sqoop 学习笔记
来源:互联网 发布:数据库的基本语句 编辑:程序博客网 时间:2024/05/16 12:15
大数据本质也是数据,但是又有了新的特征,包括数据来源广、数据格式多样化(结构化数据、非结构化数据、Excel文件、文本文件等)、数据量大(最少也是TB级别的、甚至可能是PB级别)、数据增长速度快等。
针对以上主要的4个特征我们需要考虑以下问题:
- 数据来源广,该如何采集汇总?,对应出现了Sqoop,Cammel,Datax等工具。
这里介绍下sqoop 工具。
通常一个组织中有价值的数据都要存储在关系型数据库系统中。但是为了进一步进行处理,有些数据需要抽取出来,通过MapReduce程序进行再次加工。为了能够和HDFS系统之外的数据库系统机型交互,MapReduce程序需要使用外部API来访问数据。Sqoop就是一个开源的工具,它允许用户将数据从关系型数据库抽取到HDFS中;也可以把HDFS的数据导回到数据库中。
Sqoop 是什么
Sqoop是Hadoop和关系数据库服务器之间传送数据的一种工具。它是用来从关系数据库如:MySQL,Oracle到Hadoop的HDFS,并从Hadoop的文件系统导出数据到关系数据库。
传统的应用管理系统,也就是与关系型数据库的使用RDBMS应用程序的交互,是产生大数据的来源之一。这样大的数据,由关系数据库生成的,存储在关系数据库结构关系数据库服务器。当大数据存储器和分析器,如MapReduce, Hive, HBase, Cassandra, Pig等,Hadoop的生态系统等应运而生,它们需要一个工具来用的导入和导出的大数据驻留在其中的关系型数据库服务器进行交互。在这里,Sqoop占据着Hadoop生态系统提供关系数据库服务器和Hadoop HDFS之间的可行的互动。
Sqoop是Hadoop和关系数据库服务器之间传送数据的一种工具。它是用来从关系数据库如MySQL,Oracle到Hadoop的HDFS从Hadoop文件系统导出数据到关系数据库。
Sqoop是怎么样工作的?
下图描述了Sqoop的工作流程。 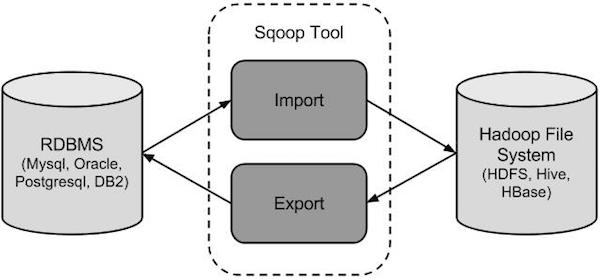
Sqoop导入
导入工具从RDBMS到HDFS导入单个表。表中的每一行被视为HDFS的记录。所有记录被存储在文本文件的文本数据或者在Avro和序列文件的二进制数据。
Sqoop导出
导出工具从HDFS导出一组文件到一个RDBMS。作为输入到Sqoop文件包含记录,这被称为在表中的行。那些被读取并解析成一组记录和分隔使用用户指定的分隔符。
深入了解数据库导入
在深入理解之前,我们需要先想一个问题:Sqoop是通过一个MapReduce作业从数据库中导入一个表,这个作业从表中抽取一行行记录,然后写入到HDFS。MapReduce是如何记录的?下图是Sqoop从数据库中导入到HDFS的原理图:

在导入开始之前,Sqoop使用JDBC来检查将要导入的表。他检索出表中所有的列以及列的SQL数据类型。这些SQL类型(VARCHAR、INTEGER)被映射到Java数据类型(String、Integer等),在MapReduce应用中将使用这些对应的java类型来保存字段的值。Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。例如前面提到过的example类。
对于导入来说,更关键的是DBWritable接口的序列化方法,这些方法能使Widget类和JDBC进行交互:
Public void readFields(resultSet _dbResults)throws SQLException;Public void write(PreparedStatement _dbstmt)throws SQLException;JDBC的ResultSet接口提供了一个用户从检查结果中检索记录的游标;这里的readFields()方法将用ResultSet中一行数据的列来填充Example对象的字段。
Sqoop启动的MapReduce作业用到一个InputFormat,他可以通过JDBC从一个数据库表中读取部分内容。Hadoop提供的DataDriverDBInputFormat能够为几个Map任务对查询结果进行划分。为了获取更好的导入性能,查询会根据一个“划分列”来进行划分的。Sqoop会选择一个合适的列作为划分列(通常是表的主键)。在生成反序列化代码和配置InputFormat之后,Sqoop将作业发送到MapReduce集群。Map任务将执行查询并将ResultSet中的数据反序列化到生成类的实例,这些数据要么直接保存在SequenceFile文件中,要么在写到HDFS之前被转换成分割的文本。
Sqoop不需要每次都导入整张表,用户也可以在查询中加入到where子句,以此来限定需要导入的记录:Sqoop –query 。
导入和一致性:在向HDFS导入数据时,重要的是要确保访问的是数据源的一致性快照。从一个数据库中并行读取数据的MAP任务分别运行在不同的进程中。因此,他们不能共享一个数据库任务。保证一致性的最好方法就是在导入时不允许运行任何进行对表中现有数据进行更新。
深入了解导出
Sqoop导出功能的架构与其导入功能非常相似,在执行导出操作之前,sqoop会根据数据库连接字符串来选择一个导出方法。一般为jdbc。然后,sqoop会根据目标表的定义生成一个java类。这个生成的类能够从文本文件中解析记录,并能够向表中插入类型合适的值。接着会启动一个MapReduce作业,从HDFS中读取源数据文件,使用生成的类解析记录,并且执行选定的导出方法。

