rfcn
来源:互联网 发布:java构建redis连接池 编辑:程序博客网 时间:2024/06/10 16:07
R-FCN: Object Detection via Region-based Fully Convolutional Networks
论文下载地址
源码地址
本篇论文是微软亚研何凯明代季峰的团队做的工作,虽然何凯明16年去了facebook,但是相关工作还在进行,代码还是公布在github上。感兴趣的可以从链接下载源码进行分析测试。

Introduce
论文主要提出了一种利用全卷积网络进行目标检测的方法。在目标检测中,会用到深度学习的网络框架。比如ALexNet和VGG一般来说,都是先经过一系列的卷积层,每层卷积以后会有一些pooling层,最后跟着若干全连接层。fast-rcnn,sppnet就是conv层后跟着spp pooling或者RoI pooling,然后再进行全连接层。
但是最近的网络结构,比如GoogleNet, ResNet都是采用了全卷积层,去除了Fc层,因为大量的参数都是在FC层上。直观的想法就是用全卷积网络来做目标检测,但是全卷积网络的分类效果远远大于目标检测的效果。为了解决这个问题,ResNet在更深的网络层中插入RoI-wise subnetwork,由于RoI的参数不共享,所以以损失速度的代价下提高了目标检测的精度。
分析分类和目标检测这两种任务,首先目标检测比分类level更高。更深入分析,可以发现:分类是要增加物体的平移不变性(不同的位置都是同一个物体);目标检测时减少物体的平移变化(目标检测需要画出物体所在的框)。但是平时常用的网络模型比如AlexNet,VGG,Google都是基于ImageNet的分类任务训练得到的,在目标检测的时候进行fine-tuning。由于得到的模型基于分类任务,那么会偏向于平移不变性,这和目标检测就出现了矛盾。所以作者提出了position-positive score maps 来解决这个矛盾。作者假定,更深的convolution layer对图像分类旋转不敏感。在ResNet中作者在深层的convolution layer中插入了RoI pooling layer,这种操作打破了Roi pooling前的平移不变性。但是ResNet这种方法牺牲了训练和测试有效性。表1介绍了ResNet和本文的插入的RoI-wise的位置。

本文为了解决分类的平移不变性,作者构建了position-sensitive score
maps。每一个position-sensitive score map融合位置信息。在position-sensitive score maps上,再添加一个RoI pooling layer融合所有的信息。整个网络可以通过端到端学习,图1显示了R-FCN的过程。作者用101层的Residual Net,R-FCN取得了83.6%的mAP在VOC2007上,2012上取得了82.0。同时时间170ms每张图片,是Faster RCNN的2.5倍以上。

Main approach
基于Region proposal的方法主要包括以下步骤:(i)region proposal (ii)region classification。尽管16年出现了YOLO,SSD这种不基于region proposal的方法,但是基于region proposal的方法精度更好。作者在本文中也是采用了region proposal的想法。RPN网络中,共享了conv 层的参数,本文也采用了这种方式。图2显示了本文中的方法和RPN网络的异同。

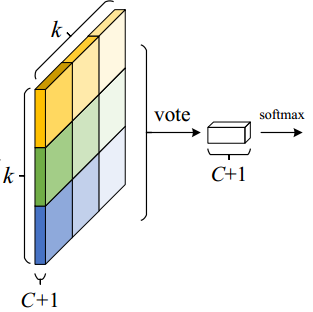
在R-FCN网络中,最后一个conv layer后每类产生了K2大小position-sentitive score maps。所以,feature map的大小为K2(C+1)。C代表的是分类的类别数目,+1代表背景。K2score map 对应着K2的spatial grid 来描述相对位置。例如K = 3,3*3的总共有9个spatial grid分别对应着一个类别物体的9中位置{top-left, top-center,top-right,…, bottom-right}。position-sentitive score maps总共产生K2(C+1)mn的tensor。在position-sentitive score maps 以后跟着一个positive-sensitive的RoI pooling layer。使用3*3的RoI pooling,每一个RoI会生成一个k∗k∗(C+1)的feature map。对k∗k∗(c+1)的feature map 进行 average pooling,会产生(c+1)维的置信度,然后通过softmax既可得到属于哪个类别的可能性。具体参考图1。
作者又添加了边框回归,在k2(c+1)的旁边加入了4K2的conv layer用于预测位置。图1中未画出,综合上述预测每类的置信度,就得到了属于哪类和物体的坐标位置。
图3和图4可视化了网络对人分类的过程。


