数据库_索引总结
来源:互联网 发布:恋夜秀场破解软件酷安 编辑:程序博客网 时间:2024/05/02 16:47
一. 四种索引(主键索引/普通索引/全文索引/唯一索引)
1.索引的添加
1.1主键索引的添加
当一张表,把某个列设为主键的时候,则该列就是主键索引
如果当创建表时没有指定主键索引,也可以在创建表之后添加:
alter table table_name add primary key (column name);
1.2普通索引
普通索引一般是在建表后再添加的,
create index 索引名 on table_name(column1,column2);alter table table_name add index 索引名(column1,column2);
1.3全文索引
首先,全文索引主要针对文本文件,比如文章,标题,全文索引只有MyISAM有效(mysql5.6之后InnoDB也支持了全文索引)
使用全文索引常见的错误:
select * from c where content like "%mysql%";
这里并不会使用全文索引,可以用explain进行查看。正确用法:select * from c where match(title,content) against ('MYSQL');
备注:
1. 在mysql中fulltext 索引只针对 myisam生效
2. mysql自己提供的fulltext针对英文生效->sphinx(coreseek)技术处理中文
3. 使用方法是 match(字段名..) against(‘关键字’)
1.4唯一索引
d表中name就是唯一索引,唯一索引可以有多个null,不能是重复的内容相比主键索引,主键字段不能为null,也不能重复
2. 查询索引
show indexes from table_name;
show keys from table_name;
3.删除索引
alter table table_name drop index 索引名;
二. 索引的机制
2.1 为什么我们添加完索引后查询速度为变快?
传统的查询方法,是按照表的顺序遍历的,不论查询几条数据,mysql需要将表的数据从头到尾遍历一遍
在我们添加完索引之后,mysql一般通过BTREE算法生成一个索引文件,在查询数据库时,找到索引文件进行遍历(折半查找大幅查询效率),找到相应的键从而获取数据
2.2 索引的代价
1. 创建索引是为产生索引文件的,占用磁盘空间
2. 索引文件是一个二叉树类型的文件,可想而知我们的dml操作同样也会对索引文件进行修改,所以性能会下降
2.3 在哪些column上使用索引?
1 .较频繁的作为查询条件字段应该创建索引
2. 唯一性太差的字段不适合创建索引,尽管频繁作为查询条件,例如gender性别字段
3. 更新非常频繁的字段不适合作为索引
4.不会出现在where子句中的字段不该创建索引
总结: 满足以下条件的字段,才应该创建索引.
a: 肯定在where条经常使用 b: 该字段的内容不是唯一的几个值 c: 字段内容不是频繁变化三.索引使用注意事项
1.对于创建的多列索引,只要查询条件使用了最左边的列,索引一般就会被使用。
比如我们对title,content 添加了复合索引
select * from table_name where title = 'test';会用到索引
select * from table_name where content = 'test';不会用到索引
2.对于使用like的查询,查询如果是 ‘%a’不会使用到索引 ,而 like 'a%'就会用到索引。最前面不能使用%和_这样的变化值
3.如果条件中有or,即使其中有条件带索引也不会使用。
4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。
四.如何查看索引使用的情况:
show status like‘Handler_read%’;
注意:
handler_read_key:这个值越高越好,越高表示使用索引查询到的次数。
handler_read_rnd_next:这个值越高,说明查询低效。
转自:http://blog.csdn.net/u013927110/article/details/46636765
为什么要给表加上主键?
为什么加索引后会使查询变快?
为什么加索引后会使写入、修改、删除变慢?
什么情况下要同时在两个字段上建索引?
想要理解索引原理必须清楚一种数据结构「平衡树」(非二叉),也就是b tree或者 b+ tree,重要的事情说三遍:“平衡树,平衡树,平衡树”。当然, 有的数据库也使用哈希桶作用索引的数据结构 , 然而, 主流的RDBMS都是把平衡树当做数据表默认的索引数据结构的。
我们平时建表的时候都会为表加上主键, 在某些关系数据库中, 如果建表时不指定主键,数据库会拒绝建表的语句执行。 事实上, 一个加了主键的表,并不能被称之为「表」。一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我认知中的「表」很接近。如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引。没错, 再说一遍, 整个表变成了一个索引,也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。

