Flink架构、原理与部署测试
来源:互联网 发布:星际争霸1数据修改 编辑:程序博客网 时间:2024/06/01 18:06
1>针对无界数据的持久计算。
Latest stable release (v1.4.0)
Apache Flink® 1.4.0 is our latest stable release.
An Apache Hadoop installation is not required to use Flink. If you plan to run Flink in YARN or process data stored in HDFS then select the version matching your installed Hadoop version.
The binary releases marked with a Hadoop version come bundled with binaries for that Hadoop version, the binary release without bundled Hadoop can be used without Hadoop or with a Hadoop version that is installed in the environment, i.e. this version can pick up a Hadoop version from the classpath.
Binaries
Source
Apache Flink® 1.4.0 Source Release
Review the source code or build Flink on your own, using this package
(asc, md5)Verifying Hashes and Signatures
Along our releases, we also provide MD5 hashes in *.md5 files and cryptographic signatures in *.asc files. The Apache Software Foundation has an extensive tutorial to verify hashes and signatures which you can follow by using any of these release-signing KEYS.
Maven Dependencies
You can add the following dependencies to your pom.xml to include Apache Flink in your project. These dependencies include a local execution environment and thus support local testing.
- Scala API: To use the Scala API, replace the
flink-javaartifact id withflink-scala_2.11andflink-streaming-java_2.11withflink-streaming-scala_2.11.
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.4.0</version></dependency><dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.11</artifactId> <version>1.4.0</version></dependency><dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_2.11</artifactId> <version>1.4.0</version></dependency>Update Policy for old releases
As of March 2017, the Flink community decided to support the current and previous minor release with bugfixes. If 1.2.x is the current release, 1.1.y is the previous minor supported release. Both versions will receive bugfixes for critical issues.
Note that the community is always open for discussing bugfix releases for even older versions. Please get in touch with the developers for that on the dev@flink.apache.org mailing list.
All releases
All Flink releases are available via https://archive.apache.org/dist/flink/ including checksums and cryptographic signatures. At the time of writing, this includes the following versions:
- Flink 1.4.0 - 2017-11-29 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 1.3.2 - 2017-08-05 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 1.3.1 - 2017-06-23 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 1.3.0 - 2017-06-01 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 1.2.1 - 2017-04-26 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 1.2.0 - 2017-02-06 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 1.1.5 - 2017-03-22 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 1.1.4 - 2016-12-21 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 1.1.3 - 2016-10-13 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 1.1.2 - 2016-09-05 (Source, Binaries)
- Flink 1.1.1 - 2016-08-11 (Source, Binaries)
- Flink 1.1.0 - 2016-08-08 (Source, Binaries)
- Flink 1.0.3 - 2016-05-12 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 1.0.2 - 2016-04-23 (Source, Binaries)
- Flink 1.0.1 - 2016-04-06 (Source, Binaries)
- Flink 1.0.0 - 2016-03-08 (Source, Binaries)
- Flink 0.10.2 - 2016-02-11 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 0.10.1 - 2015-11-27 (Source, Binaries)
- Flink 0.10.0 - 2015-11-16 (Source, Binaries)
- Flink 0.9.1 - 2015-09-01 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 0.9.0 - 2015-06-24 (Source, Binaries)
- Flink 0.9.0-milestone-1 - 2015-04-13 (Source, Binaries)
- Flink 0.8.1 - 2015-02-20 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 0.8.0 - 2015-01-22 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 0.7.0-incubating - 2014-11-04 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 0.6.1-incubating - 2014-09-26 (Source, Binaries, Docs, Javadocs, ScalaDocs)
- Flink 0.6-incubating - 2014-08-26 (Source, Binaries, Docs, Javadocs, ScalaDocs)
Previous Stratosphere releases are available on Github.
Flink runs on Linux, Mac OS X, and Windows. To be able to run Flink, the only requirement is to have a working Java 7.x (or higher) installation. Windows users, please take a look at the Flink on Windows guide which describes how to run Flink on Windows for local setups.
You can check the correct installation of Java by issuing the following command:
java -versionIf you have Java 8, the output will look something like this:
java version "1.8.0_111"Java(TM) SE Runtime Environment (build 1.8.0_111-b14)Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)- Download a binary from the downloads page. You can pick any Hadoop/Scala combination you like. If you plan to just use the local file system, any Hadoop version will work fine.
- Go to the download directory.
- Unpack the downloaded archive.
$ cd ~/Downloads # Go to download directory$ tar xzf flink-*.tgz # Unpack the downloaded archive$ cd flink-1.2For MacOS X users, Flink can be installed through Homebrew.
$ brew install apache-flink...$ flink --versionVersion: 1.2.0, Commit ID: 1c659cfStart a Local Flink Cluster
$ ./bin/start-local.sh # Start FlinkCheck the JobManager’s web frontend at http://localhost:8081 and make sure everything is up and running. The web frontend should report a single available TaskManager instance.

You can also verify that the system is running by checking the log files in the logs directory:
$ tail log/flink-*-jobmanager-*.logINFO ... - Starting JobManagerINFO ... - Starting JobManager web frontendINFO ... - Web frontend listening at 127.0.0.1:8081INFO ... - Registered TaskManager at 127.0.0.1 (akka://flink/user/taskmanager)Read the Code
You can find the complete source code for this SocketWindowWordCount example in scala and java on GitHub.
object SocketWindowWordCount { def main(args: Array[String]) : Unit = { // the port to connect to val port: Int = try { ParameterTool.fromArgs(args).getInt("port") } catch { case e: Exception => { System.err.println("No port specified. Please run 'SocketWindowWordCount --port <port>'") return } } // get the execution environment val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // get input data by connecting to the socket val text = env.socketTextStream("localhost", port, '\n') // parse the data, group it, window it, and aggregate the counts val windowCounts = text .flatMap { w => w.split("\\s") } .map { w => WordWithCount(w, 1) } .keyBy("word") .timeWindow(Time.seconds(5), Time.seconds(1)) .sum("count") // print the results with a single thread, rather than in parallel windowCounts.print().setParallelism(1) env.execute("Socket Window WordCount") } // Data type for words with count case class WordWithCount(word: String, count: Long)}public class SocketWindowWordCount { public static void main(String[] args) throws Exception { // the port to connect to final int port; try { final ParameterTool params = ParameterTool.fromArgs(args); port = params.getInt("port"); } catch (Exception e) { System.err.println("No port specified. Please run 'SocketWindowWordCount --port <port>'"); return; } // get the execution environment final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // get input data by connecting to the socket DataStream<String> text = env.socketTextStream("localhost", port, "\n"); // parse the data, group it, window it, and aggregate the counts DataStream<WordWithCount> windowCounts = text .flatMap(new FlatMapFunction<String, WordWithCount>() { @Override public void flatMap(String value, Collector<WordWithCount> out) { for (String word : value.split("\\s")) { out.collect(new WordWithCount(word, 1L)); } } }) .keyBy("word") .timeWindow(Time.seconds(5), Time.seconds(1)) .reduce(new ReduceFunction<WordWithCount>() { @Override public WordWithCount reduce(WordWithCount a, WordWithCount b) { return new WordWithCount(a.word, a.count + b.count); } }); // print the results with a single thread, rather than in parallel windowCounts.print().setParallelism(1); env.execute("Socket Window WordCount"); } // Data type for words with count public static class WordWithCount { public String word; public long count; public WordWithCount() {} public WordWithCount(String word, long count) { this.word = word; this.count = count; } @Override public String toString() { return word + " : " + count; } }}Run the Example
Now, we are going to run this Flink application. It will read text from a socket and once every 5 seconds print the number of occurrences of each distinct word during the previous 5 seconds, i.e. a tumbling window of processing time, as long as words are floating in.
First of all, we use netcat to start local server via
$ nc -l 9000Submit the Flink program:
$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000Cluster configuration: Standalone cluster with JobManager at /127.0.0.1:6123Using address 127.0.0.1:6123 to connect to JobManager.JobManager web interface address http://127.0.0.1:8081Starting execution of programSubmitting job with JobID: 574a10c8debda3dccd0c78a3bde55e1b. Waiting for job completion.Connected to JobManager at Actor[akka.tcp://flink@127.0.0.1:6123/user/jobmanager#297388688]11/04/2016 14:04:50 Job execution switched to status RUNNING.11/04/2016 14:04:50 Source: Socket Stream -> Flat Map(1/1) switched to SCHEDULED11/04/2016 14:04:50 Source: Socket Stream -> Flat Map(1/1) switched to DEPLOYING11/04/2016 14:04:50 Fast TumblingProcessingTimeWindows(5000) of WindowedStream.main(SocketWindowWordCount.java:79) -> Sink: Unnamed(1/1) switched to SCHEDULED11/04/2016 14:04:51 Fast TumblingProcessingTimeWindows(5000) of WindowedStream.main(SocketWindowWordCount.java:79) -> Sink: Unnamed(1/1) switched to DEPLOYING11/04/2016 14:04:51 Fast TumblingProcessingTimeWindows(5000) of WindowedStream.main(SocketWindowWordCount.java:79) -> Sink: Unnamed(1/1) switched to RUNNING11/04/2016 14:04:51 Source: Socket Stream -> Flat Map(1/1) switched to RUNNINGThe program connects to the socket and waits for input. You can check the web interface to verify that the job is running as expected:


Words are counted in time windows of 5 seconds (processing time, tumbling windows) and are printed to
stdout. Monitor the JobManager’s output file and write some text innc(input is sent to Flink line by line after hitting ):$ nc -l 9000lorem ipsumipsum ipsum ipsumbyeThe
.outfile will print the counts at the end of each time window as long as words are floating in, e.g.:$ tail -f log/flink-*-jobmanager-*.outlorem : 1bye : 1ipsum : 4To stop Flink when you’re done type:
$ ./bin/stop-local.sh
Next Steps
Check out some more examples to get a better feel for Flink’s programming APIs. When you are done with that, go ahead and read the streaming guide.
安装:下载并启动
Flink可以在Linux、Mac OS X以及Windows上运行。为了能够运行Flink,唯一的要求是必须安装Java 7.x或者更高版本。对于Windows用户来说,请参考 Flink on Windows 文档,里面介绍了如何在Window本地运行Flink。
下载
从下载页面(http://flink.apache.org/downloads.html)下载所需的二进制包。你可以选择任何与 Hadoop/Scala 结合的版本。比如 Flink for Hadoop 2。
启动一个local模式的Flink集群
启动一个local模式的Flink集群非常地简单,我们可以按照以下的步骤来操作:
1、进入到下载的目录;
2、解压下载的文件;
3、启动Flink。
操作命令如下:
$cd~/Downloads # Go to download directory$tarxzf flink-*.tgz # Unpack the downloaded archive$cdflink-1.0.0$ bin/start-local.sh # Start Flink打开https://www.iteblog.com:8081检查Jobmanager和其他组件是否正常运行。Web前端应该显示了只有一个可用的 TaskManager。

运行例子
现在,我们来运行SocketTextStreamWordCount例子,它从socket中获取文本,然后计算每个单词出现的次数。操作步骤如下:
1、首先,我们使用netcat来启动本地服务器:
$ nc -l -p 90002、然后我们就可以提交Flink程序了:
$ bin/flinkrun examples/streaming/SocketTextStreamWordCount.jar \ --hostnamelocalhost \ --port 9000Printing result to stdout. Use --output to specify output path.04/05/201616:03:36 Job execution switched to status RUNNING.04/05/201616:03:36 Source: Socket Stream -> Flat Map(1/1) switched to SCHEDULED 04/05/201616:03:36 Source: Socket Stream -> Flat Map(1/1) switched to DEPLOYING 04/05/201616:03:36 Keyed Aggregation -> Sink: Unnamed(1/1) switched to SCHEDULED 04/05/201616:03:36 Keyed Aggregation -> Sink: Unnamed(1/1) switched to DEPLOYING 04/05/201616:03:36 Keyed Aggregation -> Sink: Unnamed(1/1) switched to RUNNING 04/05/201616:03:36 Source: Socket Stream -> Flat Map(1/1) switched to RUNNING 04/05/201617:00:43 Source: Socket Stream -> Flat Map(1/1) switched to FINISHED 04/05/201617:00:43 Keyed Aggregation -> Sink: Unnamed(1/1) switched to FINISHED 04/05/201617:00:43 Job execution switched to status FINISHED.这个程序和socket进行了连接,并等待输入。我们可以在WEB UI中检查Job是否正常运行:


3、计数会打印到标准输出stdout。监控JobManager的输出文件(.out文件),并在nc中敲入一些单词:
$ nc -l -p 9000lorem ipsumipsum ipsum ipsumbye.out 文件会立即打印出单词的计数:
$tail-f log/flink-*-jobmanager-*.out(lorem,1)(ipsum,1)(ipsum,2)(ipsum,3)(ipsum,4)(bye,1)要停止 Flink,只需要运行:
$ bin/stop-local.sh
集群模式安装
在集群上运行 Flink 是和在本地运行一样简单的。需要先配置好 SSH 免密码登录 和保证所有节点的目录结构是一致的,这是保证我们的脚本能正确控制任务启停的关键。然后我们就可以按照下面步骤来操作:
1、在每台节点上,复制解压出来的 flink 目录到同样的路径下。
2、选择一个 master 节点 (JobManager) 然后在 conf/flink-conf.yaml 中设置 jobmanager.rpc.address 配置项为该节点的 IP 或者主机名。确保所有节点有有一样的 jobmanager.rpc.address 配置。
3、将所有的 worker 节点 (TaskManager)的 IP 或者主机名(一行一个)填入 conf/slaves 文件中。
现在,你可以在 master 节点上启动集群:bin/start-cluster.sh。
下面的例子阐述了三个节点的集群部署(IP地址从 10.0.0.1 到 10.0.0.3,主机名分别为 master, worker1, worker2)。并且展示了配置文件,以及所有机器上一致的可访问的安装路径。