网络结构
作者才用了ReSNet-101网络,把ResNet-101的Fc层和average pooling层都移除,只用到Conv层。作者用了ResNet在imageNet的训练模型,进行fine-tuning。作者又把最后一个conv层2048维使用1024个1*1随机初始化的conv layer进行降维。然后添加K2(C+1)的conv layer产生score maps。
训练过程
预先得到region proposals,R-FCN很容易进行端到端的训练。网络的损失函数和Fast RCNN一样,采用了多目标的损失函数,同时考虑了分类的损失,和位置的损失。
L(s,tx,y,w,h)=Lcls(sc∗)+λ[c∗>0]Lreg(t,t∗)
上式中,c∗代表ground truth,Lcls代表了分类的交叉熵损失,Lreg表示位置的损失,t∗表示ground truth的位置。[c∗>0]如果分类正确为1,分类错误为0,对分类错误的不进行位置损失。超参数λ=1,表示分类损失和位置损失同等重要。在softmax分类过程中,作者设定与ground truth 的IoU阈值>0.5的设定为正样本,其他的为负样本。我之前SSD的博客中,也介绍了难分样本挖掘的思路,本篇论文也采用了这种方法,按照N proposals的损失排序,按照损失大小选取B个RoI作为负样本,避免分类过程中,正负样本的不均衡。
实验结果
作者分别再Psacal VOC07,12,COCO数据集上进行测试。和以下几种方法进行比较:
- Naive Faster R-CNN:使用ResNet-101计算共享的feature map,在最后一层使用RoI pooling,改为21类的softmax分类,同样采用atrous,个人理解的这里至Fast R-CNN
- Class -specific RPN: 使用Faster-RCNN训练的RPN网络,修改用于分类的卷积层输出为21类。公平起见,在ResNet-101 conv5使用atrous.
- R-FCN without position-sentivity 设定K=1,移除了position-sentivity。
VOC实验结果如下图所示:

COCO实验结果如下所示:

个人总结
目标检测的很多论文都是出自何凯明团队或者RBG大神之手。对这种论文,最大的感觉就是,总是能从网络的baseline中挖掘中值得改进的地方,每一个改进都能够提高目标检测的精度或者速度。这对于我以后的论文研究最值得学习的地方就是,不要放过任何一个不足之处,深挖就能找到入手点。与此同时,也与大家共同借鉴。paper reading出自于菜鸟进阶路上,不足之处,多多指教!
论文笔记 R-FCN: Object Detection via Region-based Fully Convolutional Networks
这篇论文主要采用"位置敏感度图"的方法,将FCN 网络引入到目标检测中来,将图像分类和目标检测很好地结合。因此这种方法可以和很多FCN中的图像分类框架结合,比如ResNets等,使其应用到目标检测中来。本文实验了101层的ResNet在VOC数据下结果,取得了mAP 83.6%和 速度 170ms一张图的结果(速度比Faster RCNN快)。代码开源:https://github.com/daijifeng001/r-fcn 代码支持在Titan,TitanX,K40,K80上跑~~下次有时间可以跑跑玩玩。
想法来源:
一般常见的目标检测主要有两个子网络:(1)一个独立于RoI的共享的全连接层子网络(2)涉及RoI决策的不共享计算的子网络。这样进行网络的分解主要来源于目标检测问题之前,人们大量地对于图像分类的研究。其中的一些经典网络如AlexNet,VGG等,在卷积子网络的结尾直接连接一个pooling层,跟着是一些全连接层(fc)。因此,图像分类网络中的pooling层也就自然而然地出现在了目标检测网络中。
随着ResNets,GoogLeNets等全连接卷积(fully convolutional)的设计网络的出现,自然而然地让作者想到将传统网络改成fully convolutional进行目标检测。为了提高精度并满足检测要求,作者在ResNet的检测流程中加入RoI pooling层到卷积之间,使得其网络可以达到对于区域特定的目标,来完成作者认为的目标检测所需要不同于分类的translation-invariant。
网络结构:
整体来说,本文在FCN网络中使用一个位置敏感的RoI pooling层,得到一个"位置敏感度图"作为输出,完成一个端到端的目标检测网络结构,其主要网络流程如下图:


