word2vec
来源:互联网 发布:编程一小时网站登录 编辑:程序博客网 时间:2024/06/07 02:07
例子
word2vec就是对word做了一个embedding操作,简单来说就是将原有用one-hot编码的预料库(一般来说百万级别)转为embedding形式(几百维)。
比如:维基百科预料库包含的词有100W,将其使用one-hot编码。
“The dog barked at the mailman”
基于这个句子,可以构建一个大小为5的词汇表(忽略大小写和标点符号):(“the”, “dog”, “barked”, “at”, “mailman”)
对这个词汇表的单词进行编号0-4。那么”dog“就可以被表示为一个5维向量[0, 1, 0, 0, 0]
那么经过embedding后,得到的dog可能就是[0.1,0.2,0.3] 这样就降维了。
基本原理
使用浅层神经网络。将one-hot编码的语料作为输入,按照CBOW或者skip-gram语言模型训练得到中间隐藏层。那么对于一个单词,它的隐藏层输出就是该词的embedding向量。
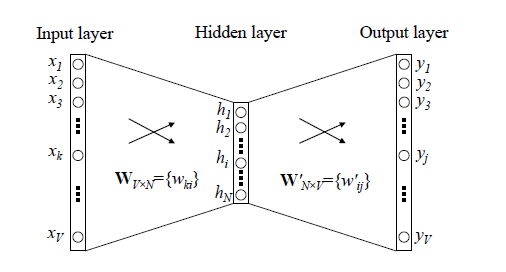
CBOW和skip-gram模型是两种语言模型。
CBOW是输入一个词的附近词,输出该词。”The dog barked at the mailman”,若设置窗口为2,则对于单词barked来说The dog at the都是他的输入,barked是输出。
skip-gram是输入该词,预测附近的词汇。和CBOW刚好相反。还是以上面句子为例,”The dog barked at the mailman”,若设置窗口为2,则对于单词barked来说barked是输入,The dog at the都是他的输出。
n:词上下文长度
m:词向量长度
h:隐藏层神经单元数
N:词典规模
CBOW:输入层为n-1个单词的词向量,长度为m(n-1),隐藏层的规模为h,输出层的规模为N
Skip-Gram里,我们的输入是特定词, 输出是softmax概率排前8的8个词,对应的Skip-Gram神经网络模型输入层有1个神经元,输出层有词汇表大小个神经元。
以CBOW为例,输入层到隐藏层就是各单词线性相加。隐藏层到输出层做了一次softmax。计算所属单词的概率。

具体做法
百万维度的反向传播,想想都很感人。word2vec使用霍夫曼树来构建输出层。
霍夫曼树是计算最短编码的一种算法,这里以词频为计量,不断将词频低的词取出合并建树。 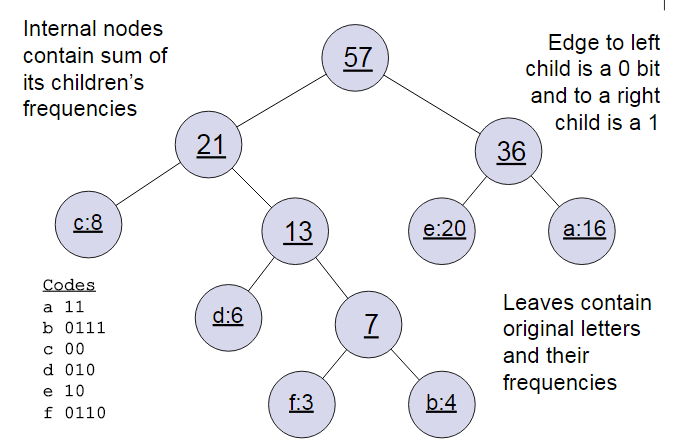
得到预料库的霍夫曼树后,相当于我们知道了每个词从根至叶的路径。
从隐藏层出来以后到霍夫曼树,霍夫曼的输入就是隐藏层输出的那个定义的维度(你想embedding后的维度)
其中每个中间节点都有一个
这里写链接内容
- word2vec
- word2vec
- word2vec
- Word2Vec
- word2vec
- Word2Vec
- Word2Vec
- word2vec
- word2vec
- word2vec
- word2vec
- word2vec
- word2vec
- word2vec
- word2vec
- Word2Vec
- word2vec
- Word2Vec
- nanopi 烧写系统+连接wifi+stfp
- 5. 编码器与PID控制
- IntelliJ IDEA For Mac 快捷键
- Java画面精美的简易聊天室
- Wireless Network poj 2236
- word2vec
- java快速排序
- 6. PIBOT的通讯协议
- MySQL基础(二)数据库、表的创建及操作
- 搭建调试符号服务器
- JavaScript基础总结
- 一道简单而经典的二分,借用一点挑战上的方法
- php 数据库连接代码
- Six Degrees of Cowvin Bacon poj 2139