访问https://ci.apache.org/projects/flink/flink-docs-release-1.0/setup/config.html查看更多可用的配置项。为了使 Flink 更高效的运行,还需要设置一些配置项。
以下都是非常重要的配置项:
1、TaskManager 总共能使用的内存大小(taskmanager.heap.mb)
2、每一台机器上能使用的 CPU 个数(taskmanager.numberOfTaskSlots)
3、集群中的总 CPU 个数(parallelism.default)
4、临时目录(taskmanager.tmp.dirs)
Flink on YARN
你可以很方便地将 Flink 部署在现有的YARN集群上,操作如下:
1、下载 Flink Hadoop2 包: Flink with Hadoop 2
2、确保你的 HADOOP_HOME (或 YARN_CONF_DIR 或 HADOOP_CONF_DIR) __环境变量__设置成你的 YARN 和 HDFS 配置。
3、运行 YARN 客户端:./bin/yarn-session.sh 。你可以带参数运行客户端 -n 10 -tm 8192 表示分配 10 个 TaskManager,每个拥有 8 GB 的内存。
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能。
现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为它们所提供的SLA(Service-Level-Aggreement)是完全不相同的:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理。
Flink从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
Flink流处理特性:
- 支持高吞吐、低延迟、高性能的流处理
- 支持带有事件时间的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
- 支持具有Backpressure功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot)实现的容错
- 一个运行时同时支持Batch on Streaming处理和Streaming处理
- Flink在JVM内部实现了自己的内存管理
- 支持迭代计算
- 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
一、架构
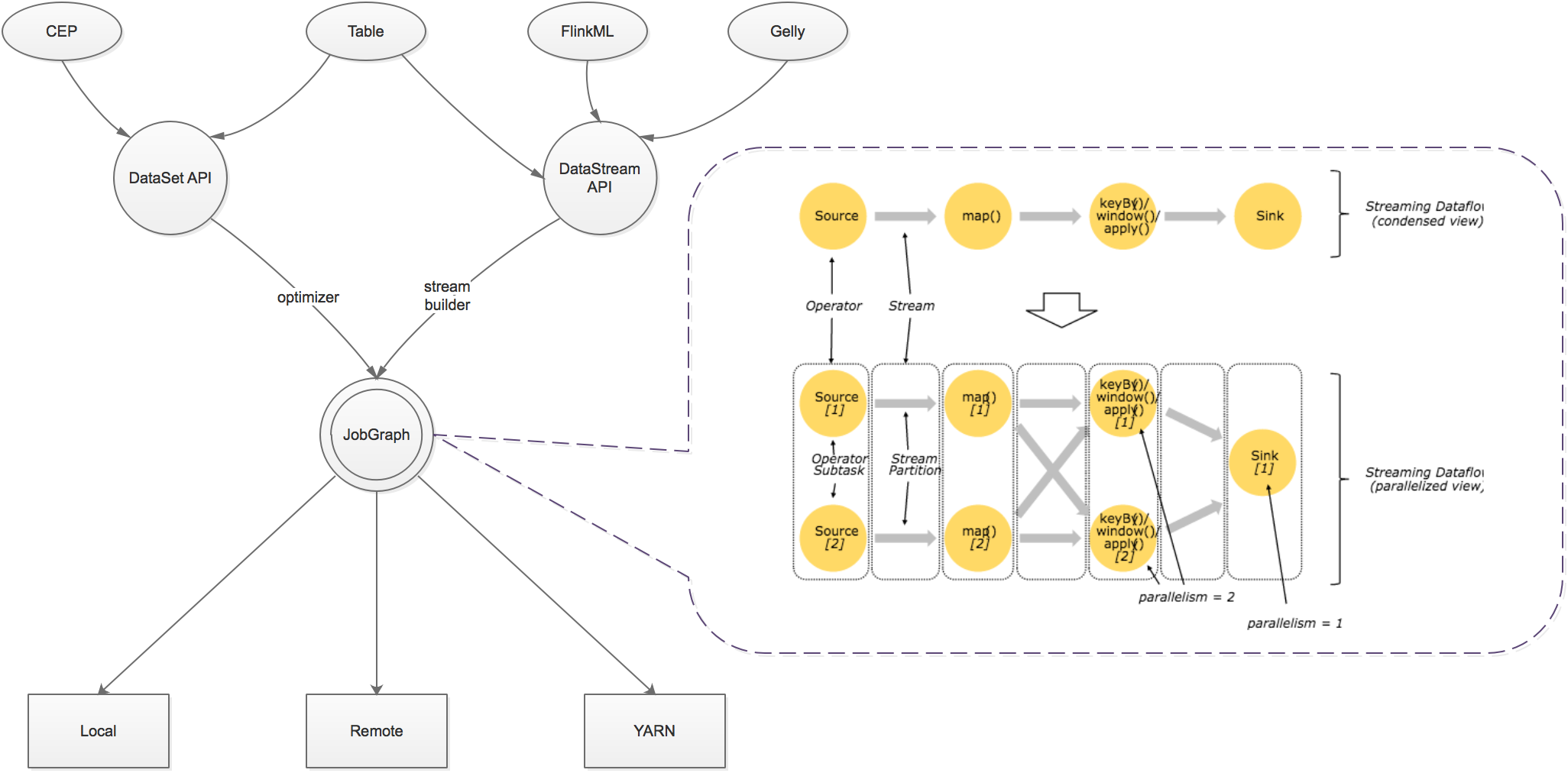
Flink以层级式系统形式组件其软件栈,不同层的栈建立在其下层基础上,并且各层接受程序不同层的抽象形式。
- 运行时层以JobGraph形式接收程序。JobGraph即为一个一般化的并行数据流图(data flow),它拥有任意数量的Task来接收和产生data stream。
- DataStream API和DataSet API都会使用单独编译的处理方式生成JobGraph。DataSet API使用optimizer来决定针对程序的优化方法,而DataStream API则使用stream builder来完成该任务。
- 在执行JobGraph时,Flink提供了多种候选部署方案(如local,remote,YARN等)。
- Flink附随了一些产生DataSet或DataStream API程序的的类库和API:处理逻辑表查询的Table,机器学习的FlinkML,图像处理的Gelly,复杂事件处理的CEP。
二、原理
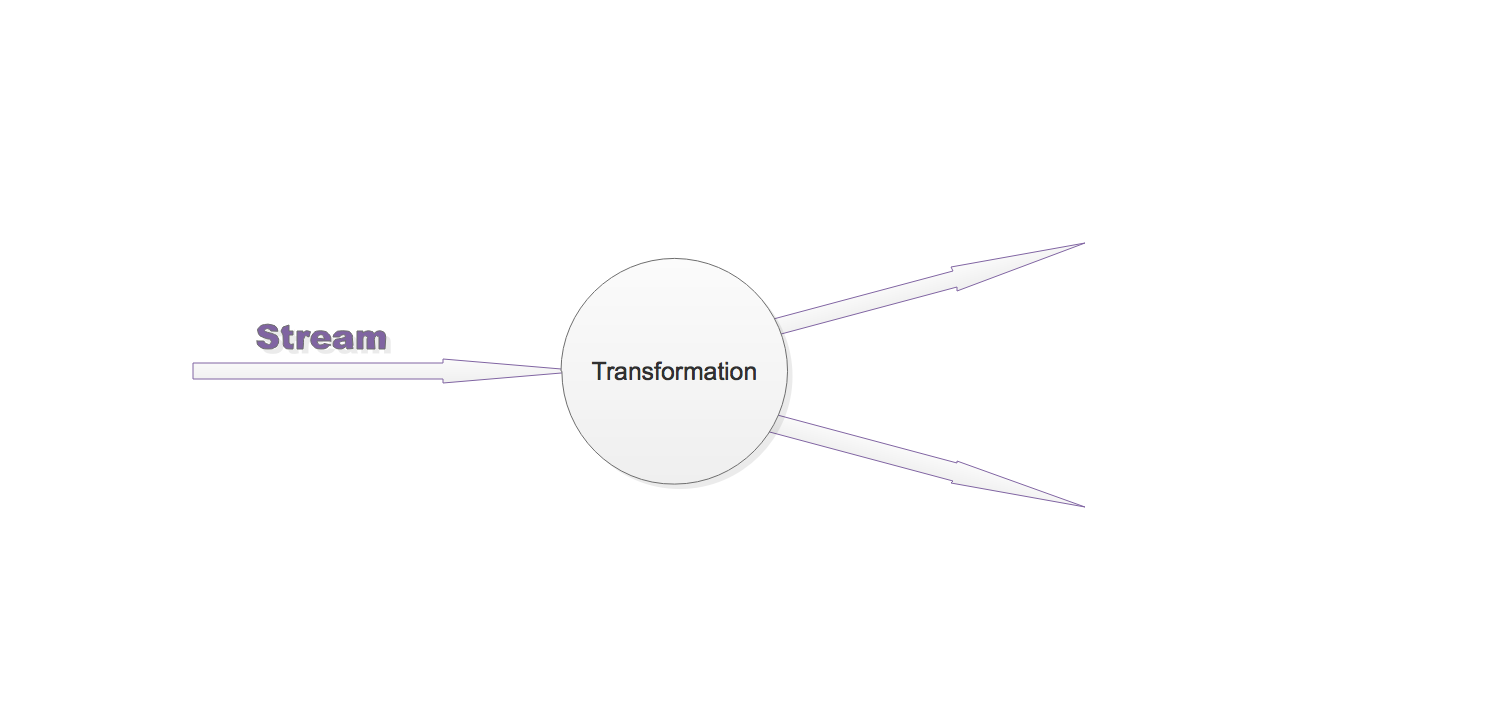
1. 流、转换、操作符
Flink程序是由Stream和Transformation这两个基本构建块组成,其中Stream是一个中间结果数据,而Transformation是一个操作,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。
Flink程序被执行的时候,它会被映射为Streaming Dataflow。一个Streaming Dataflow是由一组Stream和Transformation Operator组成,它类似于一个DAG图,在启动的时候从一个或多个Source Operator开始,结束于一个或多个Sink Operator。

2. 并行数据流
一个Stream可以被分成多个Stream分区(Stream Partitions),一个Operator可以被分成多个Operator Subtask,每一个Operator Subtask是在不同的线程中独立执行的。一个Operator的并行度,等于Operator Subtask的个数,一个Stream的并行度总是等于生成它的Operator的并行度。

One-to-one模式
比如从Source[1]到map()[1],它保持了Source的分区特性(Partitioning)和分区内元素处理的有序性,也就是说map()[1]的Subtask看到数据流中记录的顺序,与Source[1]中看到的记录顺序是一致的。
Redistribution模式
这种模式改变了输入数据流的分区,比如从map()[1]、map()[2]到keyBy()/window()/apply()[1]、keyBy()/window()/apply()[2],上游的Subtask向下游的多个不同的Subtask发送数据,改变了数据流的分区,这与实际应用所选择的Operator有关系。
3. 任务、操作符链
Flink分布式执行环境中,会将多个Operator Subtask串起来组成一个Operator Chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行。

4. 时间
处理Stream中的记录时,记录中通常会包含各种典型的时间字段:
- Event Time:表示事件创建时间
- Ingestion Time:表示事件进入到Flink Dataflow的时间
- Processing Time:表示某个Operator对事件进行处理的本地系统时间

Flink使用WaterMark衡量时间的时间,WaterMark携带时间戳t,并被插入到stream中。
- WaterMark的含义是所有时间t'< t的事件都已经发生。
- 针对乱序的的流,WaterMark至关重要,这样可以允许一些事件到达延迟,而不至于过于影响window窗口的计算。
- 并行数据流中,当Operator有多个输入流时,Operator的event time以最小流event time为准。

5. 窗口
Flink支持基于时间窗口操作,也支持基于数据的窗口操作:

窗口分类:
- 按分割标准划分:timeWindow、countWindow
- 按窗口行为划分:Tumbling Window、Sliding Window、自定义窗口
Tumbling/Sliding Time Window
// Stream of (sensorId, carCnt)val vehicleCnts: DataStream[(Int, Int)] = ...val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts // key stream by sensorId .keyBy(0) // tumbling time window of 1 minute length .timeWindow(Time.minutes(1)) // compute sum over carCnt .sum(1) val slidingCnts: DataStream[(Int, Int)] = vehicleCnts .keyBy(0) // sliding time window of 1 minute length and 30 secs trigger interval .timeWindow(Time.minutes(1), Time.seconds(30)) .sum(1)Tumbling/Sliding Count Window
// Stream of (sensorId, carCnt)val vehicleCnts: DataStream[(Int, Int)] = ...val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts // key stream by sensorId .keyBy(0) // tumbling count window of 100 elements size .countWindow(100) // compute the carCnt sum .sum(1)val slidingCnts: DataStream[(Int, Int)] = vehicleCnts .keyBy(0) // sliding count window of 100 elements size and 10 elements trigger interval .countWindow(100, 10) .sum(1)自定义窗口

基本操作:
- window:创建自定义窗口
- trigger:自定义触发器
- evictor:自定义evictor
- apply:自定义window function
6. 容错
Barrier机制:

- 出现一个Barrier,在该Barrier之前出现的记录都属于该Barrier对应的Snapshot,在该Barrier之后出现的记录属于下一个Snapshot。
- 来自不同Snapshot多个Barrier可能同时出现在数据流中,也就是说同一个时刻可能并发生成多个Snapshot。
- 当一个中间(Intermediate)Operator接收到一个Barrier后,它会发送Barrier到属于该Barrier的Snapshot的数据流中,等到Sink Operator接收到该Barrier后会向Checkpoint Coordinator确认该Snapshot,直到所有的Sink Operator都确认了该Snapshot,才被认为完成了该Snapshot。
对齐:
当Operator接收到多个输入的数据流时,需要在Snapshot Barrier中对数据流进行排列对齐:
- Operator从一个incoming Stream接收到Snapshot Barrier n,然后暂停处理,直到其它的incoming Stream的Barrier n(否则属于2个Snapshot的记录就混在一起了)到达该Operator
- 接收到Barrier n的Stream被临时搁置,来自这些Stream的记录不会被处理,而是被放在一个Buffer中。
- 一旦最后一个Stream接收到Barrier n,Operator会emit所有暂存在Buffer中的记录,然后向Checkpoint Coordinator发送Snapshot n。
- 继续处理来自多个Stream的记录