图中可以清楚看出,整个R-FCN网络依旧是采用RPN+detection两个部分,分别进行候选proposal提取和检测。RPN类似于原始设计,进行前景背景的分离,而在R-FCN的结尾连接着RoI pooling层,该层产生对应于每一个RoI区域的分数。
在R-FCN的后面阶段里,所有卷积权值共享。和fast rcnn相比,主要差别就在后面跟的是ResNet,ResNet101有100个卷积层,一个pooling层一个1000类的fc层,本文为了应用在目标检测,将pooling层和fc层去除,只保留其卷积层得到的feature map,进一步产生分数图进行检测。
位置敏感分数图:
将RoI矩形分成k*k个网格,针对每一个位置为(i,j)处分数的计算,主要不仅针对该处的softmax响应的分数,同时结合了其相对于RoI的位置,其计算公式如下(x0,y0为RoI的top-left角坐标):

为了简化计算,对于一个RoI区域内计算均值作为该RoI的vote,接着算对应的softmax分数。
对于回归和loss函数部分,整体全部和Fast RCNN一致。这里我不再细说。作者给出一个简单的可视化图如下:

实验结果:
主要进行了和Faster RCNN和ResNet-101的对比,我认为和ResNet-101的对比对于目标检测没什么意义,因此主要放图和Faster RCNN的,如下:



Networks
arxiv上的一篇新论文,出自MSRA,目前还没有发表,今天刚读完,文章的缺点还要想一想,有空更新。原文链接:点击打开链接
本文是基于region based framework的一种新的detection方法,主要目的是通过移除最后的fc层进行加速。同时通过本篇论文,很好的将RCNN,fast rcnn进行了一个general的总结。本文目前是Pascal voc上面速度和performance结合的最好的方法,并且用到了最新的residual network(好吧,也过去好久了其实)。唯一美中不足的是,没有其他网络,比如VGG16和GoogleNet的baseline,所以和不少其他的方法没有比较。
本文的motivation非常直接,首先,region base detection framework有一个问题,就是多多少少会有subnet的重复计算。回忆最早的RCNN,每一个proposal都会独立经历一次CNN网络抽取feature,那么这个时候,这个subnet就是整个网络,非常非常慢。后来的fast rcnn,先把整张image进行卷积计算,然后在最后一层通过ROI pooling把每一个proposal变成一个大小一致的map,对于每一个map,经过若干次fc层然后得到结果,在这个时候,这个subnet指的就是那若干层fc层。假如一幅图片的proposal有N个,所以这样经历subnet的计算也会有N次,subnet越深计算的效率越低。本文的想法就是不用这些subnet,让所有的计算都可以共享。(见下图的总结)

这种思路最早在google net上就出现过。googlenet的原始模型最后一层feature map就是一个7*7的map,然后经过一个7*7的avg pooling转化成向量,最后加一层fc作为分类层。全部共享计算的第一种思路就是直接把fc层给替换成计算低廉的pooling(成为naive faster rcnn),然而这样做效果很不好,因为熟悉CNN分类的人都知道,随着网络深度的提高,网络对于location的敏感度越来越低,也就是所谓的translation-invariance,但是在detection的时候,需要对位置信息有很强的的敏感度。所以在最后一层直接这么做效果很不好,尤其是在深层网络(res-101),甚至比VGG还低。
那么res-101的detection是怎么做的?在本文之前,很简单,把ROI-pooling层放到了前面的卷积层,然后后面的卷积层不共享计算,这样一可以避免过多的信息损失,二可以用后来的卷积层学习位置信息。
本文的一个思路就是利用最后一层网络通过FCN构成一个position-sensitive的feature map。具体而言,每一个proposal的位置信息都需要编码,那么先把proposal分成k*k个grid,然后对每一个grid进行编码。在最后一层map之后,再使用卷积计算产生一个k*k*(C+1)的map(k*k代表总共的grid数目,C代表class num,+1代表加入一个背景类)。


