机器学习-线性回归
来源:互联网 发布:软件手术刀 教程 编辑:程序博客网 时间:2024/05/03 18:36
背景
机器学习所研究的主要内容,是关于在计算机上从数据中产生模型的算法,即学习算法。有了学习算法,我们把经验数据提供给它,它就能基于这些数据产生模型,在面对新的情况时,模型会给我们提供相应的判断。在本篇文章及其接下来的文章中不对算法做数学上的推断,如果想知道机器学习的数学推导过程,建议学习NG的机器学习算法公开课,参考笔记可以更好地理解。本篇的顺序是按照周志华的机器学习章节展开,对机器学习的各种算法有个大致介绍。
线性模型
线性模型试图学的一个通过属性的线性组合来进行预测的函数,形式简单,易于建模,并且具有很好的解释。收集的数据中,每一个分量,就可以看做一个特征数据。每个特征至少对应一个未知的参数。这样就形成了一个线性模型函数。
我们用X1,X2..Xn 去描述每一个特征数据,估计函数如下所示: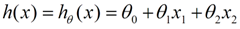
θ在这儿称为参数,在这的意思是调整每个特征的影响力。为了如果我们令X0 = 1,就可以用向量的方式来表示了: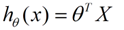
这种函数基本上都是解不存在的超定方程组。因此,需要退一步,将参数求解问题,转化为求最小误差问题,求出一个最接近的解,这就是一个松弛求解。当矩阵满秩时使用最小二乘法,否则使用梯度下降,两种方法是回归任务中最常用的损失函数。
逻辑回归:sigmoid函数,又称逻辑回归函数。逻辑回归,都是以线性回归为理论支持的。只不过,线性模型,无法做到sigmoid的非线性形式,sigmoid可以轻松处理0/1分类问题。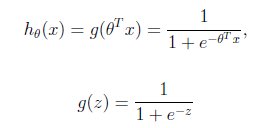
拟合:在训练过程中会出现以下三种情况:欠拟合,合适的拟合和过拟合。
欠拟合
合适的拟合
过拟合:
针对出现的过拟合现象,一般采取以下方法
1) 减少特征的数量,有人工选择,或者采用模型选择算法
2) 正则化,即保留所有特征,但降低参数的值的影响。正则化的优点是,特征很多时,每个特征都会有一个合适的影响因子。在损失函数里增加一个每个特征的惩罚因子。这个就是正则化。如正则化的线性回归 的 损失函数:
正则化是模型处理的典型方法。也是结构风险最小的策略。在经验风险(误差平方和)的基础上,增加一个惩罚项/正则化项。
类别不平衡:如果训练样本的类别数目差别很大会对学习过程造成过多困扰。比如100个样例,98个反例,2个正例。那么学习方法只需要返回讲所有新样本预测为反例的学习器就能达到98%的准确率。
再缩放:当训练集中正反例的数目不同时令m+表示正例数目,m-表示反例数目。于是,只要分类器的预测几率高于观测几率就应该判定为正例,即:
y / 1-y > m+ / m-。思想虽然简单,但是实际操作并不平凡,因为训练集是真实样本总体的无偏采样这个假设旺旺并不成立。现在大体上有三类做法:
1)、直接对训练集合里的反例进行欠采样,即减少一些反例,使得正反例数目接近,再进行学习。
2)、直接对训练集合里的正例进行过采样,即增加一些正例,使得正反例数目接近,再进行学习。
3)、再一个就是基于原始训练集合进行学习,但在用训练好的分类器进行预测时,使用公式y * m+ / (1-y) * m-进行阈值移动。
总结
线性回归作为机器学习最简单的方法,有广大的用处。以上内容对多篇文章有所参考,总结下来还是感觉心虚不已,俗话说实践得真知,所以计划每周总结一个算法并且用python实际跑一下实例,敬请期待。
- 机器学习-线性回归
- 【机器学习】线性回归
- 机器学习-线性回归
- 机器学习 线性回归
- 机器学习-线性回归
- 机器学习--线性回归
- 机器学习---线性回归
- 机器学习----线性回归
- 机器学习--线性回归
- 机器学习--线性回归
- 机器学习-线性回归
- 机器学习---线性回归
- 机器学习-线性回归
- 【机器学习】线性回归
- 机器学习--线性回归
- 机器学习--线性回归
- 【机器学习】线性回归
- 机器学习--线性回归
- FZU 1076 穿越沙漠
- nyist 737
- AR--基本原理实现科普
- Python安装的包的更新
- 基于大数据的房价分析--1.数据爬取
- 机器学习-线性回归
- 数据洞察打通全域社群
- c++ 单例模式写法
- SIFT特征提取分析
- 第6节项目1-求两个电阻的值(变量)
- 存储系统科普——文件系统介绍
- GUI界面
- 字符串的处理
- 使用 Spring 3 来创建 RESTful Web Services


