Batch Gradient Descent
来源:互联网 发布:阿里云服务器视频教程 编辑:程序博客网 时间:2024/05/17 04:01
Batch Gradient Descent
We use linear regression as example to explain this optimization algorithm.
1. Formula
1.1. Cost Function
We prefer residual sum of squared to evaluate linear regression.
1.2. Visualize Cost Function
E.g. 1 :
one parameter only
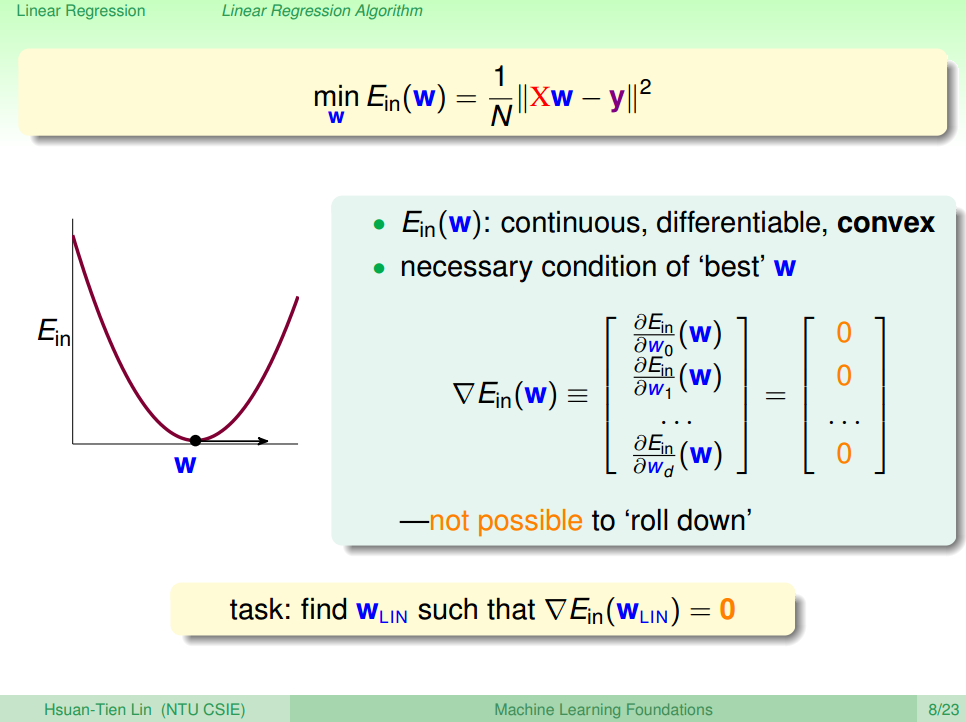
E.g. 2 :
two parameters
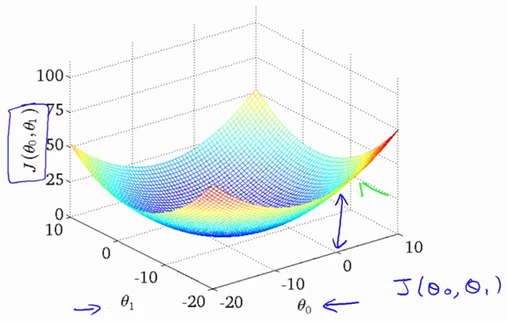
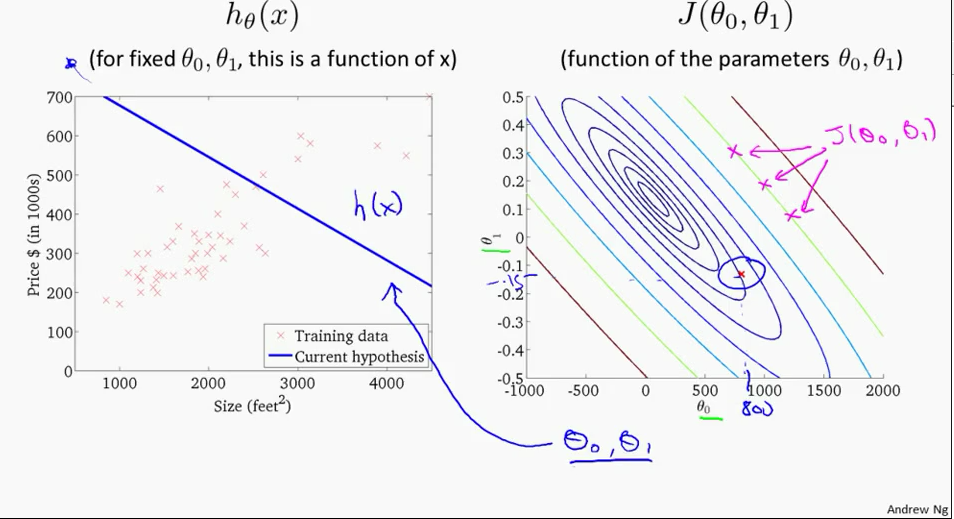
Switch to contour plot
1.3. Gradient Descent Formula
For all
E.g.,
two parametersθ0,θ1 –>hθ(x)=θ0+θ1x1
For i = 0 :
For i = 1:
% Octave%% =================== Gradient Descent ===================% Add a column(x0) of ones to XX = [ones(len, 1), data(:,1)];theta = zeros(2, 1);alpha = 0.01;ITERATION = 1500;jTheta = zeros(ITERATION, 1);for iter = 1:ITERATION % Perform a single gradient descent on the parameter vector % Note: since the theta will be updated, a tempTheta is needed to store the data. tempTheta = theta; theta(1) = theta(1) - (alpha / len) * (sum(X * tempTheta - Y)); % ignore the X(:,1) since the values are all ones. theta(2) = theta(2) - (alpha / len) * (sum((X * tempTheta - Y) .* X(:,2))); %% =================== Compute Cost =================== jTheta(iter) = sum((X * theta - Y) .^ 2) / (2 * len);endfor2. Algorithm
For all
E.g.,
two parametersθ0,θ1 –>hθ(x)=θ0+θ1x1
For i = 0 :
For i = 1 :
Iterative for multiple times (depends on data content, data size and step size). Finally, we could see the result as below.