产生完了这张map之后,再根据proposal产生一个长宽各为k,channel数目为c+1的score map。具体产生score map的方法是,假如k=3,C=20,那么score map的20个类每个类都有3*3的feature,一共9个格子,每一个格子都记录了空间信息。而这每一个类的每一个格子都对应前面那个channel数为3*3*21的大map的其中一个channel的map。现在把score map中的格子对应的区域的map中的信息取平均,然后这个平均值就是score map格子中的值。最后把score map的值进行vote(avg pooling)来形成一个21维的向量来做分类即可。
对应的bbox regression只需要把C+1设成4就可以了。
本文采用的一些方法比faster rcnn的baseline提高了3个点,并且是原来faster rcnn更快(因为全部计算都共享了)。但是和改进过的faster rcnn相比(roi pooling提前那种)提高了0.2个点,速度快了2.5倍。所以目前为止这个方法的结果应该是所有方法中速度和performance结合的最好的。
我的评价:难以评价。为什么说难以评价,因为本文没有其他网络的结果。目前为止,fast rcnn那一套东西的变种已经非常多了,但是基于residual网络的目前还没有,基本都是基于VGG16的,所以这套东西虽然强过faster rcnn,但是难说就一定强过其他变种的residual版本(如果有),而且,我认为在VGG的版本下这种模式不一定work。不过具体来说,等我实现了做完实验再看,希望比他release代码快吧哈哈。
依旧,欢迎讨论,尤其是我有解释理解错误的地方。
R-FCN: Object Detection via Region-based Fully Convolutional Networks
- Paper
- Code
摘要
- 全卷积网络,全部是卷积层,移除了最后的全连接层(fc).
- 几乎所有的计算都是在整张图像上共享的.
- position-sensitive score maps 位置敏感分数图, 平衡图像分类所需的平移不变性和目标检索所需的平移变化性间的矛盾.
Introduction
目标检测的框架根据ROI pooling 层可以分为两个子网络:
- 共享的,全卷积子网络,独立于ROI;
- 各个ROI子网络,不共享计算
图像分类中,要求网络对于平移不变性越强越好,比如图像中的猫,不管平移到图像的哪个位置,仍是猫;
目标检测则要求网络对平移变化越敏感越好,需要平移变化来定位图像中目标位置.
一般假设在图像分类网络中,网络卷积层越深, 网络的加深,使得其对位置信息的保留越来越少,对平移变化越不敏感. 但目标检测需要对图像中目标的位置信息能较好的感知.
在ResNet-101做目标检测的框架中,是将ROI pooling层插入到前面的卷积层,其后面的卷积层不共享计算,降低了平移不变性,ROI后的卷积层对不同的区域块不再具有平移不变性. 该方法引入了相当数量的逐区域层.
提出R-FCN(Region-based Fully Convolutional Network )框架,解决目标检测任务:
- R-FCN是共享的、全卷积网络结构
- 采用指定的卷积层的输出,来构建 position-sensitive score maps 集合. 各个score map分别编码了对于某个相对空间位置的位置信息,如物体的左边(to the left of an object).
- 在FCN网络层的上面,添加一个位置敏感的ROI pooling 层,来处理来自score maps的信息, 后面不需要权重层(conv/fc).
- End-to-end
- 所有的训练层都是卷积层,在整张图像上共享计算 
R-FCN
two-stage 目标检测策略:
- region proposal 候选区域
- region classification 区域分类 
- 采用RPN(Region Proposal Network)网络提取候选区域,RPN是全卷积网络结构. R-FCN和RPN共享特征.
- 给定候选区域(ROIs),R-FCN网络将ROIs分类到不同的物体类别和背景.
- R-FCN所有学习权重的层都是卷积层,并在整张图像上共享计算
- R-FCN的最后一个卷积层对每一类别产生 k2 position-sensitive score maps,得到 k2(C+1)−channel的输出层(C个物体类别和1个背景类别).
- k2 score maps对应 k×k 空间网格(grid),分别描述了相对位置信息. 例如,k×k=3∗3 时,得到的 9 个score maps分别描述了一个物体类别的 [top-left, top-center, top-right, …, bottom-right] 相对位置信息.
- R-FCN的最后一层是 position-sensitive RoI pooling 层,该层统计了最后一个卷积层的输出,并生成各个 ROI 的 score.
- position-sensitive RoI pooling 层进行选择性 pooling,k×k单元格中的每一个bin都只对 k×k 个score maps中一个score map进行相应. 如Figure 2,选择性pooling图解:看图中的橙色响应图像 (top−left),抠出橙色方块 RoI,池化橙色方块 RoI 得到橙色小方块 (分数);其它颜色的响应图像同理。对所有颜色的小方块投票 (或池化) 得到1类的响应结果。
- . Figure3 和 Figure4 给出了一个示例.