基于Stream Aligning操作能够实现Exactly Once语义,但是也会给流处理应用带来延迟,因为为了排列对齐Barrier,会暂时缓存一部分Stream的记录到Buffer中,尤其是在数据流并行度很高的场景下可能更加明显,通常以最迟对齐Barrier的一个Stream为处理Buffer中缓存记录的时刻点。在Flink中,提供了一个开关,选择是否使用Stream Aligning,如果关掉则Exactly Once会变成At least once。
CheckPoint:
Snapshot并不仅仅是对数据流做了一个状态的Checkpoint,它也包含了一个Operator内部所持有的状态,这样才能够在保证在流处理系统失败时能够正确地恢复数据流处理。状态包含两种:
- 系统状态:一个Operator进行计算处理的时候需要对数据进行缓冲,所以数据缓冲区的状态是与Operator相关联的。以窗口操作的缓冲区为例,Flink系统会收集或聚合记录数据并放到缓冲区中,直到该缓冲区中的数据被处理完成。
- 一种是用户自定义状态(状态可以通过转换函数进行创建和修改),它可以是函数中的Java对象这样的简单变量,也可以是与函数相关的Key/Value状态。

7. 调度
在JobManager端,会接收到Client提交的JobGraph形式的Flink Job,JobManager会将一个JobGraph转换映射为一个ExecutionGraph,ExecutionGraph是JobGraph的并行表示,也就是实际JobManager调度一个Job在TaskManager上运行的逻辑视图。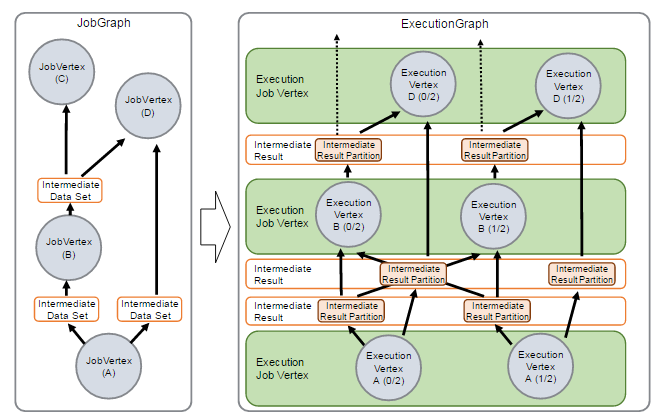
物理上进行调度,基于资源的分配与使用的一个例子:
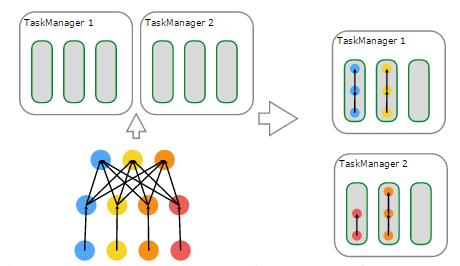
- 左上子图:有2个TaskManager,每个TaskManager有3个Task Slot
- 左下子图:一个Flink Job,逻辑上包含了1个data source、1个MapFunction、1个ReduceFunction,对应一个JobGraph
- 左下子图:用户提交的Flink Job对各个Operator进行的配置——data source的并行度设置为4,MapFunction的并行度也为4,ReduceFunction的并行度为3,在JobManager端对应于ExecutionGraph
- 右上子图:TaskManager 1上,有2个并行的ExecutionVertex组成的DAG图,它们各占用一个Task Slot
- 右下子图:TaskManager 2上,也有2个并行的ExecutionVertex组成的DAG图,它们也各占用一个Task Slot
- 在2个TaskManager上运行的4个Execution是并行执行的
8. 迭代
机器学习和图计算应用,都会使用到迭代计算,Flink通过在迭代Operator中定义Step函数来实现迭代算法,这种迭代算法包括Iterate和Delta Iterate两种类型。
Iterate
Iterate Operator是一种简单的迭代形式:每一轮迭代,Step函数的输入或者是输入的整个数据集,或者是上一轮迭代的结果,通过该轮迭代计算出下一轮计算所需要的输入(也称为Next Partial Solution),满足迭代的终止条件后,会输出最终迭代结果。

流程伪代码:
IterationState state = getInitialState();while (!terminationCriterion()) { state = step(state);}setFinalState(state);Delta Iterate
Delta Iterate Operator实现了增量迭代。

流程伪代码:
IterationState workset = getInitialState();IterationState solution = getInitialSolution();while (!terminationCriterion()) { (delta, workset) = step(workset, solution); solution.update(delta)}setFinalState(solution);最小值传播:

9. Back Pressure监控
流处理系统中,当下游Operator处理速度跟不上的情况,如果下游Operator能够将自己处理状态传播给上游Operator,使得上游Operator处理速度慢下来就会缓解上述问题,比如通过告警的方式通知现有流处理系统存在的问题。
Flink Web界面上提供了对运行Job的Backpressure行为的监控,它通过使用Sampling线程对正在运行的Task进行堆栈跟踪采样来实现。
默认情况下,JobManager会每间隔50ms触发对一个Job的每个Task依次进行100次堆栈跟踪调用,过计算得到一个比值,例如,radio=0.01,表示100次中仅有1次方法调用阻塞。Flink目前定义了如下Backpressure状态:
OK: 0 <= Ratio <= 0.10
LOW: 0.10 < Ratio <= 0.5
HIGH: 0.5 < Ratio <= 1
三、库
1. Table
Flink的Table API实现了使用类SQL进行流和批处理。
详情参考:https://ci.apache.org/projects/flink/flink-docs-release-1.2/dev/table_api.html
2. CEP
Flink的CEP(Complex Event Processing)支持在流中发现复杂的事件模式,快速筛选用户感兴趣的数据。
详情参考:https://ci.apache.org/projects/flink/flink-docs-release-1.2/concepts/programming-model.html#next-steps
3. Gelly
Gelly是Flink提供的图计算API,提供了简化开发和构建图计算分析应用的接口。
详情参考:https://ci.apache.org/projects/flink/flink-docs-release-1.2/dev/libs/gelly/index.html
4. FlinkML
FlinkML是Flink提供的机器学习库,提供了可扩展的机器学习算法、简洁的API和工具简化机器学习系统的开发。
详情参考:https://ci.apache.org/projects/flink/flink-docs-release-1.2/dev/libs/ml/index.html
四、部署
当Flink系统启动时,首先启动JobManager和一至多个TaskManager。JobManager负责协调Flink系统,TaskManager则是执行并行程序的worker。当系统以本地形式启动时,一个JobManager和一个TaskManager会启动在同一个JVM中。
当一个程序被提交后,系统会创建一个Client来进行预处理,将程序转变成一个并行数据流的形式,交给JobManager和TaskManager执行。

