Python-机器学习 入门及技巧总结
来源:互联网 发布:华中师范网络教育收费 编辑:程序博客网 时间:2024/05/17 02:51
随着这两年人工智能的快速发展,机器学习与深度学习行业炙手可热,对于那些想进入这个行业的同学们,小编在这里给大家介绍一下自己的心得体会以及利用Python的一些小技巧,希望对大家有所帮助。
在机器学习方面,对于想入门的新手,首先不得不提就是斯坦福大学的Andrew Ng-吴恩达,他在例如Coursera等网站上面的课程非常适合新手,并且当你入门之后,回头再看,又会有新的收获,在这里我把相应的链接放在这里Machine Learning | Coursera。
对于一个机器学习工程,或者参加例如kaggel、天池之类的比赛也好,流程都是类似的,小编在这里对前人的工作进行了一下总结。流程如下:
- 对数据进行简单的清洗与处理,得到一些基本特征。
- 建立简单的机器学习模型,按照重要性对特征进行排列。
- 根据得到的特征排列,有针对的进行特征工程,提取特征
- 重复上述过程,不断的优化自己的模型,找到关键的特征
- 对模型的参数进行调参,采用例如grid search的方法找到最优参数
- 进行模型融合,采用如Stacking 的方法得到最佳模型组合
对于实际的机器学习工程问题,数据的获取以及清洗是一件非常头疼事情,在这个方面要花费非常大的精力,而我们上述的流程比较适合一些初步清洗较好的数据,比较适用于一些比赛项目流程。
好了,说完机器学习基本流程,下面我们来说一下技巧了。目前,在机器学习方面最流行的有两种语言,一个是R,另外一个是Python,在这里小编介绍一下利用Python进行机器学习的一些小技巧,这些技巧对于大家的特征工程都有很大的帮助。
1. 数据读取
一般采用Python 的pandas 包,大部分数据集都可以利用它来读取,如pd.read_csv
数据查看DataFrame.describe() 或 head()
图片采用PIL或者OpenCV

2. 数据分析
2.1一元分析
数据可视化对分析数据有着非常大的帮助,帮助我们更加直观地理解数据。
工具Seaborn matplotlib
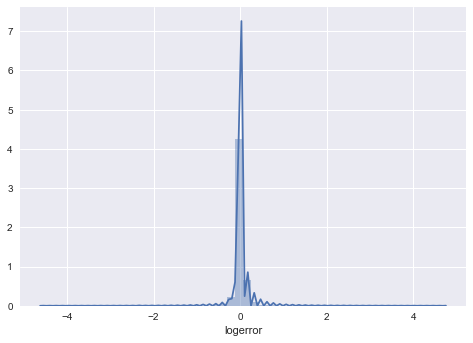 某数据概率分布图
某数据概率分布图
对数据采用去除异常值或者进行变换,如对数变换等,将其变为更加符合正态分布的数据集。
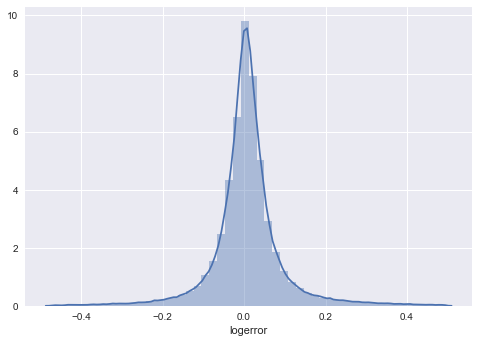 mean=np.mean(y_train)std=np.std(y_train)y_train_index=y_train[y_train>mean-3*std][y_train
mean=np.mean(y_train)std=np.std(y_train)y_train_index=y_train[y_train>mean-3*std][y_train一元分析-数据及工具
数据类型:
- 数值型
- 非数值型

对于普通一元数据,对其分布进行查看:
一元分析图 一元分析图
一元分析图对于经常出现的时间特征,我们通常利用Python的datetime 工具包:
时间类型与字符串的变换 时间类型与字符串的变换
时间类型与字符串的变换Python的时间包,可以帮助我们提取年、月、日、星期等数据,方便我们进行更加详细的分析。
对于非数值型工具:

在机器学习模型中,计算机仅仅能识别数字,所以我们需要将任何类型的信息转化为数值信息,对于一些分类字符串特征,如男、女,我们采用一些Python的函数,可以方便的对其进行处理。
而对于一些非常长的字符串信息,我们则需要利用Python pandas的内置一些字符串函数进行处理,它让我们像C语言中处理字符串一样,可以同时对每一个特征进行处理:

除上述情况中,有一些数据是分类特征,这种数据又可以分为两类,一种是可以比较大小的,如衣服的尺码,是s、m、和、l,他们之间的大小比较是有意义的,另一种分类数据与其不同,他们是不能用大小去衡量的,如颜色,蓝色、绿色和黄色,代表三种类别,但是他们之间却没有大小的差别。所以,我们往往对这些数据进行编码,一般采用三种方式:
- 虚拟变量或者哑变量
- 普通编码
- onehot 编码