基础网络结构
- 基于 ResNet-101,其具有100个卷积层和一个1000分类的全连接(fc)层.
- 移除ResNet-101的 average pooling层和 fc层,只使用卷积层来计算feature maps.
- 采用在ImageNet训练的ResNet-101模型进行权重初始化.
- ResNet-101的最后一个卷积层输出是 2048-d 的,采用一个权重随机初始化的 1×1 的卷积层来进行降维到 1024-d.
- 采用k2(C+1)−channel卷积层生成score maps.
Position-sensitive score maps & Position-sensitive RoI pooling.
- 为了更好的对每个ROI中的位置信息进行编码,这里将各个ROI框(rectangle) 根据规则网络分为 k×k 个单元格. 即,对一个ROI框,其尺寸为 w∗h,一个单元格的尺寸为 ≈wk×hk.
- R-FCN的最后一个卷积层用来产生每一个类别的 k2 个score maps.
- 在第 (i,j) 个单元格中,(0≤i,j≤k−1),定义一个 position-sensitive RoI pooling 操作,仅对第 (i,j) 个score map 进行 pool 处理:
γc(i,j∣Θ)=∑(x,y)∈bin(i,j)zi,j,c(x+x0,y+y0∣Θ)/n
其中,- rc(i,j) 是在第 (i,j)个单元格中 c−类的池化响应;
- zi,j,c 是k2(C+1) 个score maps中的一个 score map;
- (x0,y0) 表示一个ROI的左上角位置( top-left corner);
- n 是单元格中的像素数量;
- Θ 表示网络所有的学习参数.
- 第 (i,j) 个单元格占用的范围是 [iwk]≤x<[(i+1)wk] 和 [jhk]≤x<[(j+1)hk].
- 上述公式中的操作在 Figure 1 中进行了例示,其中一种颜色代表一对 (i,j).
- 上述公式进行了平均 pooling,但也进行了 max pooling.
在ROI上进行 k2 个 position-sensitive scores 投票.
- 这里通过平均scores来进行简单投票,得到各个ROI的 (C+1) 维向量:
γc(Θ)=∑i,jγc(i,j∣Θ)). - 计算各类别的 softmax 响应:
sc(Θ)=eγc(Θ)/∑Cc′=0eγc′(Θ).
被用来计算训练过程中的 cross-entropy loss,在推断时用来对ROIs进行排名.
对于bounding box regression,只需要把 C+1 改为4即可.
- 除了 k2(C+1)-d 的卷积层之外,又添加了一个 4k2-d 的卷积层,用于边界框回归.
- 在 4k2 个maps上,进行 position-sensitive RoI pooling 操作,得到各个 ROI 的4k2-d 向量;
- 通过 average voting,得到 4-d 向量,参数化边界框 t=(tx,ty,tw,th).
训练
- Loss on each ROI
- cross-entropy loss:Lcls(sc∗)=−log(sc∗) —— 分类
- box regression loss:Lreg —— 边界框回归
L(s,tx,y,w,h)=Lcls(sc∗)+λ[c∗>0]Lreg(t,t∗)
其中,
c∗ 是ROI的 ground-truth label,c∗=0 表示背景.
如果参数为true, [c∗>0]=1;否则 [c∗>0]=0.
t∗ 是ground truth box.
λ=1.
- 如果与 ground-truth box 的 IoU 大于 0.5的ROIs,设为positive examples; 小于0.5,设为negative examples.
- 单尺度训练(single-scale training),将图像裁剪为最短边为 600 pixels的尺寸
- 单个GPU训练一张图片,共8GPUs,选取 B=128 个 ROIs作为备选.
- fine-tune R-FCN,weight_decay = 0.0005, momentum=0.9,20K次 mini-batches的 lr=0.001, 10K次mini-batches的 lr=0.0001.
推断
如Figure 2 所示.
- 输入图像是单尺度的,尺寸为 600×600
- RPN和R-FCN的 feature map是计算是共享的
- RPN 提取 ROIs,R-FCN 估计各个类的 scores,以及回归边界框.
- 最后进行 NMS(non-maximum suppression) 后处理,IoU 阈值为 0.3.
À trous and stride
- R-FCN 继承了FCN的网络的特点
- R-FCN 将 ResNet-101 的有效步长由 32 pixels 减少到 16 pixels,以增加 score map 的分辨率
- 在 conv4 stage之前的网络层保持不变(stride=16)
- 第一个 conv5 网络块的步长由 stride=2 修改为 stride=1,所有 conv5 stage的卷积 filters 根据 "hole algorithm" 进行修改,以补偿减少的步长.
可视化
如 Figure 3 和Figure 4,图示了当 k×k=3×3时,由 R-FCN 学习得到 position-sensitive score maps.
- 这些得到的 maps 应该对于物体的相对位置具有较强的响应. 例如,"top-center-sensitive" 对于物体的 top-center 附近的位置应该具有high socre.
- 如果候选 box 能够与真实物体重叠较精确,如Figure 3, 则ROI的 k2 个单元格中的大部分被激活,且得到的投票分数较高.
- 如果候选 box 与真实物体不能正确重叠,如Figure 4,则ROI 的 k2 个单元格中的一些是不被激活的,且投票分数较低.
Result