上图就是带有主键的表(聚集索引)的结构图。图画的不是很好, 将就着看。其中树的所有结点(底部除外)的数据都是由主键字段中的数据构成,也就是通常我们指定主键的id字段。最下面部分是真正表中的数据。 假如我们执行一个SQL语句:
select * from table where id = 1256;
首先根据索引定位到1256这个值所在的叶结点,然后再通过叶结点取到id等于1256的数据行。 这里不讲解平衡树的运行细节, 但是从上图能看出,树一共有三层, 从根节点至叶节点只需要经过三次查找就能得到结果。如下图
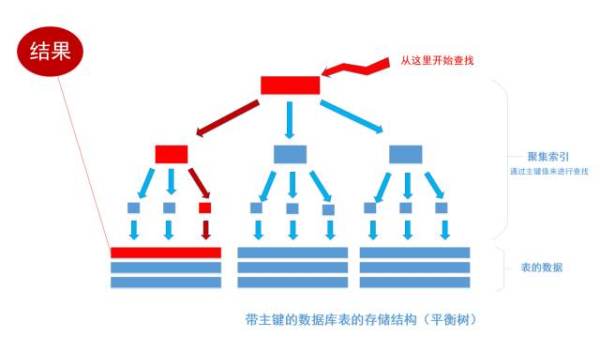
假如一张表有一亿条数据 ,需要查找其中某一条数据,按照常规逻辑, 一条一条的去匹配的话, 最坏的情况下需要匹配一亿次才能得到结果,用大O标记法就是O(n)最坏时间复杂度,这是无法接受的,而且这一亿条数据显然不能一次性读入内存供程序使用, 因此, 这一亿次匹配在不经缓存优化的情况下就是一亿次IO开销,以现在磁盘的IO能力和CPU的运算能力, 有可能需要几个月才能得出结果 。如果把这张表转换成平衡树结构(一棵非常茂盛和节点非常多的树),假设这棵树有10层,那么只需要10次IO开销就能查找到所需要的数据, 速度以指数级别提升,用大O标记法就是O(log n),n是记录总树,底数是树的分叉数,结果就是树的层次数。换言之,查找次数是以树的分叉数为底,记录总数的对数,用公式来表示就是

用程序来表示就是Math.Log(100000000,10),100000000是记录数,10是树的分叉数(真实环境下分叉数远不止10), 结果就是查找次数,这里的结果从亿降到了个位数。因此,利用索引会使数据库查询有惊人的性能提升。
然而, 事物都是有两面的, 索引能让数据库查询数据的速度上升, 而使写入数据的速度下降,原因很简单的, 因为平衡树这个结构必须一直维持在一个正确的状态, 增删改数据都会改变平衡树各节点中的索引数据内容,破坏树结构, 因此,在每次数据改变时, DBMS必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
讲完聚集索引 , 接下来聊一下非聚集索引, 也就是我们平时经常提起和使用的常规索引。
非聚集索引和聚集索引一样, 同样是采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,在数据改变时, DBMS需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。 如下图

