利用条件GANs的pix2pix进化版:高分辨率图像合成和语义操作 | PaperDaily #23
来源:互联网 发布:淘宝店铺关闭激活不了 编辑:程序博客网 时间:2024/06/13 18:12
本文从三个方面对 pix2pix 方法做了改进,还将他们的方法扩展到交互式语义操作,这对于传统的图像逼真渲染是一个颠覆性的工作。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:郑琪,华中科技大学硕士生,研究方向为计算机视觉和自然语言处理。
■ 论文 | High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
■ 链接 | https://www.paperweekly.site/papers/1278
■ 作者 | Aidon
论文导读
现有的用于图像逼真渲染的图形学技术,在构建和编辑虚拟环境时往往非常复杂并且耗时,因为刻画真实的世界要考虑的方面太多。
如果我们可以从数据中学习出一个模型,将图形渲染的问题变成模型学习和推理的问题,那么当我们需要创造新的虚拟环境时,只需要在新的数据上训练我们的模型即可。
之前的一些利用语义标签合成图像的工作存在两个主要问题:1. 难以用 GANs 生成高分辨率图像(比如 pix2pix 方法);2. 相比于真实图像,生成的图像往往缺少一些细节和逼真的纹理。
本文从三个方面对 pix2pix 方法做了改进:一个 coarse-to-fine 生成器,一个 multi-scale 判别器和一个鲁棒的 loss,从而成功合成出 2048 x 1024 的逼真图像。此外,本文还将他们的方法扩展到交互式语义操作,这对于传统的图像逼真渲染是一个颠覆性的工作。
我有几张阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
模型介绍
1. The pix2pix Baseline
给定语义标签图和对应的真实照片集 (si,xi),该模型中的生成器用于从语义标签图生成出真实图像,而判别器用于区分真实图像和生成的图像,该条件GANs对应的优化问题如下:
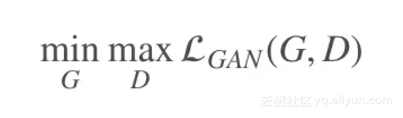
其中:
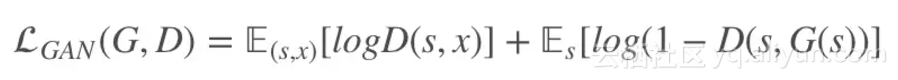
pix2pix 采用 U-Net 作为生成器,在 Cityscapes 数据集上生成的图像分辨率最高只有 256 x 256。
2. Coarse-to-fine 生成器
这里一个基本的想法是将生成器拆分成两个子网络 G={G1,G2}:全局生成器网络 G1 和局部增强网络 G2,前者输入和输出的分辨率保持一致(如 1024 x 512),后者输出尺寸(2048 x 1024)是输入尺寸(1024 x 512)的 4 倍(长宽各两倍)。
以此类推,如果想要得到更高分辨率的图像,只需要增加更多的局部增强网络即可(如 G={G1,G2,G3}),具体的网络结构如图所示:
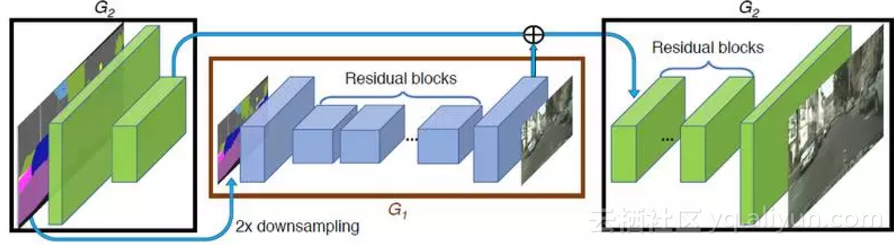
其中 G1 由卷积前端,一系列残差块
和一个转置卷积后端
组成,G2 也由卷积前端
,一系列残差块
和一个转置卷积(有时也叫反卷积)后端
组成。从图中可以看到,
的输入是由
的输出和
最后一层的 feature map 相加得到,这样就使得全局信息可以传递到G2。
原文链接
- 利用条件GANs的pix2pix进化版:高分辨率图像合成和语义操作 | PaperDaily #23
- 利用条件GANs的pix2pix进化版:高分辨率图像合成和语义操作 | PaperDaily #23
- pix2pix tensorflow试验(GAN之图像转图像的操作)
- pix2pix tensorflow试验(GAN之图像转图像的操作)
- pix2pix tensorflow试验(GAN之图像转图像的操作)
- Pix2Pix-基于GAN的图像翻译
- 实现图像的编辑和合成
- 实现图像的编辑和合成
- 减少OpenCV读取高分辨率图像的时间
- H.264句法和语法总结(八)参考图像序列标记 (marking)操作的语义
- H.264句法和语法总结(八)参考图像序列标记 (marking)操作的语义
- H.264句法和语法总结(八)参考图像序列标记 (marking)操作的语义
- H.264句法和语法总结(八)参考图像序列标记 (marking)操作的语义
- H.264句法和语法总结(八)参考图像序列标记 (marking)操作的语义
- 图像语义分割,全卷积网络FCN和条件随机场CRF、马尔可夫随机场MRF
- 如何解决高分辨率下文本、图像和字体和布局?
- DeepLab:深度卷积网络,多孔卷积 和全连接条件随机场 的图像语义分割 Semantic Image Segmentation with Deep Convolutional Nets, Atro
- Android多媒体学习四:实现图像的编辑和合成
- centos启动JGroups raft时无法加载leveldbjni64
- XVII Open Cup named after E.V. Pankratiev. Eastern Grand Prix. Problem G. Gmoogle 模拟、字符串处理、文本搜索
- 点餐系统——数据库设计
- Mac 删除/卸载 自己安装的 Python
- 在thinkphp5的构造方法中无法返回json问题
- 利用条件GANs的pix2pix进化版:高分辨率图像合成和语义操作 | PaperDaily #23
- ubuntu 14.04 忘记用户登录密码
- WPF中textbox强制失去焦点
- java虚拟机参数
- 利用C语言版本的数据库制作一个学生成绩管理系统
- SwitchButton(原ToggleButton)
- CSS深入理解之padding
- Android ListView滑动后背景变黑
- Spring Boot中使用使用Spring Security和JWT