R-FCN论文阅读(R-FCN: Object Detection via Region-based Fully Convolutional Networks )

目录
- 作者及相关链接
- 方法概括
- 方法细节
- 实验结果
- 总结
- 参考文献

作者及相关链接
- 作者:
- 作者链接:代季峰,何恺明,孙剑
- 论文链接:论文传送门
- 代码链接:matlab版,python版
方法概括
R-FCN解决问题——目标检测
整个R-FCN的结构
- 一个base的conv网络如ResNet101, 一个RPN(Faster RCNN来的),一个position sensitive的prediction层,最后的ROI pooling+投票的决策层
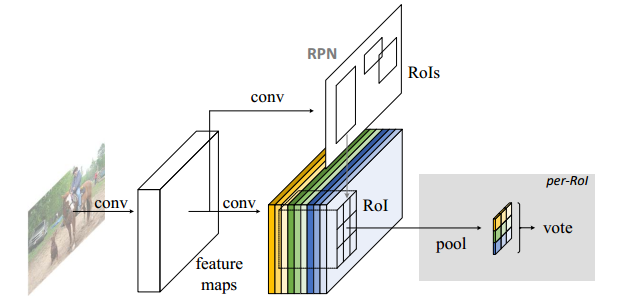
R-FCN的idea出发点(关键思想)
- 分类需要特征具有平移不变性,检测则要求对目标的平移做出准确响应。现在的大部分CNN在分类上可以做的很好,但用在检测上效果不佳。SPP,Faster R-CNN类的方法在ROI pooling前都是卷积,是具备平移不变性的,但一旦插入ROI pooling之后,后面的网络结构就不再具备平移不变性了。因此,本文想提出来的position sensitive score map这个概念是能把目标的位置信息融合进ROI pooling。


- 对于region-based的检测方法,以Faster R-CNN为例,实际上是分成了几个subnetwork,第一个用来在整张图上做比较耗时的conv,这些操作与region无关,是计算共享的。第二个subnetwork是用来产生候选的boundingbox(如RPN),第三个subnetwork用来分类或进一步对box进行regression(如Fast RCNN),这个subnetwork和region是有关系的,必须每个region单独跑网络,衔接在这个subnetwork和前两个subnetwork中间的就是ROI pooling。我们希望的是,耗时的卷积都尽量移到前面共享的subnetwork上。因此,和Faster RCNN中用的ResNet(前91层共享,插入ROI pooling,后10层不共享)策略不同,本文把所有的101层都放在了前面共享的subnetwork。最后用来prediction的卷积只有1层,大大减少了计算量。

方法细节
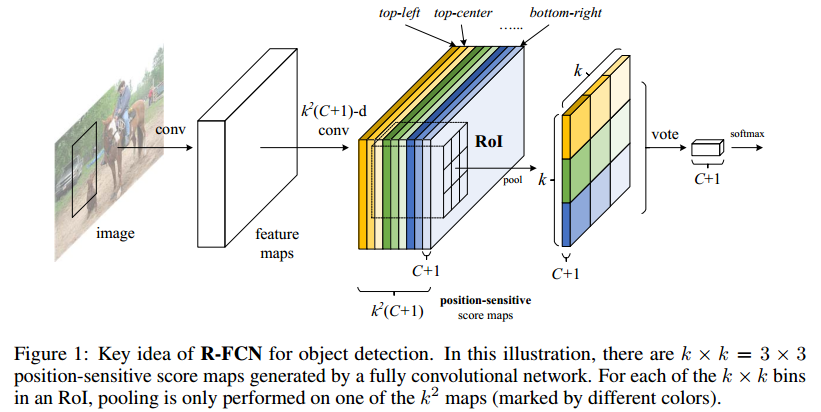
- Backbone architecture: ResNet 101——去掉原始ResNet101的最后一层全连接层,保留前100层,再接一个1*1*1024的全卷积层(100层输出是2048,为了降维,再引入了一个1*1的卷积层)。
- k^2(C+1)的conv:ResNet101的输出是W*H*1024,用K^2(C+1)个1024*1*1的卷积核去卷积即可得到K^2(C+1)个大小为W*H的position sensitive的score map。这步的卷积操作就是在做prediction。k = 3,表示把一个ROI划分成3*3,对应的9个位置分别是:上左(左上角),上中,上右,中左,中中,中右,下左,下中,下右(右下角),如图Figuire 3。