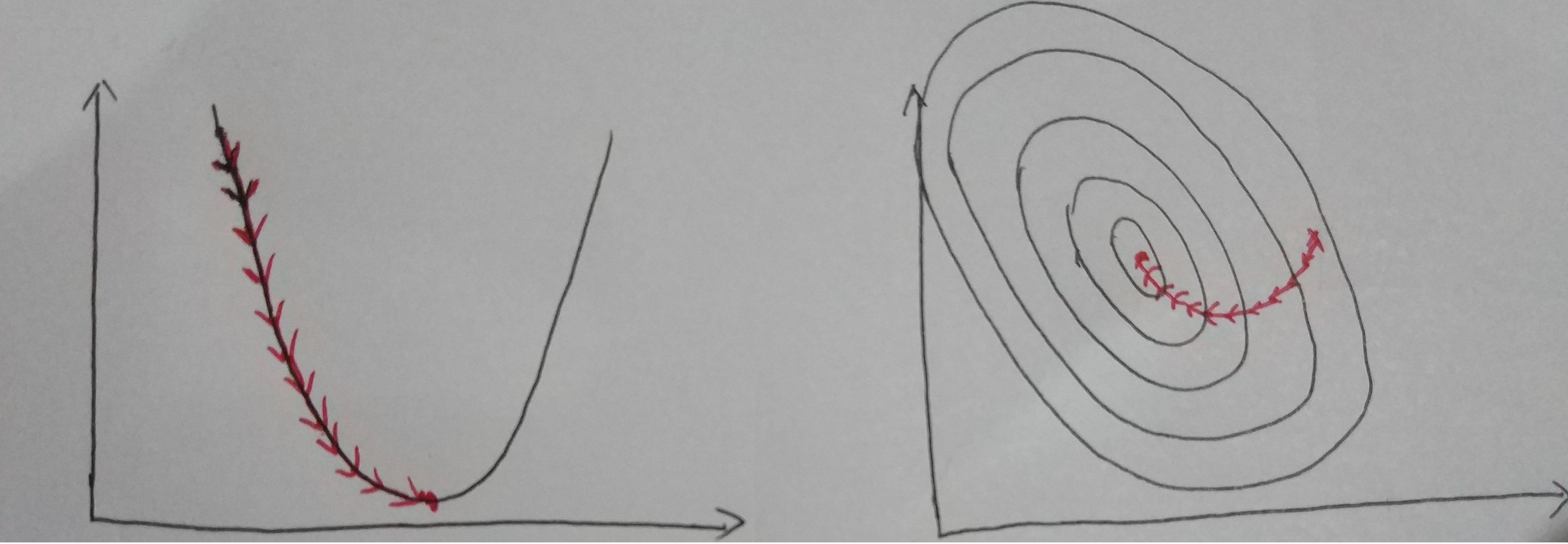
Visualize Convergence
3. Analyze
4. How to Choose Step Size?
Choose an approriate step size is significant. If the step size is too small, it doesn’t hurt the result, but it took even more times to converge. If the step size is too large, it may cause the algorithm diverge (not converge).
The graph below shows that the value is not converge since the step size is too big.
