李宏毅机器学习2016 第一讲 回归案例分析
来源:互联网 发布:最美的古诗词知乎 编辑:程序博客网 时间:2024/06/16 17:24
本人于2017年12月5日开始学习机器学习课程,个人对机器学习及深度学习已有一定的了解。学习此次课程的目的是为了加深对机器学习的认识,以期达到进阶以及加深理解的作用,此外也希望通过完成课程作业,能够提升自己的实战项目能力。
视频链接:李宏毅机器学习(2016)_演讲•公开课_科技_bilibili_哔哩哔哩
课程资源:Hung-yi Lee
课程相关PPT已经打包命名好了:链接:https://pan.baidu.com/s/1qXIvgb6 密码:4y97
Regression
本章节主要讲解了回归、梯度下降、如何选择模型、过拟合、正则化,并通过实际案例Pokemon的讲解加深对回归的理解。
1.线性函数
线性函数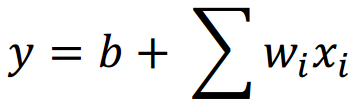 线性函数
线性函数如何选择一个模型能够正确预测出结果呢?本章节主要使用回归的方法。线性函数是形如上式的集合。
2.损失函数
损失函数用来评价一个函数的好坏,通过计算预测出的值与实际值之间的差值进行评价。
3.梯度下降
梯度下降的主要目的是使损失函数最小,寻找到全局最优值。梯度指的是偏导数,也可理解成斜率。当其值为负时就增加w,为正时就减小w,因此
梯度下降第一步,对于函数y=w*x+b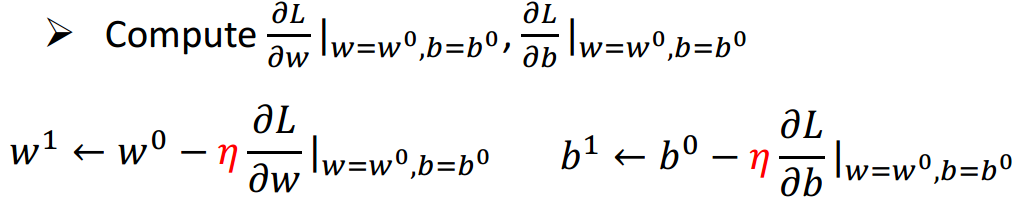 梯度下降第一步,对于函数y=w*x+b
梯度下降第一步,对于函数y=w*x+b在梯度下降问题中,其结果和初始值的选择大小高度相关。会陷入局部最小值。
但在线性回归中,损失函数是凸函数,是没有局部最小值的。
4.测试数据
模型在新数据上的表现是评价好坏的最重要的指标。
5.过拟合
通过不断的增强模型的复杂度(添加二次项、三次项......)会不断减小损失函数的值,但在测试数据上的表现会因为过拟合的出现导致结果误差反而更大。一个复杂的模型并不总是会在测试数据上表现得更好。
6.重新设计模型
考虑多种因素,构造出更强的模型。选择多种特征。
7.正则化。
加入正则项可以避免过拟合的出现。
正则化为什么正则化?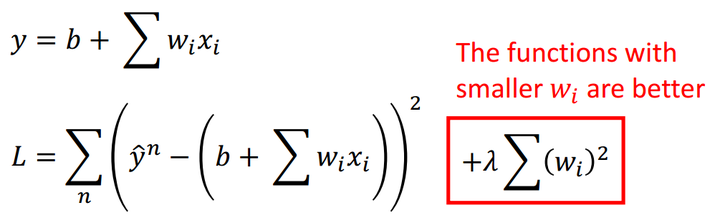 正则化
正则化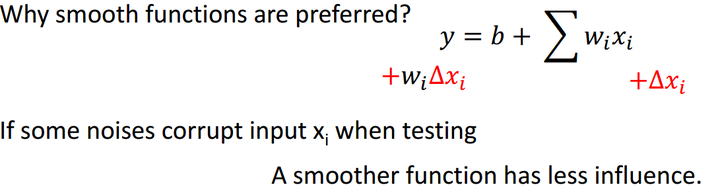 为什么正则化?
为什么正则化?平滑函数能够在噪声数据出现时,受到更少的影响。不至于过度拟合那些离群点数据。
加入正则项恰恰可以使得函数更平滑。正则项参数λ的值是一个超参数,也是个调参值。
此处,还有一个小问题是正则项的设计要不要考虑偏置b?答案是不需要,因为b和函数的平滑程度无关,只是对函数上下平移了。
8.如果最终在测试数据上得到平均误差值为11.1,那么在另外的新的数据上的表现会怎样?
Overestimate误差会高于11.1。
总结:
1.Pokemon实例生动有趣。
2.梯度下降主要原理及注意事项。
3.过拟合和正则化。
- 李宏毅机器学习2016 第一讲 回归案例分析
- 机器学习 第一讲:线性回归
- 机器学习脑图:回归案例分析
- [机器学习]回归分析案例 --- 网游排名分析
- 机器学习第一讲
- 机器学习 第一讲
- 机器学习 - 第一讲
- 第一讲 什么是机器学习
- Standford 机器学习—第一讲 Linear Regression with one variable(单变量线性回归)
- 机器学习第二讲 线性回归
- 机器学习第六讲-逻辑回归
- 机器学习--Logistic回归算法案例
- 机器学习七 回归分析
- [机器学习入门] 李宏毅机器学习笔记-2 (Regression:Case Study ;回归:案例研究)
- 台大机器学习第一讲
- 机器学习基石第一讲:PLA
- 《机器学习基石》笔记:第一讲
- 机器学习-第一讲机器学习的动机与应用
- 1271技术流
- hypot
- codeforces.com/contest/897/
- 关于PE装载节区时候Virtual Size和Size Of Raw Data的关系猜想
- 不使用(a+b)/2这种方式,求两个数的平均值。
- 李宏毅机器学习2016 第一讲 回归案例分析
- ConcurrentHashMap实现原理及源码分析
- Python调用windows下DLL详解
- C++之实现MyString类
- android5.0之后用getConstantState()方法判断ImageView使用的是哪张图片
- viewpager+fragment页面切换,fragment用recylerview的坑
- bfs广度优先搜索经典模板题目
- CentOS 7
- HardFault_Handler问题查找方法


