B-Tree 、B+树、B*树
来源:互联网 发布:淘宝删除我的评价 编辑:程序博客网 时间:2024/06/05 19:24
http://blog.csdn.net/sdauzxl/article/details/52234482
大规模数据存储中,实现索引查询这样一个实际背景下,树节点存储的元素数量是有限的(如果元素数量非常多的话,查找就退化成节点内部的线性查找了),这样导致二叉查找树结构由于树的深度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下。
1. B-Tree
B 树是为了磁盘或其它存储设备而设计的一种多叉平衡查找树。许多数据库系统都一般使用B树或者B树的各种变形结构,如下文即将要介绍的B+树,B*树来存储信息。
B树与红黑树最大的不同在于,B树的结点可以有许多子女,从几个到几千个。与红黑树的相同之处在于,一棵含n个结点的B树的高度也为O(lgn),但可能比一棵红黑树的高度小许多,应为它的分支因子比较大。所以,B树可以在O(logn)时间内,实现各种如插入(insert),删除(delete)等动态集合操作。
如下图所示,即是一棵B树,一棵关键字为英语中辅音字母的B树,现在要从树种查找字母R(包含n[x]个关键字的内结点x,x有n[x]+1个子女(也就是说,一个内结点x若含有n[x]个关键字,那么x将含有n[x]+1个子女)。所有的叶结点都处于相同的深度,带阴影的结点为查找字母R时要检查的结点):

B 树又叫平衡多路查找树。一棵m阶的B树的特性如下:
I. 树中每个结点最多含有m个孩子(m>=2);
II. 除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
III. 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
IV. 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);
V. 每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树中所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。
B-Tree 数据结构:
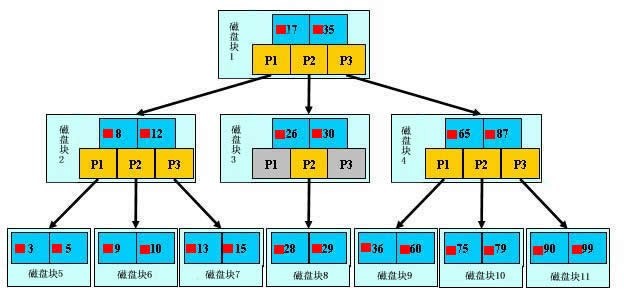
B-Tree的度:
B-Tree中每个节点能包含的关键字的数量有一个上界和下界。下界称为B-Tree的最小度数。
B-Tree的高度:
a) 从B-Tree的最小度来计算
B树上大部分操作所需的磁盘存取次数与B树的高度成正比。下面分析B树的最坏高度情况。如果n>=1, 则对任意一棵包含n个关键字、高度为h(从0开始)、最小度数t>=2的B树有: h = logt((n+1)/2);
证明:
如果一棵B-Tree的高度为h,其根节点至少包括一个关键字,而其他节点至少t-1个关键字。深度为1的节点至少有两个,深度为2的节点至少有2t个,深度为3的节点至少为2t2,…..,深度为h 的节点至少为2th-1,因此,
所以:h = logt((n+1)/2);
b) 从B-Tree的阶数计算
若B树某一非叶子节点包含N个关键字,则此非叶子节点含有N+1个孩子结点,而所有的叶子结点都在第I层,我们可以得出:
1. 因为根至少有两个孩子,因此第2层至少有两个结点。
2. 除根和叶子外,其它结点至少有┌m/2┐个孩子,
3. 因此在第3层至少有2*┌m/2┐个结点,
4. 在第4层至少有2*(┌m/2┐^2)个结点,
5. 在第 I层至少有2*(┌m/2┐^(l-2) )个结点,于是有: N+1 ≥ 2*┌m/2┐I-2;
6. 考虑第L层的结点个数为N+1,那么2*(┌m/2┐^(l-2))≤N+1,也就是L层的最少结点数刚好达到N+1个,即: I≤ log┌m/2┐((N+1)/2 )+2;
所以
· 当B树包含N个关键字时,B树的最大高度为l-1(因为计算B树高度时,叶结点所在层不计算在内),即:l - 1 = log┌m/2┐((N+1)/2 )+1。
2. B+树
B+树是B-树的变体,也是一种多路搜索树:
其定义基本与B-树同,除了:
1.非叶子结点的子树指针与关键字个数相同;
2.非叶子结点的子树指针P[i],指向关键字值属于[K[i],K[i+1])的子树(B-树是开区间);
3.为所有叶子结点增加一个链指针;
4所有关键字都在叶子结点出现
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在
非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好
是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储
(关键字)数据的数据层;
4.更适合文件索引系统;

B+树
B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3
(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据
复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父
结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分
数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字
(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之
间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;

B*树
- B-Tree, B+Tree, B*树介绍
- B-Tree, B+Tree, B*树介绍
- B-Tree 、B+树、B*树
- B-Tree、B+树、B*树
- B-Tree 、B+树、B*树
- B-Tree 、B+树、B*树
- B-tree(B树)介绍
- B-tree\B+tree\B*tree=>B树、B+树、B*树
- B树(即B-tree)、B+树、B*树
- B树、B-tree B+树、B*树
- B树、B-tree B+树、B*树
- B,B-,B+,B*树
- B-、B、B+、B*树
- B/B+/B*树
- B- ,B+ , B*树
- B , B+ ,B*树
- B-, B+,B* 树
- B 树/B-树(B-Tree/Bee Tree)
- idea中的springboot项目打包成war包部署到tomcat中
- MFC中CSTATIC控件双击全屏/双击恢复
- IR cut filter 与 color shading
- Swift 扩展 Storyboard 属性
- Python基础-面向对象和面向过程编程区别
- B-Tree 、B+树、B*树
- RecyclerView多布局适配器
- Retrofit+MVP登录注册+EventBus
- C#网络编程系列文章(七)之UdpClient实现异步UDP服务器
- mt2503 [Editor]Email编辑界面字符显示滞后,跟不上手写速度
- 2D游戏新手引导点光源和类迷雾实现
- tensorflow实践(二) 基本原理学习和框架使用
- 文章标题
- stopPropagation()和preventDefault()


