ActiveMQ的高可用性
来源:互联网 发布:诺基亚920软件下载 编辑:程序博客网 时间:2024/04/30 00:23
原文地址:http://www.cnblogs.com/hapjin/p/5663024.html
一,ActiveMQ高可用性的架构
ActiveMQ的高可用性架构是基于Master/Slave 模型的。ActiveMQ总共提供了四种配置方案来配置HA,其中Shared Nothing Master/Slave 在5.8版本之后不再使用了,并在ActiveMQ5.9版本中引入了基于Zookeeper的Replicated LevelDB Store HA方案。
二,Master/Slave架构的配置解释
①Shared Nothing Master/Slave 该架构最大的特点是:
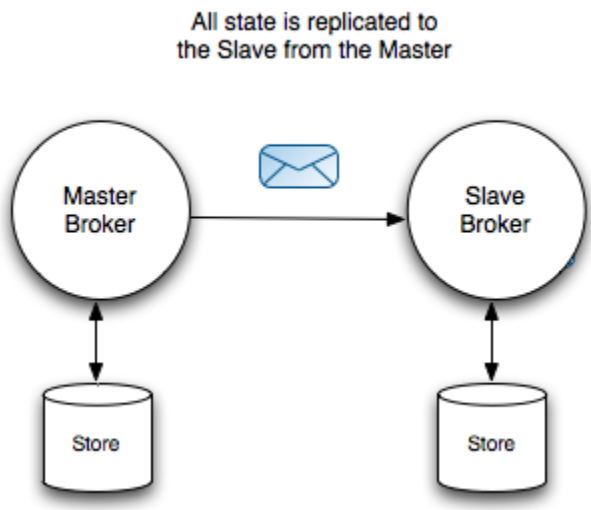
1)Master 和 Slave各自都单独存储持久化的消息,它们不共享数据。
2)Master收到持久化消息时,需要先同步(sync)给Slave之后,才向Producer发送ACK确认。
3)只有Master负责Client的请求,Slave不接收Client请求。Slave连接到Master,负责备份消息。
4)Master出现故障,Slave有两种处理方式:❶自己成为Master;❷关闭(停服务)—根据具体配置而定。
5)Master 与 Slave之间可能会出现“Split Brain”现象。比如:Master本身是正常的,但是Master与Slave之间的网络出现故障,网络故障导致Slave认为Master已经宕机,因为它自己会成为Master(根据配置:shutdownOnMasterFailure)。此时,对Client而言,就会存在两个Master。
6)Slave 只能同步它连接到Master之后的消息。在Slave连接到Master之前Producer向Master发送的消息将不会同步给Slave,这可以通过配置(waitForSlave)参数,只有当Slave也启动之后,Master才开始初始化TransportConnector接受Client的请求(Producer的请求)
7)如果Master 或者 Slave其中之一宕机,它们之间不同步的消息 无法 自动进行同步,此时只能手动恢复不同步的消息了。也就是说:“ActiveMQ没有提供任何有效的手段,能够让master与slave在故障恢复期间,自动进行数据同步”
8)对于非持久化消息,并不会同步给Slave。因此,Master宕机,非持久化消息会丢失。
关于ShareNothing 高可用配置的一点理解:
❶由上面的第2)步可知:Producer向Master发消息之后,Master需要将消息同步给Slave之后,才向Producer返回确认ACK。因此,对Producer的响应有一定的延时。
如果为了保证快速响应,即Producer给Master发消息之后,Master收到了消息立即给Producer回复,然后再在后台把消息同步给Slave。这又会造成数据不一致性问题。
因为,如果Master收到了消息立即给Producer回复之后,Master还未来得及向Slave同步就宕机了,如果此条消息还在Master内存中,则Master宕机后消息就丢失了。如果Master收到Producer的消息,先写入磁盘,然后再向Producer返回确认ACK,然后再在后台与Slave同步,那么Master就需要标记每条消息是否已经成功同步到了Slave,若消息还未同步到Slave,则Master重启恢复后,需要立即同步Slave。只有当Slave成功同步了所有的Master上的消息之后,才能上线。这也无法实现 automatic failover。
关于一个很好的高可靠性解决方案:可参考 Hadoop HA中的QJM机制。其核心就是:1)采用集群,能容忍不超过大多数机器的失效;2)数据只写大多数机器就返回确认,保证Client快速的响应能力;3)数据在后台在异步同步到集群所有的机器,从而保证高可用。
❷这里的Master–Slave机制中,只有一台Slave,并不是Slave集群(见上面结构图)。Master宕机,或者Slave宕机后,都会给整个服务造成极大的风险,并没有像Hadoop HA中的那样能够容忍“不超过大多数机器失效”的保证,即没有做到真正的高可用性。
❸还可能出现“双主”问题。即上面提到的“Split Brian”现象。
②Shared Database Master/Slave
这是很常用的一种架构。“共享存储”,意味着Master与Slave之间的数据是共享的。
那如何避免冲突呢?通过争夺数据库表的排他锁,只有Master有锁,未获得锁的自动成为Slave。
ActiveMQ Message Broker uses a relational database, it grabs an exclusive lock on a table ensuring that no other ActiveMQ broker can access the database at the same time 