每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据,如下图

不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径。
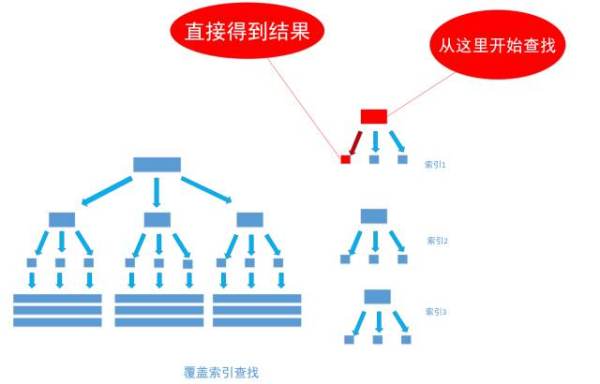
然而, 有一种例外可以不使用聚集索引就能查询出所需要的数据, 这种非主流的方法 称之为「覆盖索引」查询, 也就是平时所说的复合索引或者多字段索引查询。 文章上面的内容已经指出, 当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
先看下面这个SQL语句
//建立索引
create index index_birthday on user_info(birthday);
//查询生日在1991年11月1日出生用户的用户名
select user_name from user_info where birthday = '1991-11-1'
这句SQL语句的执行过程如下
首先,通过非聚集索引index_birthday查找birthday等于1991-11-1的所有记录的主键ID值
然后,通过得到的主键ID值执行聚集索引查找,找到主键ID值对就的真实数据(数据行)存储的位置
最后, 从得到的真实数据中取得user_name字段的值返回, 也就是取得最终的结果
我们把birthday字段上的索引改成双字段的覆盖索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
这句SQL语句的执行过程就会变为
通过非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的叶节点的内容,然而, 叶节点中除了有user_name表主键ID的值以外, user_name字段的值也在里面, 因此不需要通过主键ID值的查找数据行的真实所在, 直接取得叶节点中user_name的值返回即可。 通过这种覆盖索引直接查找的方式, 可以省略不使用覆盖索引查找的后面两个步骤, 大大的提高了查询性能,如下图
转自:http://www.cnblogs.com/aspwebchh/p/6652855.html
B树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:

B树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;
否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入
右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果B树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树
的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变B树结构
(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:

但B树在经过多次插入与删除后,有可能导致不同的结构:

右边也是一个B树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的
树结构索引;所以,使用B树还要考虑尽可能让B树保持左图的结构,和避免右图的结构,也就
是所谓的“平衡”问题;
实际使用的B树都是在原B树的基础上加上平衡算法,即“平衡二叉树”;如何保持B树
结点分布均匀的平衡算法是平衡二叉树的关键;平衡算法是一种在B树中插入和删除结点的
策略;
B-树
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的
子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)

B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果
命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为
空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少
利用率,其最底搜索性能为:

其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占
M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树
(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)

B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在
非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好
是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储
(关键字)数据的数据层;
4.更适合文件索引系统;
B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;

B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3
(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据
复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父
结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分
数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字
(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之
间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
小结
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于
走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键
字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点
中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率
从1/2提高到2/3;
转自:https://www.cnblogs.com/oldhorse/archive/2009/11/16/1604009.html
- 数据库_索引总结
- 数据库_索引1
- 数据库_索引2
- 数据库_索引3
- 数据库_索引4
- 【数据库复习_索引】
- Mysql数据库_索引.sql
- 数据库索引总结
- MySQL数据库索引总结
- 数据库索引总结
- 数据库索引总结
- 数据库索引学习总结
- 数据库系列:索引总结
- NoSQL 数据库索引 总结
- 数据库知识_索引的利弊
- 数据库面试_三大索引
- 数据库_视图、序列、索引、约束
- 数据库索引工作原理总结
- POJ 1562Oil Deposits深搜
- 连接mysql报错Property ‘driverClassName’ threw exception :could not load jdbc driver
- 用循环制作乘法口诀表
- 【POJ 1442 && 洛谷 P1801】黑匣子(替罪羊树做法)
- 7-6 红色警报(25 分)(并查集)
- 数据库_索引总结
- Redis初识
- JAVA核心技术卷2 第四章Socket
- 冒泡排序、快速排序
- LeetCode-028 Implement strStr()
- [NTT][斯特林数]BZOJ 5093: 图的价值
- 哈尔滨理工大学第七届程序设计竞赛决赛(网络赛-高年级组)A 所有情况的和
- debain9的亮度调整失败
- 鼠标事件的使用