- k^2(C+1)个feature map的物理意义: 共有k*k = 9个颜色,每个颜色的立体块(W*H*(C+1))表示的是不同位置存在目标的概率值(第一块黄色表示的是左上角位置,最后一块淡蓝色表示的是右下角位置)。共有k^2*(C+1)个feature map。每个feature map,z(i,j,c)是第i+k(j-1)个立体块上的第c个map(1<= i,j <=3)。(i,j)决定了9种位置的某一种位置,假设为左上角位置(i=j=1),c决定了哪一类,假设为person类。在z(i,j,c)这个feature map上的某一个像素的位置是(x,y),像素值是value,则value表示的是原图对应的(x,y)这个位置上可能是人(c='person')且是人的左上部位(i=j=1)的概率值。
- ROI pooling: 就是faster RCNN中的ROI pooling,也就是一层的SPP结构。主要用来将不同大小的ROI对应的feature map映射成同样维度的特征,思路是不论对多大的ROI,规定在上面画一个n*n 个bin的网格,每个网格里的所有像素值做一个pooling(平均),这样不论图像多大,pooling后的ROI特征维度都是n*n。注意一点ROI pooling是每个feature map单独做,不是多个channel一起的。
- ROI pooling的输入和输出:ROI pooling操作的输入(对于C+1个类)是k^2*(C+1)*W' *H'(W'和H'是ROI的宽度和高度)的score map上某ROI对应的那个立体块,且该立体块组成一个新的k^2*(C+1)*W' *H'的立体块:每个颜色的立体块(C+1)都只抠出对应位置的一个bin,把这k*k个bin组成新的立体块,大小为(C+1)*W'*H'。例如,下图中的第一块黄色只取左上角的bin,最后一块淡蓝色只取右下角的bin。所有的bin重新组合后就变成了类似右图的那个薄的立体块(图中的这个是池化后的输出,即每个面上的每个bin上已经是一个像素。池化前这个bin对应的是一个区域,是多个像素)。ROI pooling的输出为为一个(C+1)*k*k的立体块,如下图中的右图。更详细的有关ROI pooling的操作如公式(1)所示:
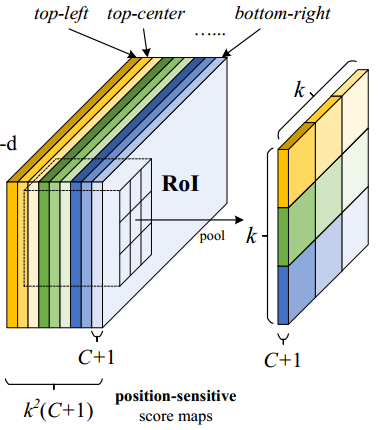

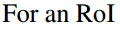

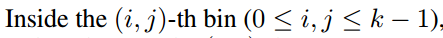
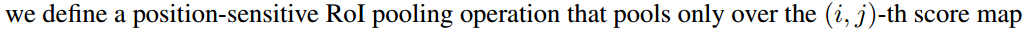
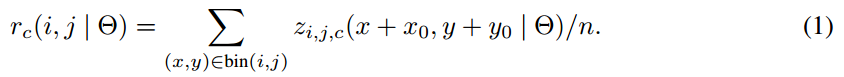
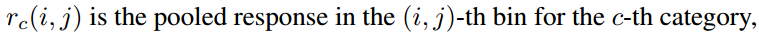

