c' : 1}, 'B' : {'a' : 1, 'b' : 1, 'c':1, 'd':1}, 'C' : {'c' : 1, 'd' : 1}, 'a' : {'A' : 1, 'B' : 1}, 'b' : {'B' : 1}, 'c' : {'A' : 1, 'B' : 1, 'C':1}, 'd' : {'B' : 1, 'C' : 1}} PersonalRank(G, alpha, 'b', 50) #从'b'节点开始游走输出:
use time 0.00107598304749
B:0.312, b:0.262, c:0.115, a:0.089, d:0.089, A:0.066, C:0.066,
注意这里有一个现象,上述代码从节点b开始游走,最终算得的PR重要度最高的不是b,而是B。
personalrank经过多次的迭代游走,使得各节点的重要度趋于稳定,实际上我们根据状态转移矩阵,经过一次矩阵运算就可以直接得到系统的稳态。公式
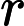

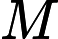
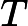

其中



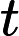
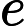
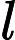
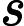

按照矩阵乘法把
由
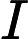


利用
由于我们只关心
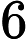
矩阵
pr_matrix.py
# coding=utf-8__author__ = 'orisun'import numpy as npfrom numpy.linalg import solveimport timefrom scipy.sparse.linalg import gmres, lgmresfrom scipy.sparse import csr_matrixif __name__ == '__main__': alpha = 0.8 vertex = ['A', 'B', 'C', 'a', 'b', 'c', 'd'] M = np.matrix([[0, 0, 0, 0.5, 0, 0.5, 0], [0, 0, 0, 0.25, 0.25, 0.25, 0.25], [0, 0, 0, 0, 0, 0.5, 0.5], [0.5, 0.5, 0, 0, 0, 0, 0], [0, 1.0, 0, 0, 0, 0, 0], [0.333, 0.333, 0.333, 0, 0, 0, 0], [0, 0.5, 0.5, 0, 0, 0, 0]]) # print np.eye(n) - alpha * M.T r0 = np.matrix([[0], [0], [0], [0], [1], [0], [0]]) # 从'b'节点开始游走 n = M.shape[0] # 直接解线性方程法 A = np.eye(n) - alpha * M.T b = (1 - alpha) * r0 begin = time.time() r = solve(A, b) end = time.time() print 'use time', end - begin rank = {} for j in xrange(n): rank[vertex[j]] = r[j] li = sorted(rank.items(), cmp=lambda x, y: cmp(x[1], y[1]), reverse=True) for ele in li: print "%s:%.3f, \t" % (ele[0], ele[1]), print # 采用CSR法对稀疏矩阵进行压缩存储,然后解线性方程 A =np.eye(n) - alpha * M.T b = (1 - alpha) * r0 data = list() row_ind = list() col_ind = list() for row in xrange(n): for col in xrange(n): if(A[row, col] != 0): data.append(A[row, col]) row_ind.append(row) col_ind.append(col) AA = csr_matrix((data, (row_ind, col_ind)), shape=(n, n)) begin = time.time() # 系数矩阵很稀疏时采用gmres方法求解。解方程的速度比上面快了许多 r = gmres(AA, b, tol=1e-08, maxiter=1)[0] # r = lgmres(AA, (1 - alpha) * r0, tol=1e-08,maxiter=1)[0] #lgmres用来克服gmres有时候不收敛的问题,会在更少的迭代次数内收敛 end = time.time() print 'use time', end - begin rank = {} for j in xrange(n): rank[vertex[j]] = r[j] li = sorted(rank.items(), cmp=lambda x, y: cmp(x[1], y[1]), reverse=True) for ele in li: print "%s:%.3f, \t" % (ele[0], ele[1]), print # 求逆矩阵法。