1. 启动测试
编译flink,本地启动。
$ java -versionjava version "1.8.0_111"$ git clone https://github.com/apache/flink.git$ git checkout release-1.1.4 -b release-1.1.4$ cd flink$ mvn clean package -DskipTests$ cd flink-dist/target/flink-1.1.4-bin/flink-1.1.4$ ./bin/start-local.sh
编写本地流处理demo。
SocketWindowWordCount.java
public class SocketWindowWordCount { public static void main(String[] args) throws Exception { // the port to connect to final int port; try { final ParameterTool params = ParameterTool.fromArgs(args); port = params.getInt("port"); } catch (Exception e) { System.err.println("No port specified. Please run 'SocketWindowWordCount --port <port>'"); return; } // get the execution environment final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // get input data by connecting to the socket DataStream<String> text = env.socketTextStream("localhost", port, "\n"); // parse the data, group it, window it, and aggregate the counts DataStream<WordWithCount> windowCounts = text .flatMap(new FlatMapFunction<String, WordWithCount>() { public void flatMap(String value, Collector<WordWithCount> out) { for (String word : value.split("\\s")) { out.collect(new WordWithCount(word, 1L)); } } }) .keyBy("word") .timeWindow(Time.seconds(5), Time.seconds(1)) .reduce(new ReduceFunction<WordWithCount>() { public WordWithCount reduce(WordWithCount a, WordWithCount b) { return new WordWithCount(a.word, a.count + b.count); } }); // print the results with a single thread, rather than in parallel windowCounts.print().setParallelism(1); env.execute("Socket Window WordCount"); } // Data type for words with count public static class WordWithCount { public String word; public long count; public WordWithCount() {} public WordWithCount(String word, long count) { this.word = word; this.count = count; } @Override public String toString() { return word + " : " + count; } }}pom.xml
<!-- Use this dependency if you are using the DataStream API --><dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.10</artifactId> <version>1.1.4</version></dependency><!-- Use this dependency if you are using the DataSet API --><dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.1.4</version></dependency><dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_2.10</artifactId> <version>1.1.4</version></dependency>执行mvn构建。
$ mvn clean install$ ls target/flink-demo-1.0-SNAPSHOT.jar开启9000端口,用于输入数据:
$ nc -l 9000提交flink任务:
$ ./bin/flink run -c com.demo.florian.WordCount $DEMO_DIR/target/flink-demo-1.0-SNAPSHOT.jar --port 9000在nc里输入数据后,查看执行结果:
$ tail -f log/flink-*-jobmanager-*.out查看flink web页面:localhost:8081
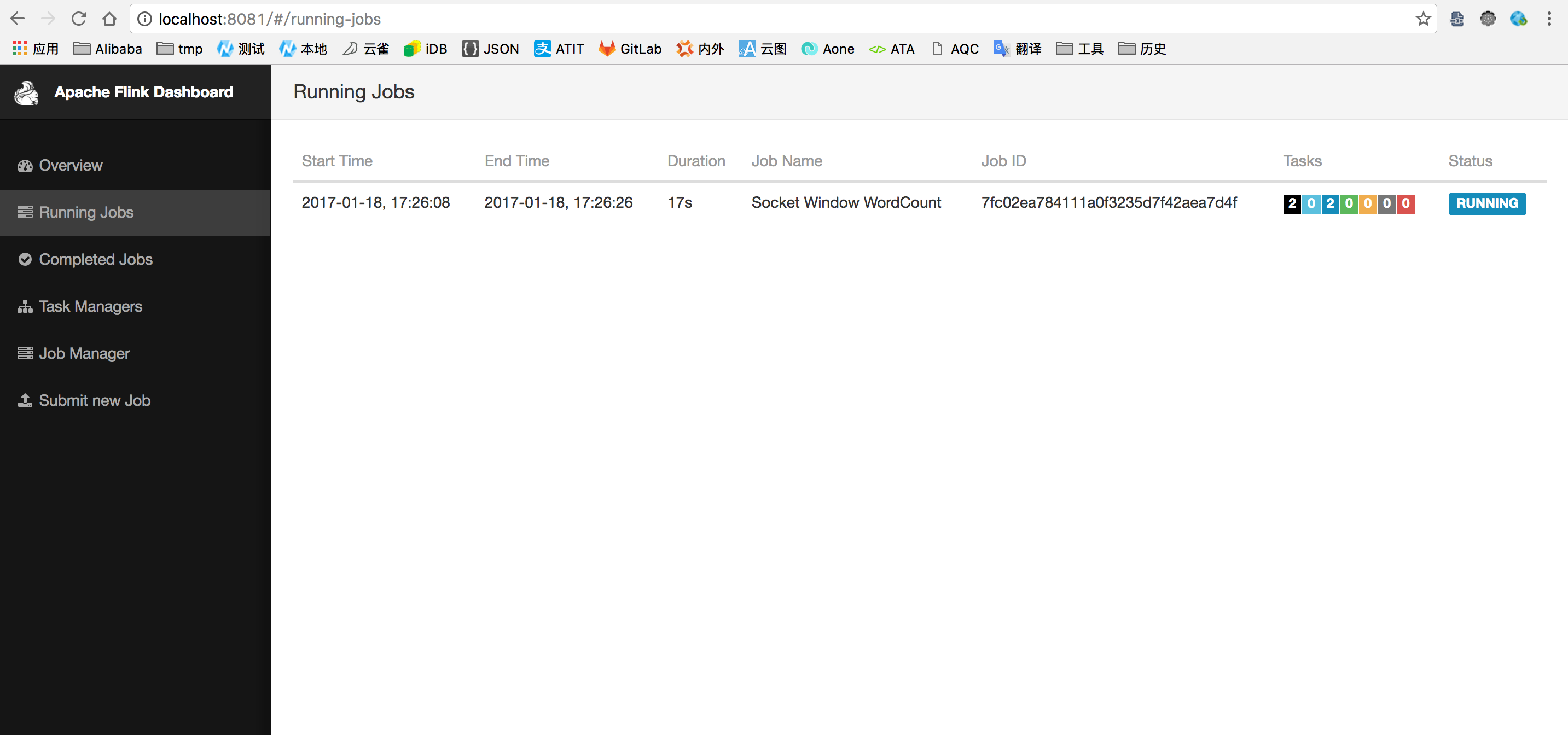
2. 代码结构
Flink系统核心可分为多个子项目。分割项目旨在减少开发Flink程序需要的依赖数量,并对测试和开发小组件提供便捷。
Flink当前还包括以下子项目:
- Flink-dist:distribution项目。它定义了如何将编译后的代码、脚本和其他资源整合到最终可用的目录结构中。
- Flink-quick-start:有关quickstart和教程的脚本、maven原型和示例程序
- flink-contrib:一系列有用户开发的早起版本和有用的工具的项目。后期的代码主要由外部贡献者继续维护,被flink-contirb接受的代码的要求低于其他项目的要求。
3. Flink On YARN
Flink在YARN集群上运行时:Flink YARN Client负责与YARN RM通信协商资源请求,Flink JobManager和Flink TaskManager分别申请到Container去运行各自的进程。
YARN AM与Flink JobManager在同一个Container中,这样AM可以知道Flink JobManager的地址,从而AM可以申请Container去启动Flink TaskManager。待Flink成功运行在YARN集群上,Flink YARN Client就可以提交Flink Job到Flink JobManager,并进行后续的映射、调度和计算处理。

- 设置Hadoop环境变量
$ export HADOOP_CONF_DIR=/etc/hadoop/conf- 以集群模式提交任务,每次都会新建flink集群
$ ./bin/flink run -m yarn-cluster -c com.demo.florian.WordCount $DEMO_DIR/target/flink-demo-1.0-SNAPSHOT.jar- 启动共享flink集群,提交任务
$ ./bin/yarn-session.sh -n 4 -jm 1024 -tm 4096 -d$ ./bin/flink run -c com.demo.florian.WordCount $DEMO_DIR/target/flink-demo-1.0.SNAPSHOT.jar我们是否还需要另外一个新的数据处理引擎?当我第一次听到Flink的时候这是我是非常怀疑的。在大数据领域,现在已经不缺少数据处理框架了,但是没有一个框架能够完全满足不同的处理需求。自从Apache Spark出现后,貌似已经成为当今把大部分的问题解决得最好的框架了,所以我对另外一款解决类似问题的框架持有很强烈的怀疑态度。
不过因为好奇,我花费了数个星期在尝试了解Flink。一开始仔细看了Flink的几个例子,感觉和Spark非常类似,心理就倾向于认为Flink又是一个模仿Spark的框架。但是随着了解的深入,这些API体现了一些Flink的新奇的思路,这些思路还是和Spark有着比较明显的区别的。我对这些思路有些着迷了,所以花费了更多的时间在这上面。
Flink中的很多思路,例如内存管理,dataset API都已经出现在Spark中并且已经证明 这些思路是非常靠谱的。所以,深入了解Flink也许可以帮助我们分布式数据处理的未来之路是怎样的。
在后面的文章里,我会把自己作为一个Spark开发者对Flink的第一感受写出来。因为我已经在Spark上干了2年多了,但是只在Flink上接触了2到3周,所以必然存在一些bias,所以大家也带着怀疑和批判的角度来看这篇文章吧。