基于jdbc的导出方法会产生一批insert语句,每条语句都会向目标表中插入多条记录。多个单独的线程被用于从HDFS读取数据并与数据库进行通信,以确保涉及不同系统的I/O操作能够尽可能重叠执行。
虽然HDFS读取数据的MapReduce作业大多根据所处理文件的数量和大小来选择并行度(map任务的数量),但sqoop的导出工具允许用户明确设定任务的数量。由于导出性能会受并行的数据库写入线程数量的影响,所以sqoop使用combinefileinput类将输入文件分组分配给少数几个map任务去执行。
具体使用
由于使用比较简单,就是执行导入导出的配置,可在官网查看所有参数,这里不做多介绍。
Sqoop一代和二代对比
版本号对比
两代之间是两个完全不同的版本,不兼容
sqoop1:1.4.x
sqoop2:1.99.
sqoop2比sqoop1的改进
(1) 引入sqoop server,集中化管理connector等
(2) 多种访问方式:CLI,Web UI,REST API
(3) 引入基于角色 的安全机制
sqoop1和sqoop2的架构对比
(1) : sqoop1的架构图

版本号为1.4.x为sqoop1
在架构上:sqoop1使用sqoop客户端直接提交的方式
访问方式:CLI控制台方式进行访问
安全性:命令或脚本中指定用户数据库名及密码
(2) : sqoop2的架构图

版本号为1.99x为sqoop2
在架构上:sqoop2引入了sqoop server,对connector实现了集中的管理
访问方式:REST API、 JAVA API、 WEB UI以及CLI控制台方式进行访问
CLI方式访问,会通过交互过程界面,输入的密码信息丌被看到,同时Sqoop2引入基亍角色的安全机制,Sqoop2比Sqoop多了一个Server端。
(3) : 优缺点
sqoop1与sqoop2的优缺点如下:
sqoop1的架构,仅仅使用一个sqoop客户端,sqoop2的架构,引入了sqoop,server集中化管理connector,以及rest api,web,UI,并引入权限安全机制。
sqoop1与sqoop2优缺点比较 :
sqoop1优点架构部署简单
sqoop1的缺点命令行方式容易出错,格式紧耦合,无法支持所有数据类型,安全机制不够完善,例如密码暴漏,
安装需要root权限,connector必须符合JDBC模型
sqoop2的优点多种交互方式,命令行,web UI,rest API,conncetor集中化管理,所有的链接安装在sqoop server上,完善权限管理机制,connector规范化,仅仅负责数据的读写。
sqoop2的缺点,架构稍复杂,配置部署更繁琐。
Sqoop2的核心概念
由于sqoop2是C-S架构,Sqoop的用户都必须通过sqoop-client类来与服务器交互,sqoop-client提供给用户的有:
- 连接服务器
- 搜索connectors
- 创建Link
- 创建Job
- 提交Job
- 返回Job运行信息等功能
这些基本功能包含了用户在数据迁移的过程中所用到的所有信息。
sqoop2中将数据迁移任务中的相关概念进行细分。将数据迁移任务中的数据源, 数据传输配置, 数据传输任务进行提取抽象。经过抽象分别得到核心概念Connector, Link, Job, Driver。
(1)connector
sqoop2中预定一了各种里链接,这些链接是一些配置模板,比如最基本的generic-jdbc-connector,还有hdfs-connector,通过这些模板,可以创建出对应数据源的link,比如我们链接mysql,就是使用JDBC的方式进行链接,这时候就从这个generic-jdbc-connector模板继承出一个link,可以这么理解。
(2)link
Connector是和数据源(类型)相关的。对于Link是和具体的任务Job相关的。
针对具体的Job, 例如从MySQL->HDFS 的数据迁移Job。就需要针对该Job创建和数据源MySQL的Link1,和数据目的地MySQL的Link2.
Link是和Job相关的, 针对特定的数据源,配置信息。
Link定义了从某一个数据源读出和写入时的配置信息。
(3)job
Link定义了从某一个数据源的进行读出和写入时的配置信息。Job是从一个数据源读出, 写入到另外的一个数据源的过程。
所以Job需要由Link(From), Link(To),以及Driver的信息组成。
(4)Dirver
提供了对于Job任务运行的其他信息。比如对Map/Reduce任务的配置。
- Sqoop学习笔记 --- Sqoop原理图
- sqoop学习笔记
- Sqoop学习笔记
- sqoop 学习笔记
- sqoop学习笔记
- sqoop学习笔记
- Sqoop学习笔记
- Sqoop学习笔记
- sqoop学习笔记
- sqoop 学习笔记
- sqoop学习笔记-sqoop安装部署
- Sqoop学习笔记 --- sqoop import with primary_key , or without primary_key
- Sqoop学习笔记 --- sqoop使用时候常见错误
- Sqoop学习笔记 --- python保存 Sqoop 打印的信息
- 大数据学习笔记(十四)-Sqoop
- Sqoop笔记
- sqoop笔记
- sqoop 笔记
- ASP 连接数据库
- java学习的基本语法
- tensorflow API:tf.split
- python的一些高级特性
- C#网络编程(基本概念和操作)
- sqoop 学习笔记
- Android java层binder解析 2
- (转)addhandle和removehandle
- Navicat for MySql管理工具 中文破解版
- HEVC函数入门——重要变量以及CU索引
- git rebase
- 常用开源软件
- 从excel中读取记录插入到数据库中
- MongoDB索引原理


