AI根据视频画面自动配音 ,真假难辨 !(附数据集)
来源:互联网 发布:黑马程序员就业班 编辑:程序博客网 时间:2024/04/27 15:27
点击有惊喜
先来做个“真假美猴王”的游戏。
你将看到两段画面相同的视频,请判断哪段来自视频原声,哪段是AI根据视频画面配上的假声?

莫非两个都是真的?不可能,答案文末揭晓。(还有更多真假难辨的视频原声和配音大对比)
真假难辨,简直让人怀疑耳朵。模型合成的假音效,什么时候都这么逼真了?一切还得从这个自动为自然环境下的视频配音的项目说起。

视听关联
看闪电,知雷声。
对人类来说,声音和视觉通常会打包出现传递信息。就像一个孩子看到闪电会下意识捂住耳朵,看到沸腾的水会想起水汽呼呼的声音。
在论文(Visual to Sound: Generating Natural Sound for Videos in the Wild)中,北卡罗来纳大学的博士生Yipin Zhou,其导师Tamara L. Berg联合Adobe公司的Zhaowen Wang、Chen Fang和Trung Bui三人,想做出一个计算模型来学习视觉和声音间的关系,减少繁琐的音频编辑流程。

论文一作Yipin Zhou
要做出这样一个模型,那第一步肯定是找出一个合适的数据集来训练。
这个数据集可没有那么好找。
加工数据集
研究人员掐指一算,觉得AudioSet不错。

这是今年3月谷歌开放的一个大规模的音频数据集,包含了632个类别的音频及2084320条人工标记的音频,每段音频长度均为10秒。人与动物、乐器与音乐流派、日常环境的声音均覆盖在数据集内。
数据集代码地址:
https://github.com/audioset/ontology
但由于AudioSet中很多的音频与视频的关联松散,目标声音可能被音乐等其他声音覆盖,这些噪音会干扰模型学习正确的声音和图像间的映射(mapping),因此也不是很理想。研究人员先清理了数据的一个子集,让它们适应生成任务。
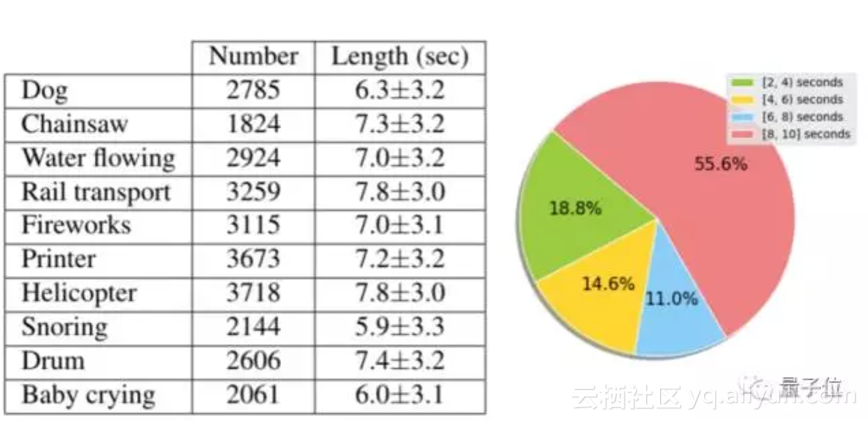
研究人员从AudioSet中选择10个类别进行进一步的清理,分别为婴儿啼哭、人打鼾、狗、流水、烟火、铁路运输、打印机、打鼓、直升机和电锯。每个类别中包含1500-3000个随机抽取的视频。

其中4个类别的视频帧及相应波形。图像边界颜色与波形上的标记标记一致,表示整个视频中当前帧的位置
之后,研究人员用亚马逊众包平台Mechanical Turk(AMT)清理数据。值得一提的是,李飞飞在建立ImageNet数据集时,也是借助这个可以把任务分发给全世界坐在电脑前的人的平台做起来的。
在这个任务中,研究人员借助AMT上兼职的力量验证在图像和音频形态下,视频片段中关注的物体或动作是否存在。如果在视听两种环境下都存在,则认为它是一个噪音较少的可用视频。为了尽可能保留更多数据,研究人员将每段视频分割成两秒钟的短视频,分别标注标签。
这样一来,图像和音频模式上共标注了132209个片段,每个都被3个兼职做了标记,并从原始数据中删除了34392个片段。研究人员在合并相邻的短片段后,总共得到了28109个筛选后的视频。这些视频平均长度为7秒,总长度为55小时。
下图左表显示了视频数量和每个类别的平均长度,而饼图展示了长度的分布。由图中可见大多数视频的长度超过8秒。
点击有惊喜

- AI根据视频画面自动配音 ,真假难辨 !(附数据集)
- AI根据视频画面自动配音 ,真假难辨 !(附数据集)
- 骗过70%的人!这个AI能自动给视频配音,真假难辨(不服来试)
- 如何进行制作消音视频(视频配音)
- 阿联酋选出首位 AI 国务部长(附Youtube视频)
- 一文带你入门视频目标分割(附数据集)
- 根据覆盖物自动缩放画面比例
- Facebook Yann LeCun一小时演讲: AI 研究的下一站是无监督学习(附完整视频)
- 吴恩达最新满满干货告诉你,怎样才能成为真正的AI公司(附视频)
- 吴恩达成立新公司,签约富士康,专注制造业AI变革(附视频)
- 吴恩达成立新公司,签约富士康,专注制造业AI变革(附视频)
- 无题 (配音乐)
- 配音
- 独家 | 教你用Scrapy建立你自己的数据集(附视频)
- 手把手:教你用Scrapy建立你自己的数据集(附视频)
- 手把手:教你用Scrapy建立你自己的数据集(附视频)
- TechCrunch炉边对话吴恩达:不回应70hr招聘要求,看好小公司AI驱动(附视频)
- bittiger视频(AI简历)
- python_subprocess
- POJ 1493 Machined Surfaces G++
- DIRECTORY_SEPARATOR获取当前系统在目录分隔符
- Redis-Cluster集群整合SpringCache
- ofstream和ifstream详细用法
- AI根据视频画面自动配音 ,真假难辨 !(附数据集)
- 数据结构笔记3---树
- 基于SnapDragonBoard410cNTP的理解
- 移动端CSS常用小结
- IP解析成地址 确定省市
- MySQL select * 和把所有的字段都列出来,哪个效率更高?
- Choose library dependency(选择库的依赖关系)目前搜索不出来任何内容,之前可以搜出来的。
- JavaEE总结
- 牛客算法--第五章