文章目录
- 1 Apache Flink是什么
- 2 Apache Spark vs Apache Flink
- 2.1 1、抽象 Abstraction
- 2.2 2、内存管理
- 2.3 3、语言实现
- 2.4 4、API
- 2.5 5、Steaming
- 2.6 6、SQL interface
- 2.7 7、外部数据源的整合
- 2.8 8、Iterative processing
- 2.9 9、Stream as platform vs Batch as Platform
- 3 结论
Apache Flink是什么
Flink是一款新的大数据处理引擎,目标是统一不同来源的数据处理。这个目标看起来和Spark和类似。没错,Flink也在尝试解决Spark在解决的问题。这两套系统都在尝试建立一个统一的平台可以运行批量,流式,交互式,图处理,机器学习等应用。所以,Flink和Spark的目标差别并不大,他们最主要的区别在于实现的细节,后面我会重点从不同的角度对比这两者。
Apache Spark vs Apache Flink
1、抽象 Abstraction
Spark中,对于批处理我们有RDD,对于流式,我们有DStream,不过内部实际还是RDD.所以所有的数据表示本质上还是RDD抽象。后面我会重点从不同的角度对比这两者。在Flink中,对于批处理有DataSet,对于流式我们有DataStreams。看起来和Spark类似,他们的不同点在于:
(一)DataSet在运行时是表现为运行计划(runtime plans)的
在Spark中,RDD在运行时是表现为java objects的。通过引入Tungsten,这块有了些许的改变。但是在Flink中是被表现为logical plan(逻辑计划)的,听起来很熟悉?没错,就是类似于Spark中的dataframes。所以在Flink中你使用的类Dataframe api是被作为第一优先级来优化的。但是相对来说在Spark RDD中就没有了这块的优化了。
Flink中的Dataset,对标Spark中的Dataframe,在运行前会经过优化。在Spark 1.6,dataset API已经被引入Spark了,也许最终会取代RDD 抽象。
(二)Dataset和DataStream是独立的API
在Spark中,所有不同的API,例如DStream,Dataframe都是基于RDD抽象的。但是在Flink中,Dataset和DataStream是同一个公用的引擎之上两个独立的抽象。所以你不能把这两者的行为合并在一起操作,当然,Flink社区目前在朝这个方向努力(https://issues.apache.org/jira/browse/Flink-2320),但是目前还不能轻易断言最后的结果。
2、内存管理
一直到1.5版本,Spark都是试用java的内存管理来做数据缓存,明显很容易导致OOM或者gc。所以从1.5开始,Spark开始转向精确的控制内存的使用,这就是tungsten项目了。
而Flink从第一天开始就坚持自己控制内存试用。这个也是启发了Spark走这条路的原因之一。Flink除了把数据存在自己管理的内存以外,还直接操作二进制数据。在Spark中,从1.5开始,所有的dataframe操作都是直接作用在tungsten的二进制数据上。
3、语言实现
Spark是用scala来实现的,它提供了Java,Python和R的编程接口。Flink是java实现的,当然同样提供了Scala API
所以从语言的角度来看,Spark要更丰富一些。因为我已经转移到scala很久了,所以不太清楚这两者的java api实现情况。
4、API
Spark和Flink都在模仿scala的collection API.所以从表面看起来,两者都很类似。下面是分别用RDD和DataSet API实现的word count
// Spark wordcountobjectWordCount { defmain(args:Array[String]) { valenv=newSparkContext("local","wordCount") valdata=List("hi","how are you","hi") valdataSet=env.parallelize(data) valwords=dataSet.flatMap(value=> value.split("\\s+")) valmappedWords=words.map(value=> (value,1)) valsum=mappedWords.reduceByKey(_+_) println(sum.collect()) }}// Flink wordcountobjectWordCount {defmain(args:Array[String]) { valenv=ExecutionEnvironment.getExecutionEnvironment valdata=List("hi","how are you","hi") valdataSet=env.fromCollection(data) valwords=dataSet.flatMap(value=> value.split("\\s+")) valmappedWords=words.map(value=> (value,1)) valgrouped=mappedWords.groupBy(0) valsum=grouped.sum(1) println(sum.collect()) }}不知道是偶然还是故意的,API都长得很像,这样很方便开发者从一个引擎切换到另外一个引擎。我感觉以后这种Collection API会成为写data pipeline的标配。
5、Steaming
Spark把streaming看成是更快的批处理,而Flink把批处理看成streaming的special case。这里面的思路决定了各自的方向,其中两者的差异点有如下这些:
实时 vs 近实时的角度
Flink提供了基于每个事件的流式处理机制,所以可以被认为是一个真正的流式计算。它非常像storm的model。
而Spark,不是基于事件的粒度,而是用小批量来模拟流式,也就是多个事件的集合。所以Spark被认为是近实时的处理系统。
Spark streaming 是更快的批处理,而Flink Batch是有限数据的流式计算。
虽然大部分应用对准实时是可以接受的,但是也还是有很多应用需要event level的流式计算。这些应用更愿意选择storm而非Spark streaming,现在,Flink也许是一个更好的选择。
流式计算和批处理计算的表示
Spark对于批处理和流式计算,都是用的相同的抽象:RDD,这样很方便这两种计算合并起来表示。而Flink这两者分为了DataSet和DataStream,相比Spark,这个设计算是一个糟糕的设计。
对 windowing 的支持
因为Spark的小批量机制,Spark对于windowing的支持非常有限。只能基于process time,且只能对batches来做window。而Flink对window的支持非常到位,且Flink对windowing API的支持是相当给力的,允许基于process time,data time,record 来做windowing。我不太确定Spark是否能引入这些API,不过到目前为止,Flink的windowing支持是要比Spark好的。Steaming这部分Flink胜
6、SQL interface
目前Spark-sql是Spark里面最活跃的组件之一,Spark提供了类似Hive的sql和Dataframe这种DSL来查询结构化数据,API很成熟,在流式计算中使用很广,预计在流式计算中也会发展得很快。至于Flink,到目前为止,Flink Table API只支持类似DataFrame这种DSL,并且还是处于beta状态,社区有计划增加SQL 的interface,但是目前还不确定什么时候才能在框架中用上。所以这个部分,Spark胜出。
7、外部数据源的整合
Spark的数据源 API是整个框架中最好的,支持的数据源包括NoSql db,parquet,ORC等,并且支持一些高级的操作,例如predicate push down。Flink目前还依赖map/reduce InputFormat来做数据源聚合。这一场Spark胜
8、Iterative processing
Spark对机器学习的支持较好,因为可以在Spark中利用内存cache来加速机器学习算法。
但是大部分机器学习算法其实是一个有环的数据流,但是在Spark中,实际是用无环图来表示的,一般的分布式处理引擎都是不鼓励试用有环图的。但是Flink这里又有点不一样,Flink支持在runtime中的有环数据流,这样表示机器学习算法更有效而且更有效率。这一点Flink胜出。
9、Stream as platform vs Batch as Platform
Spark诞生在Map/Reduce的时代,数据都是以文件的形式保存在磁盘中,这样非常方便做容错处理。Flink把纯流式数据计算引入大数据时代,无疑给业界带来了一股清新的空气。这个idea非常类似akka-streams这种。成熟度目前的确有一部分吃螃蟹的用户已经在生产环境中使用Flink了,不过从我的眼光来看,Flink还在发展中,还需要时间来成熟。
结论
目前Spark相比Flink是一个更为成熟的计算框架,但是Flink的很多思路很不错,Spark社区也意识到了这一点,并且逐渐在采用Flink中的好的设计思路,所以学习一下Flink能让你了解一下Streaming这方面的更迷人的思路。
Spark是一种快速、通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集合,划分到集群的各个节点上,可以被并行操作。用户也可以让Spark保留一个RDD在内存中,使其能在并行操作中被有效的重复使用。Flink是可扩展的批处理和流式数据处理的数据处理平台,设计思想主要来源于Hadoop、MPP数据库、流式计算系统等,支持增量迭代计算。
原理
Spark 1.4特点如下所示。
- Spark为应用提供了REST API来获取各种信息,包括jobs、stages、tasks、storage info等。
- Spark Streaming增加了UI,可以方便用户查看各种状态,另外与Kafka的融合也更加深度,加强了对Kinesis的支持。
- Spark SQL(DataFrame)添加ORCFile类型支持,另外还支持所有的Hive metastore。
- Spark ML/MLlib的ML pipelines愈加成熟,提供了更多的算法和工具。
- Tungsten项目的持续优化,特别是内存管理、代码生成、垃圾回收等方面都有很多改进。
- SparkR发布,更友好的R语法支持。

图1 Spark架构图

图2 Flink架构图

图3 Spark生态系统图
Flink 0.9特点如下所示。
- DataSet API 支持Java、Scala和Python。
- DataStream API支持Java and Scala。
- Table API支持类SQL。
- 有机器学习和图处理(Gelly)的各种库。
- 有自动优化迭代的功能,如有增量迭代。
- 支持高效序列化和反序列化,非常便利。
- 与Hadoop兼容性很好。

图4 Flink生态系统图
分析对比
性能对比
首先它们都可以基于内存计算框架进行实时计算,所以都拥有非常好的计算性能。经过测试,Flink计算性能上略好。
测试环境:
- CPU:7000个;
- 内存:单机128GB;
- 版本:Hadoop 2.3.0,Spark 1.4,Flink 0.9
- 数据:800MB,8GB,8TB;
- 算法:K-means:以空间中K个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
- 迭代:K=10,3组数据

图5 迭代次数(纵坐标是秒,横坐标是次数)
总结:Spark和Flink全部都运行在Hadoop YARN上,性能为Flink > Spark > Hadoop(MR),迭代次数越多越明显,性能上,Flink优于Spark和Hadoop最主要的原因是Flink支持增量迭代,具有对迭代自动优化的功能。
流式计算比较
它们都支持流式计算,Flink是一行一行处理,而Spark是基于数据片集合(RDD)进行小批量处理,所以Spark在流式处理方面,不可避免增加一些延时。Flink的流式计算跟Storm性能差不多,支持毫秒级计算,而Spark则只能支持秒级计算。
与Hadoop兼容
计算的资源调度都支持YARN的方式
数据存取都支持HDFS、HBase等数据源。
Flink对Hadoop有着更好的兼容,如可以支持原生HBase的TableMapper和TableReducer,唯一不足是现在只支持老版本的MapReduce方法,新版本的MapReduce方法无法得到支持,Spark则不支持TableMapper和TableReducer这些方法。
SQL支持
都支持,Spark对SQL的支持比Flink支持的范围要大一些,另外Spark支持对SQL的优化,而Flink支持主要是对API级的优化。
计算迭代
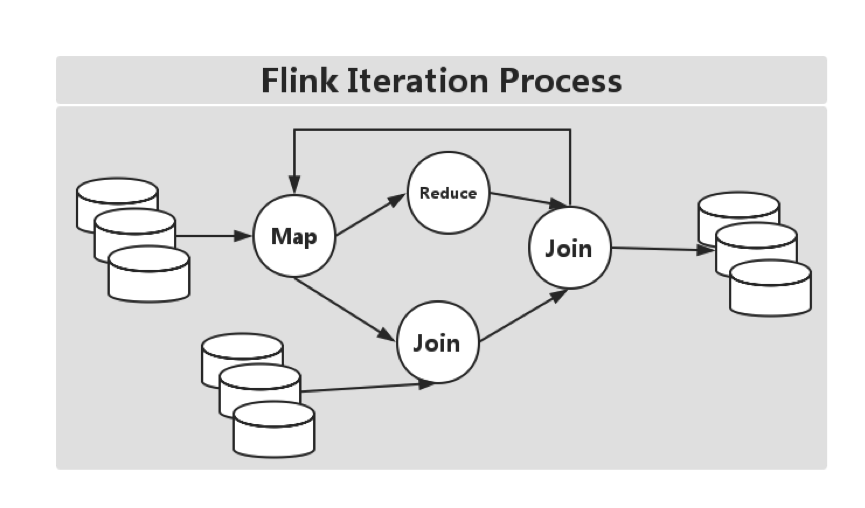
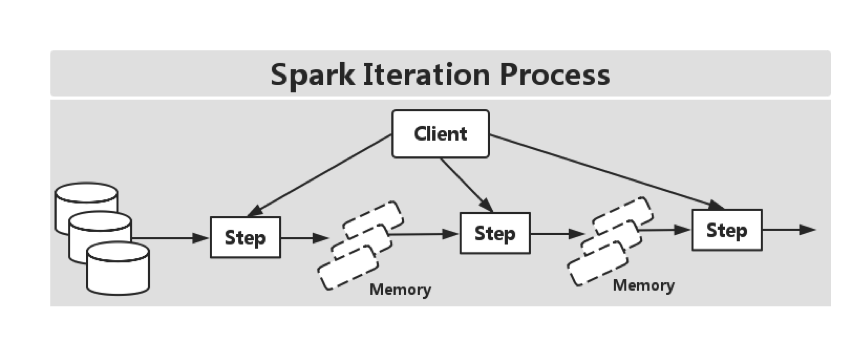
delta-iterations,这是Flink特有的,在迭代中可以显著减少计算,图6、图7、图8是Hadoop(MR)、Spark和Flink的迭代流程。