跟gmres解方程的速度相当 A = np.eye(n) - alpha * M.T b = (1 - alpha) * r0 begin = time.time() r = A.I * b end = time.time() print 'use time', end - begin rank = {} for j in xrange(n): rank[vertex[j]] = r[j, 0] li = sorted(rank.items(), cmp=lambda x, y: cmp(x[1], y[1]), reverse=True) for ele in li: print "%s:%.3f, \t" % (ele[0], ele[1]), print # 实际上可以一次性计算出从任意节点开始游走的PersonalRank结果。从总体上看,这种方法是最快的 A = np.eye(n) - alpha * M.T begin = time.time() D = A.I end = time.time() print 'use time', end - begin for j in xrange(n): print vertex[j] + "\t", score = {} total = 0.0 # 用于归一化 for i in xrange(n): score[vertex[i]] = D[i, j] total += D[i, j] li = sorted(score.items(), cmp=lambda x, y: cmp(x[1], y[1]), reverse=True) for ele in li: print "%s:%.3f, \t" % (ele[0], ele[1] / total), print输出:
use time 7.60555267334e-05
B:0.312, b:0.262, c:0.115, d:0.089, a:0.089, C:0.066, A:0.066,
use time 0.000385999679565
B:0.312, b:0.262, c:0.115, a:0.089, d:0.089, A:0.066, C:0.066,
use time 0.000133991241455
B:0.312, b:0.262, c:0.115, d:0.089, a:0.089, C:0.066, A:0.066,
use time 0.000274181365967
A A:0.314, c:0.189, B:0.166, a:0.159, C:0.076, d:0.063, b:0.033,
B B:0.390, c:0.144, d:0.111, a:0.111, C:0.083, A:0.083, b:0.078,
C C:0.314, c:0.189, B:0.166, d:0.159, A:0.076, a:0.063, b:0.033,
a a:0.308, B:0.222, A:0.159, c:0.133, d:0.070, C:0.063, b:0.044,
b B:0.312, b:0.262, c:0.115, d:0.089, a:0.089, C:0.066, A:0.066,
c c:0.340, B:0.192, C:0.126, A:0.126, d:0.089, a:0.089, b:0.038,
d d:0.308, B:0.222, C:0.159, c:0.133, a:0.070, A:0.063, b:0.044,
- PersonalRank:一种基于图的推荐算法
- 基于图的推荐算法(PersonalRank)
- 机器学习->推荐系统->基于图的推荐算法(PersonalRank)
- 用PersonalRank实现基于图的推荐算法
- 用PersonalRank实现基于图的推荐算法
- 用PersonalRank实现基于图的推荐算法(转载 )
- 用PersonalRank实现基于图的推荐算法
- PersonalRank实现基于图的推荐
- 推荐算法——基于图的推荐算法PersonalRank算法
- 笔记:基于标签的推荐系统、基于图的推荐算法、PersonalRank
- 推荐系统之基于图的推荐:基于随机游走的PersonalRank算法
- 基于随机游走的personalrank算法实现推荐
- 基于随机游走的personalrank算法实现推荐
- 用PersonalRank实现基于图的推荐算法(python实现)
- 推荐系统-基于PersonalRank推荐模型
- Attention+:一种基于关注关系与多用户行为的图推荐算法
- 《推荐系统》基于图的推荐算法
- 推荐算法:基于图的算法
- Python编码错误的解决办法SyntaxError: Non-ASCII character '\xe5' in file
- 源代码寻找分享
- BZOJ3156: 防御准备
- 2017.11.30 刘明春第8天总结
- MyBatis Generator
- PersonalRank:一种基于图的推荐算法
- 从mongoDB数据库中读取tvsplst数据写到CSV文件里面
- Spring Boot 学习笔记5——多数据源及自动切换
- rdp控件开发总结
- 一个字符驱动的签名问题
- 涨姿势 | 如何修复硬盘,以及如何避免硬盘损坏
- newCoder Wannafly挑战赛4:D 树的距离(补)
- 2017信息之美奖作品集 | 今年最好的可视化都在这里了
- centos7 防火墙管理