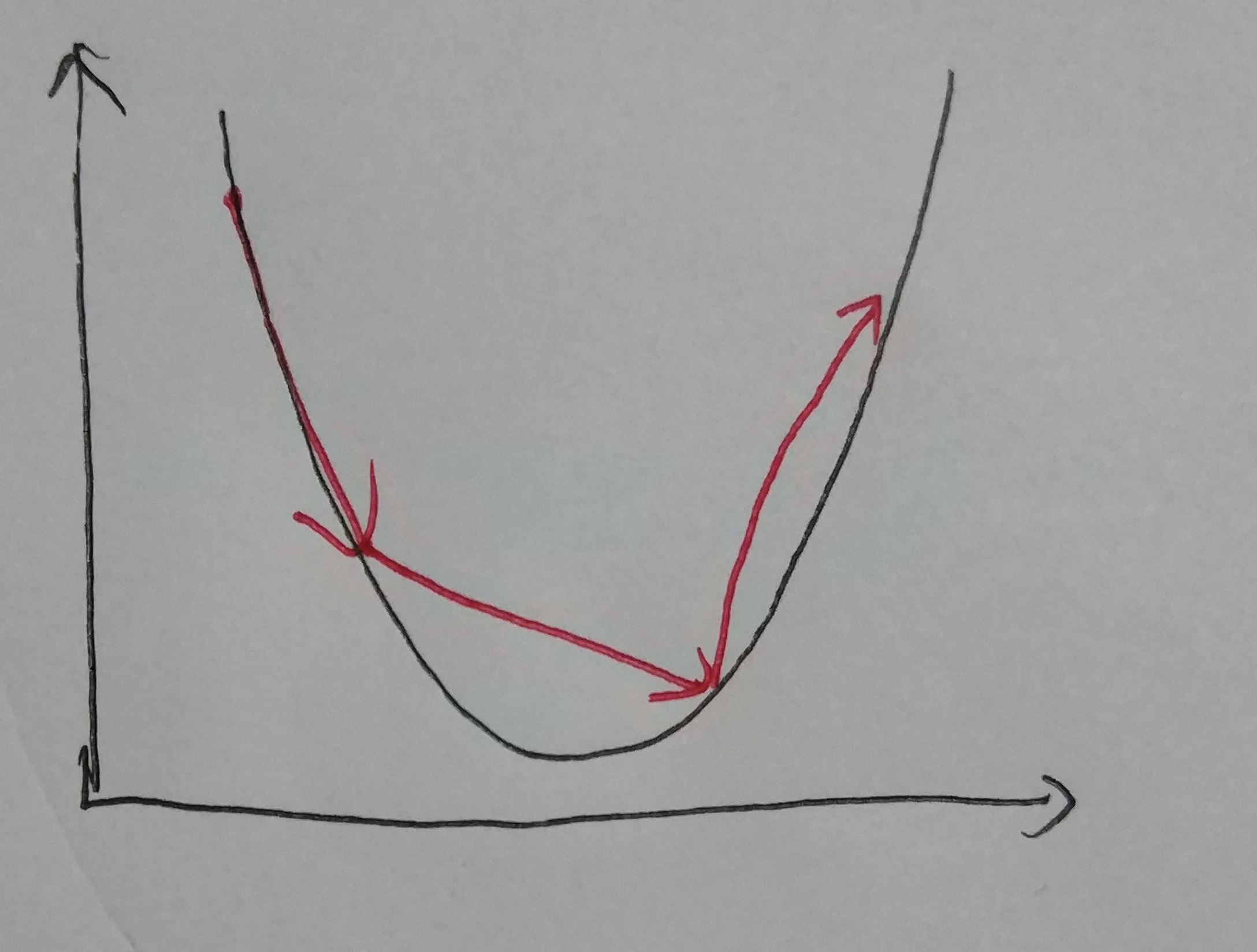
Large Step Size
The best way, as far as I know, is to decrease the step size according to the iteration times.
E.g.,
or
Reference
机器学习基石(台湾大学-林轩田)\lecture_slides-09_handout.pdf
Coursera-Standard Ford CS229: Machine Learning - Andrew Ng
- Batch & Stochatic Gradient Descent
- batch&stochasic gradient descent
- Batch Gradient Descent(python)
- Batch Gradient Descent
- Mini-Batch Gradient Descent
- Batch Gradient Descent and Stochastic Gradient Descent
- Stochastic gradient descent与Batch gradient descent
- BGD(Batch Gradient Descent), SGD (Stochastic Gradient Descent), MBGD (Mini-Batch Gradient Descent)
- Stochastic Gradient Descent vs Batch Gradient Descent vs Mini-batch Gradient Descent
- batch gradient descent和stochastic/incremental gradient descent
- gradient descent vs (mini-batch) stochastic gradient descent
- Mini-Batch Gradient Descent介绍以及如何决定Batch Size
- batch gradient descent(批量梯度下降) 和 stochastic gradient descent(随机梯度下降)
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )
- batch gradient descent(批量梯度下降) 和 stochastic gradient descent(随机梯度下降)
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )
- 【机器学习学习过程中的笔记1——Stochastic gradient descent 和 Batch gradient descent 】
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )
- [kuangbin带你飞]搜索进阶 G
- Java学习笔记-控制执行流程
- linux下opencv无法正确读取avi视频文件
- 利用Tomcat catalina.policy实现禁止文件读写demo(window版)
- IT男装逼利器:如何像黑客一样聊天 Mojo-Webqq
- Batch Gradient Descent
- HOG算法的matlab实现1.0
- uva1595对称轴 STL模拟
- PAT
- 自定义View
- 专利:专利说明书的主要组成部分
- 合并二叉排序树
- Linux C编程 第13章进程间通信方式十个问题及解答(2)
- 数据结构与算法--栈与队列