图6 Hadoop(MR)迭代流程

图7 Spark迭代流程

图8 Flink迭代流程
Flink自动优化迭代程序具体流程如图9所示。

图9 Flink自动优化迭代程序具体流程
社区支持
Spark社区活跃度比Flink高很多。
总结
Spark和Flink都支持实时计算,且都可基于内存计算。Spark后面最重要的核心组件仍然是Spark SQL,而在未来几次发布中,除了性能上更加优化外(包括代码生成和快速Join操作),还要提供对SQL语句的扩展和更好地集成。至于Flink,其对于流式计算和迭代计算支持力度将会更加增强。无论是Spark、还是Flink的发展重点,将是数据科学和平台API化,除了传统的统计算法外,还包括学习算法,同时使其生态系统越来越完善。
storm、spark streaming、flink都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,允许你在运行数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行,都提供了简单的API来简化底层实现的复杂程度。
Apache Storm
在Storm中,先要设计一个用于实时计算的图状结构,我们称之为拓扑(topology)。这个拓扑将会被提交给集群,由集群中的主控节点(master node)分发代码,将任务分配给工作节点(worker node)执行。一个拓扑中包括spout和bolt两种角色,其中spout发送消息,负责将数据流以tuple元组的形式发送出去;而bolt则负责转换这些数据流,在bolt中可以完成计算、过滤等操作,bolt自身也可以随机将数据发送给其他bolt。由spout发射出的tuple是不可变数组,对应着固定的键值对。

Apache Spark
Spark Streaming是核心Spark API的一个扩展,它并不会像Storm那样一次一个地处理数据流,而是在处理前按时间间隔预先将其切分为一段一段的批处理作业。Spark针对持续性数据流的抽象称为DStream(DiscretizedStream),一个DStream是一个微批处理(micro-batching)的RDD(弹性分布式数据集);而RDD则是一种分布式数据集,能够以两种方式并行运作,分别是任意函数和滑动窗口数据的转换。

Apache Flink
Flink 是一个针对流数据和批数据的分布式处理引擎。它主要是由 Java 代码实现。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。再换句话说,Flink 会把所有任务当成流来处理,这也是其最大的特点。Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。并且 Flink 可以定制化内存管理。在这点,如果要对比 Flink 和 Spark 的话,Flink 并没有将内存完全交给应用层。这也是为什么 Spark 相对于 Flink,更容易出现 OOM 的原因(out of memory)。就框架本身与应用场景来说,Flink 更相似与 Storm。
Flink 的架构图。

对比图:

(比较源自大牛的PPT,现在新版storm有很多改进,比如自动反压机制之类,另外storm trident API也能提供有状态操作与批处理等)
怎么选择
如果你想要的是一个允许增量计算的高速事件处理系统,Storm会是最佳选择。
如果你必须有状态的计算,恰好一次的递送,并且不介意高延迟的话,那么可以考虑Spark Streaming,特别如果你还计划图形操作、机器学习或者访问SQL的话,Apache Spark的stack允许你将一些library与数据流相结合(Spark SQL,Mllib,GraphX),它们会提供便捷的一体化编程模型。尤其是数据流算法(例如:K均值流媒体)允许Spark实时决策的促进。Flink支持增量迭代,具有对迭代自动优化的功能,在迭代式数据处理上,比Spark更突出,Flink基于每个事件一行一行地流式处理,真正的流式计算,流式计算跟Storm性能差不多,支持毫秒级计算,而Spark则只能支持秒级计算。
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为他们它们所提供的SLA是完全不相同的:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。例如,实现批处理的开源方案有MapReduce、Tez、Crunch、Spark,实现流处理的开源方案有Samza、Storm。 Flink在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。基于同一个Flink运行时(Flink Runtime),分别提供了流处理和批处理API,而这两种API也是实现上层面向流处理、批处理类型应用框架的基础。
Flink 是一款新的大数据处理引擎,目标是统一不同来源的数据处理。这个目标看起来和 Spark 和类似。这两套系统都在尝试建立一个统一的平台可以运行批量,流式,交互式,图处理,机器学习等应用。所以,Flink 和 Spark 的目标差异并不大,他们最主要的区别在于实现的细节。
下面附上 Flink 技术栈的一个总览,如下图所示:
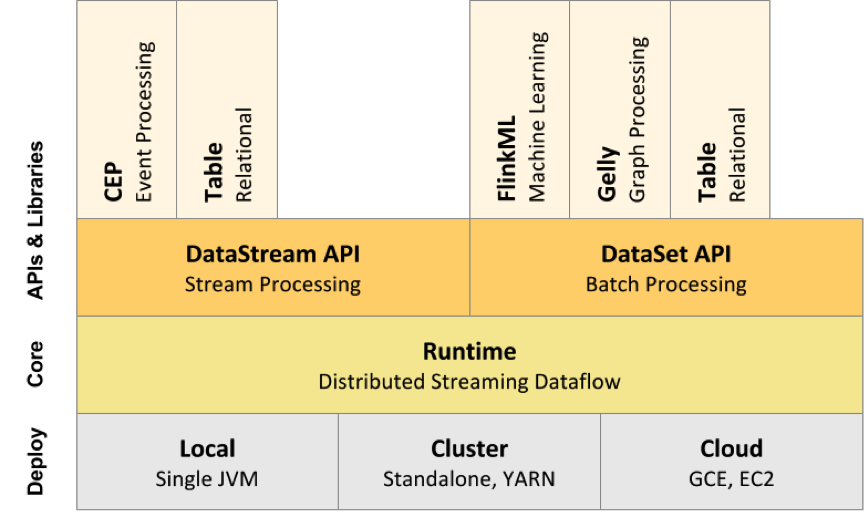
2.2 Compare
了解 Flink 的作用和优缺点,需要有一个参照物,这里,笔者以它与 Spark 来对比阐述。从抽象层,内存管理,语言实现,以及 API 和 SQL 等方面来赘述。
2.2.1 Abstraction
接触过 Spark 的同学,应该比较熟悉,在处理批处理任务,可以使用 RDD,而对于流处理,可以使用 Streaming,然其世纪还是 RDD,所以本质上还是 RDD 抽象而来。但是,在 Flink 中,批处理用 DataSet,对于流处理,有 DataStreams。思想类似,但却有所不同:其一,DataSet 在运行时表现为 Runtime Plans,而在 Spark 中,RDD 在运行时表现为 Java Objects。在 Flink 中有 Logical Plan ,这和 Spark 中的 DataFrames 类似。因而,在 Flink 中,若是使用这类 API ,会被优先来优化(即:自动优化迭代)。如下图所示:
然而,在 Spark 中,RDD 就没有这块的相关优化,如下图所示::
另外,DataSet 和 DataStream 是相对独立的 API,在 Spark 中,所有不同的 API,比如 Streaming,DataFrame 都是基于 RDD 抽象的。然而在 Flink 中,DataSet 和 DataStream 是同一个公用引擎之上的两个独立的抽象。所以,不能把这两者的行为合并在一起操作,目前官方正在处理这种问题,详见[FLINK-2320]
2.2.2 Memory
在之前的版本(1.5以前),Spark 延用 Java 的内存管理来做数据缓存,这样很容易导致 OOM 或者 GC。之后,Spark 开始转向另外更加友好和精准的控制内存,即:Tungsten 项目。然而,对于 Flink 来说,从一开始就坚持使用自己控制内存。Flink 除把数据存在自己管理的内存之外,还直接操作二进制数据。在 Spark 1.5之后的版本开始,所有的 DataFrame 操作都是直接作用于 Tungsten 的二进制数据上。
PS:Tungsten 项目将是 Spark 自诞生以来内核级别的最大改动,以大幅度提升 Spark 应用程序的内存和 CPU 利用率为目标,旨在最大程度上利用硬件性能。该项目包括了三个方面的改进:
- 内存管理和二进制处理:更加明确的管理内存,消除 JVM 对象模型和垃圾回收开销。
- 缓存友好计算:使用算法和数据结构来实现内存分级结构。
- 代码生成:使用代码生成来利用新型编译器和 CPU。
2.2.3 Program
Spark 使用 Scala 来实现的,它提供了 Java,Python 以及 R 语言的编程接口。而对于 Flink 来说,它是使用 Java 实现的,提供 Scala 编程 API。从编程语言的角度来看,Spark 略显丰富一些。
2.2.4 API
Spark 和 Flink 两者都倾向于使用 Scala 来实现对应的业务。对比两者的 WordCount 示例,很类似。如下所示,分别为 RDD 和 DataSet API 的示例代码:
- RDD
// Spark WordCountobject WordCount { def main(args: Array[String]) { val env = new SparkContext("local","WordCount") val data = List("hi","spark cluster","hi","spark") val dataSet = env.parallelize(data) val words = dataSet.flatMap(value => value.split("\\s+")) val mappedWords = words.map(value => (value,1)) val sum = mappedWords.reduceByKey(_+_) println(sum.collect()) }}- DataSet
// Flink WordCountobject WordCount { def main(args: Array[String]) { val env = ExecutionEnvironment.getExecutionEnvironment val data = List("hello","flink cluster","hello") val dataSet = env.fromCollection(data) val words = dataSet.flatMap(value => value.split("\\s+")) val mappedWords = words.map(value => (value,1)) val grouped = mappedWords.groupBy(0) val sum = grouped.sum(1) println(sum.collect()) }}对于 Streaming,Spark 把它看成更快的批处理,而 Flink 把批处理看成 Streaming 的特殊例子,差异如下:其一,在实时计算问题上,Flink 提供了基于每个事件的流式处理机制,所以它可以被认为是一个真正意义上的流式计算,类似于 Storm 的计算模型。而对于 Spark 来说,不是基于事件粒度的,而是用小批量来模拟流式,也就是多个事件的集合。所以,Spark 被认为是一个接近实时的处理系统。虽然,大部分应用实时是可以接受的,但对于很多应用需要基于事件级别的流式计算。因而,会选择 Storm 而不是 Spark Streaming,现在,Flink 也许是一个不错的选择。
2.2.5 SQL
目前,Spark SQL 是其组件中较为活跃的一部分,它提供了类似于 Hive SQL 来查询结构化数据,API 依然很成熟。对于 Flink 来说,截至到目前 1.0 版本,只支持 Flink Table API,官方在 Flink 1.1 版本中会添加 SQL 的接口支持。[Flink 1.1 SQL 详情计划]
3.Features
Flink 包含一下特性:
- 高吞吐 & 低延时
- 支持 Event Time & 乱序事件
- 状态计算的 Exactly-Once 语义
- 高度灵活的流式窗口
- 带反压的连续流模型
- 容错性
- 流处理和批处理共用一个引擎
- 内存管理
- 迭代 & 增量迭代
- 程序调优
- 流处理应用
- 批处理应用
- 类库生态
- 广泛集成
3.1 高吞吐 & 低延时
Flink 的流处理引擎只需要很少配置就能实现高吞吐率和低延迟。下图展示了一个分布式计数的任务的性能,包括了流数据 shuffle 过程。