对于“共享存储”而言,只会“共享”持久化消息。对于非持久化消息,它们是在内存中保存的。可以通过配置(forcePersistencyModeBrokerPlugin persistenceFlag)属性强制所有的消息都持久化。
当Master宕机后,Slave可自动接管服务成为Master。由于数据是共享的,因此Master和Slave之间不需要进行数据的复制与同步。Slave之间通过竞争锁来决定谁是Master。
③Shared File system Master/Slave
这种方式和共享数据库存储原理基本一样,(文件系统也有文件锁),故不详细介绍。
④最近的 Replicated LevelDB Store
The elected master broker node starts and accepts client connections. The other nodes go into slave mode and connect the the master and synchronize their persistent state /w it.以上也表明:每个Broker都是单独存储数据的。因为Master要把新的数据复制到Slave上。从这个角度看:称这种方式为“Share Storage”有点不合适。
2)Quorum机制的又一应用
假设有3个Broker,那么选举时至少需要两个Broker同意(大多数)之后,才能选出Master。此外,只需要当新消息复制到大多数Broker上时,就可以给Producer返回ACK。其他少数Broker则可以在后台以异步方式复制新的消息。
All messaging operations which require a sync to disk will wait for the update to be replicated to a quorum of the nodes before completing. So if you configure the store with replicas="3" then the quorum size is (3/2+1)=2. The master will store the update locally and wait for 1 other slave to store the update before reporting success.比如说:一共有3个Broker,一个Master,二个Slave。当新消息到达Master时,Master需要将消息同步到其中一台Slave之后,才能向Producer发送ACK确认此次消息成功发送。
而剩下的另一台Slave,则可以在后台以异步方式复制这个新消息。此外,还能容忍一台Slave宕机。(能容忍不超过大多数的Broker宕机)
这种设计要求,可以保证集群中消息的可靠性,只有当(replicas/2 + 1)个节点物理故障,才会有丢失消息的风险。另外,也提高了一定的响应性,因为它不需要将消息同步到所有的Slave上,而只需要同步到大多数Broker上。
三,参考资料
分布式系统理论之Quorum机制
https://activemq.apache.org/artemis/docs/1.0.0/ha.html
Replicated LevelDB Store HA官方文档
ActiveMQ与HA架构(master/slave)
- ActiveMQ的高可用性
- ActiveMQ配置高可用性的方式
- EF的高可用性
- activemq消息队列高可用性和负载均衡
- OpenStack的高可用性构建
- RabbitMQ的高可用性方案
- HBase 的 HA (高可用性)
- 浅谈系统的高可用性
- Namenode的高可用性总结
- mapreduce的高可用性配置
- marathon-lb的高可用性
- hdfs的高可用性HA
- 高可用性
- 高可用性
- hadoop2的HDFS的高可用性
- 建立高可用性的数据库群集
- 设计可用性很高的.NET应用程序
- 遇到系统的高可用性问题
- 如果你养了一只可爱的机器宠物狗 你还会对它好吗?| 讨论
- 你今天剁手了吗?专家称是网购刺激了机器人的复兴! | 观点
- 算法时代!这里有一张机器人独立完成的金属音乐专辑 | 聚焦
- pigcms左侧导航栏个别标签点击后出现标签点击不上及样式错误
- 织梦dedecms后台编辑器鼠标放在多图发布按钮上显示乱码的解决方法
- ActiveMQ的高可用性
- caffe源码与linux命令学习笔记
- 7-136 打印菱形图案
- word 单个单元格内边距设置
- redis在linux的安装和配置启用/关闭
- TreeMap源码分析解读
- Spring Cloud Config
- 织梦dedecms列表页分页显示为竖排的解决方
- 遗传算法:go语言实现