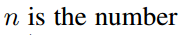
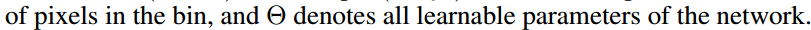
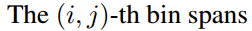
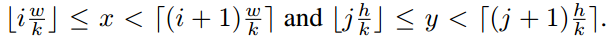
- vote投票:k*k个bin直接进行求和(每个类单独做)得到每一类的score,并进行softmax得到每类的最终得分,并用于计算损失
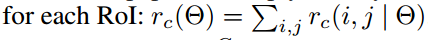

- 损失函数:和faster RCNN类似,由分类loss和回归loss组成,分类用交叉熵损失(log loss),回归用L1-smooth损失

- 训练的样本选择策略:online hard example mining (OHEM,参考文献1) 。主要思想就是对样本按loss进行排序,选择前面loss较小的,这个策略主要用来对负样本进行筛选,使得正负样本更加平衡。
- 训练细节:
- decay = 0.0005
- momentum = 0.9
- single-scale training: images are resized such that the scale (shorter side of image) is 600 pixels [6, 18].
- 8 GPUs (so the effective mini-batch size is 8×), each GPU holds 1 image and selects B = 128 RoIs for backprop.
- fine-tune learning rate = 0.001 for 20k mini-batches, 0.0001 for 10k mini-batches on VOC.
- the 4-step alternating training between training RPN and training R-FCN.(类似于Faster RCNN)
- 使用atrous(hole算法)

实验结果
VOC2007和VOC2010上与Faster R-CNN的对比:R-FCN比Faster RCNN好!



深度影响对比:101深度最好!

候选区域选择算法对比:RPN比SS,EB好!

COCO库上与Faster R-CNN的对比:R-FCN比Faster RCNN好!

效果示例:

总结
R-FCN是在Faster R-CNN的框架上进行改造,第一,把base的VGG16换车了ResNet,第二,把Fast R-CNN换成了先用卷积做prediction,再进行ROI pooling。由于ROI pooling会丢失位置信息,故在pooling前加入位置信息,即指定不同score map是负责检测目标的不同位置。pooling后把不同位置得到的score map进行组合就能复现原来的位置信息。
- rfcn
- RFCN论文笔记
- RFCN论文笔记
- RFCN-阅读笔记-理解
- RFCN目标检测算法思想
- 目标检测:RFCN文章收集
- Faster R-CNN改进篇(二): RFCN ● RON
- 编译测试MATLAB版本的faster rcnn和rfcn
- Tensorflow object detection API 源码阅读笔记:RFCN
- 目标检测方法总结(RFCN/SSD/RCNN/FastRCNN/FasterRCNN/SPPNet/DPM/OverFeat/YOLO)
- Windows+Caffe(Faster RCNN/RFCN/SSD)编译(Cuda7.5+Cuda8.0)未完待续
- 目标检测方法总结(RFCN/SSD/RCNN/FastRCNN/FasterRCNN/SPPNet/DPM/OverFeat/YOLO)
- 目标检测方法总结(RFCN/SSD/RCNN/FastRCNN/FasterRCNN/SPPNet/DPM/OverFeat/YOLO)
- py-rfcn算法caffe配置,训练及应用到自己的数据集
- Windows+Caffe(Faster RCNN/RFCN/SSD)编译(Cuda7.5+Cuda8.0)未完待续
- windows 下 编译py-faster-rcnn,py-rfcn, py-pva-frcn 下的lib。编译Cython模块
- Detection物体检测及分类方法总结(RFCN/SSD/RCNN/FastRCNN/FasterRCNN/SPPNet/DPM/OverFeat/YOLO)
- Detection物体检测及分类方法总结(RFCN/SSD/RCNN/FastRCNN/FasterRCNN/SPPNet/DPM/OverFeat/YOLO)
- JavaWeb——mybatis模糊查询与主键返回
- 【1701H1】【穆晨】【171201】连续第五十二天总结
- JVM基础结构
- ansible-playbook设置java环境变量后不生效解决方法
- 单例模式
- rfcn
- 011_LeetCode_11 Container With Most Water 题解
- Python----伪私有属性和私有方法
- 自己总结unity的一些面试题
- java.lang.ClassNotFoundException: org.springframework.web.servlet.DispatcherServlet
- luogu 1088 火星人(模拟)
- 目标检测-RCNN系列
- cmd 命令,收集一下
- linux CentOS7 下 Nginx1.13.7 开始、停止和重新加载配置