3.2 支持 Event Time & 乱序事件
Flink 支持了流处理和 Event Time 语义的窗口机制。Event time 使得计算乱序到达的事件或可能延迟到达的事件更加简单。如下图所示:

3.3 状态计算的 exactly-once 语义
流程序可以在计算过程中维护自定义状态。Flink 的 checkpointing 机制保证了即时在故障发生下也能保障状态的 exactly once 语义。
3.4 高度灵活的流式窗口
Flink 支持在时间窗口,统计窗口,session 窗口,以及数据驱动的窗口,窗口可以通过灵活的触发条件来定制,以支持复杂的流计算模式。
3.5 带反压的连续流模型
数据流应用执行的是不间断的(常驻)operators。Flink streaming 在运行时有着天然的流控:慢的数据 sink 节点会反压(backpressure)快的数据源(sources)。
3.6 容错性
Flink 的容错机制是基于 Chandy-Lamport distributed snapshots 来实现的。这种机制是非常轻量级的,允许系统拥有高吞吐率的同时还能提供强一致性的保障。
3.7 流处理和批处理共用一个引擎
Flink 为流处理和批处理应用公用一个通用的引擎。批处理应用可以以一种特殊的流处理应用高效地运行。如下图所示:

3.8 内存管理
Flink 在 JVM 中实现了自己的内存管理。应用可以超出主内存的大小限制,并且承受更少的垃圾收集的开销。
3.9 迭代和增量迭代
Flink 具有迭代计算的专门支持(比如在机器学习和图计算中)。增量迭代可以利用依赖计算来更快地收敛。如下图所示:
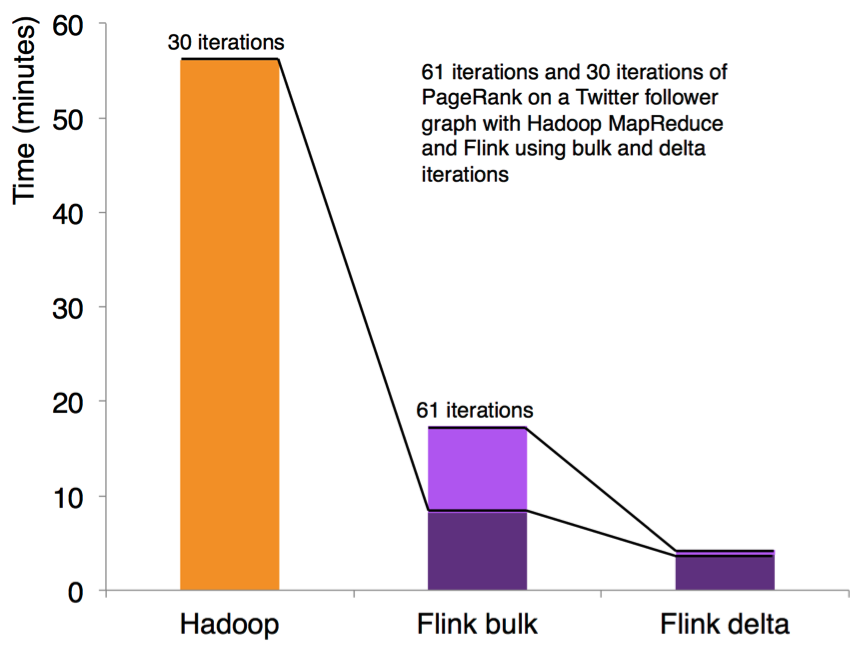
3.10 程序调优
批处理程序会自动地优化一些场景,比如避免一些昂贵的操作(如 shuffles 和 sorts),还有缓存一些中间数据。
3.11 流处理应用
DataStream API 支持了数据流上的函数式转换,可以使用自定义的状态和灵活的窗口。下面示例展示了如何以滑动窗口的方式统计文本数据流中单词出现的次数。
case class Word(word: String, freq: Long)val texts: DataStream[String] = ...val counts = text .flatMap { line => line.split("\\W+") } .map { token => Word(token, 1) } .keyBy("word") .timeWindow(Time.seconds(5), Time.seconds(1)) .sum("freq")3.12 批处理应用
Flink 的 DataSet API 可以使你用 Java 或 Scala 写出漂亮的、类型安全的、可维护的代码。它支持广泛的数据类型,不仅仅是 key/value 对,以及丰富的 operators。下面示例展示了图计算中 PageRank 算法的一个核心循环。
case class Page(pageId: Long, rank: Double)case class Adjacency(id: Long, neighbors: Array[Long])val result = initialRanks.iterate(30) { pages => pages.join(adjacency).where("pageId").equalTo("pageId") { (page, adj, out : Collector[Page]) => { out.collect(Page(page.id, 0.15 / numPages)) for (n <- adj.neighbors) { out.collect(Page(n, 0.85*page.rank/adj.neighbors.length)) } } } .groupBy("pageId").sum("rank")}3.13 类库生态
Flink 栈中提供了很多高级 API 和满足不同场景的类库:机器学习、图分析、关系式数据处理。当前类库还在 beta 状态,并且在大力发展。
3.14 广泛集成
Flink 与开源大数据处理生态系统中的许多项目都有集成。Flink 可以运行在 YARN 上,与 HDFS 协同工作,从 Kafka 中读取流数据,可以执行 Hadoop 程序代码,可以连接多种数据存储系统。如下图所示:

4.总结
以上,便是对 Flink 做一个简要的剖析认识,至于如何使用 Flink,以及其编译,安装,部署,运行等流程,较为简单,这里就不多做赘述了,大家可以在 Flink 的官网,阅读其 QuickStart 即可,[访问地址]。
- Flink架构、原理与部署测试
- Flink架构、原理与部署测试
- Flink架构、原理与部署测试
- Flink架构、原理与部署测试
- Flink架构、原理与部署测试
- Flink架构、原理与部署测试
- Flink架构、原理与部署测试
- Flink架构、原理与部署测试
- Flink架构、原理与部署测试
- Flink架构、原理与部署测试
- Flink 原理与实现:架构和拓扑概览
- Flink 原理与实现:架构和拓扑概览
- Flink原理与实现:架构和拓扑概览
- 详解kafka架构原理与安装部署
- Flink 原理与实现:内存管理
- Flink 原理与实现:Window 机制
- Flink 原理与实现:Window 机制
- Flink 原理与实现:如何生成 StreamGraph
- vim vimdiff diff 使用及命令
- 共同学习Java源代码-多线程与并发-Executor、ExecutorService接口
- Java基础之 反射
- ViewPager控件详解
- python一行写不下的问题
- Flink架构、原理与部署测试
- 使用openssl库进行DES加密
- googlezxing二维码生成jar文件
- 乐观锁和悲观锁的区别
- javaWeb判断浏览器种类
- 后Hadoop时代的大数据技术思考:数据即服务
- Java isfile()与exists()的区别
- AI与区块链的融合会给人类带来什么
- iOS Extension Category Protrol 例子理解