2.2 多元分析
我们仍从数据可视化入手。
函数工具及一般参数与上述函数对应的可视化图例子 函数工具及一般参数
函数工具及一般参数 与上述函数对应的可视化图例子
与上述函数对应的可视化图例子Seaborn一个Python中非常适合做数据分析的包,它有许许多多绘图模式供我们使用。其中pairplot 可以帮助我们分析一组数据任意两个变量之间的分布关系,heatmap可以帮助我们分型一组数据之间相关性,boxplot与violinplot可以帮助我们理解两三组变量之间的分布关系。
下面介绍一些常用的多元分析函数。
1.灵活运用索引
Python作为数据分析工具,最大的特点就是简单、灵活,我们对索引的灵活运用可以帮助我们快速方便的分析数据。如利用索引得到某一列数据中满足一些条件的数据:
df['Family'][titanic_df['Family'] > 0] = 1
df[‘Family’][titanic_df[‘Family’].notnull()]
2.常用函数
- DF.drop('column_name',axis=1, inplace=True)
- Pd.merge(left,right, how=‘inner’, on=‘left’)
- DF.Groupby()
上述函数可以对数据进行删除、合并以及分组。其中分组函数groupby是一个非常强大的工具,下面我们详细的介绍一下它的两种用法;
迭代与非迭代方法 迭代与非迭代方法
迭代与非迭代方法3. 模型建立
当数据分析完之后,我们需要建立机器学习算法模型,下面我们稍微介绍一下陈天奇大神的XGBOOST算法,,这个算法在各种比赛大放异彩,速度快,效果好,xgb常用的算法参数有:



一般而言,大家使用这个算法都采用两种方式,第一种直接利用该模型训练,第二种,采用算法包中的分类器或者回归器进行拟合,下面是两个例子分别对应两种方法:
 第一种方法
第一种方法 第二种用法
第二种用法在第二种用法中,我们采用了交叉验证的方式,来评估我们的模型。
4. 模型融合
模型融合的方式有很多种,并没有一个统一的方法,并且,根据实际情况,需要设计出效果最好的模型,最简单的模型融合,如多数投票表决,或者类似于多模型预测取平均等,我们这里介绍一下较为常用的stacking:
stacking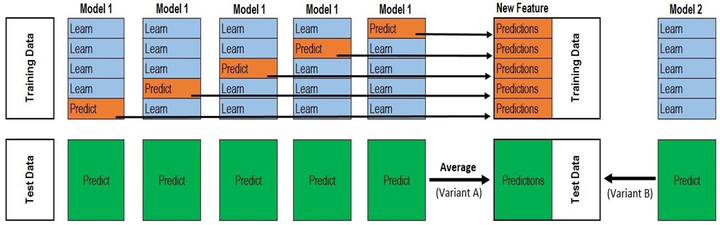 stacking
stacking上面这幅图就是stacking的流程图,它采用五个模型进行融合,每个模型得到一个预测值,然后利用这五个预测值作为新的特征,再重新建立一个模型,最终得到预测结果。对上述图需要注意的是,每个模型对数据进行了预测,在这个预测过程中,将数据集进行了划分,最后的预测结果是多次预测取平均。
- Python-机器学习 入门及技巧总结
- python 机器学习入门资料
- 学习总结及技巧
- Python机器学习及实践:
- python入门学习总结
- Python基础学习-机器学习入门·
- 机器学习-->python常用可视化技巧
- 机器学习必备的计算机编程技巧(matlab、python)和总结——第三弹!!!
- 机器学习必备的计算机编程技巧(matlab、python)和总结——第一蛋
- 机器学习必备的计算机编程技巧(matlab、python)和总结——第二弹!!!
- 机器学习入门必备Anaconda多环境多版本python配置指导及使用
- 从0开始入门机器学习|python及库的安装
- python机器学习:从入门到精通
- python机器学习入门资料梳理
- 七步快速入门 Python机器学习
- python机器学习入门资料梳理
- python机器学习库入门之pandas
- python从入门到机器学习
- Angular 4.3 HttpClient (Angular访问 REST Web 服务) 三、拦截器 Interceptors
- 推荐一个生成app应用图标的方法
- How Many Tables(并查集)
- Android View 系统 1
- uva 1586 分子量————C12H22O11读取数字12。。。
- Python-机器学习 入门及技巧总结
- 12月13日学习笔记-文件的打开与使用
- 【算法竞赛入门经典】6.2链表 例题6-4 UVa11988
- SSL P2325 最小转弯
- 教育场景高性能架构技术选型与实践
- java--面向对象之多态3
- 杨辉三角
- Java面试原题:介绍一下hibernate的二级缓存
- 欢迎使用CSDN-markdown编辑器


