FasterRCNN算法:RPN层的深入理解
来源:互联网 发布:程序员过关 编辑:程序博客网 时间:2024/05/23 18:30
RPN的结构是在已有的网路结构(例如VGG)的最后一层上添加如下图的新层。以VGG为例,下图中每部分的具体结构为:
1. conv feature map:在VGG的conv5_3后新添加的一个512x3x3的卷基层。
2.K anchor boxes:
在每个sliding window的点上的初始化的参考区域。每个sliding window的点上取得anchor boxes都一样。只要知道sliding window的点的坐标,就可以计算出每个anchor box的具体坐标。faster-RCNN中 k = 9,先确定一个base anchor,大小为16x16,保持面积不变使其长宽比为(0.5,1,2),再对这三个不同长宽比的anchor放大(8,16,32)个尺度,一共得到9个anchors。
3. intermediate layer:
作者代码中并没有这个输出256d特征的中间层,直接通过1x1的卷积获得2K Scores 和 4k cordinates。作者在文中解释为用全卷积方式替代全连接。
4. 2K Scores
对于每个anchor,用了softmax layer的方式,会或得两个置信度。作者在文中说也可以用sigmoid方式获得一维是正例的置信度。
5:4k cordinates

对于一幅大小为600*800的图片,经过基础网特征map为38×50,则总的anchor的个数为38×50×9;
Anchors:字面上可以理解为锚点,位于之前提到的n*n的sliding window的中心处.对于一个sliding window,我们可以同时预测多个proposal,假定有k个.k个proposal即k个reference boxes,每一个reference box又可以用一个scale,一个aspect_ratio和sliding window中的锚点唯一确定.所以,我们在后面说一个anchor,你就理解成一个anchor box 或一个reference box.
作者在论文中定义k=9,即3种scales和3种aspect_ratio确定出当前sliding window位置处对应的9个reference boxes, 4*k个reg-layer的输出和2*k个cls-layer的score输出.对于一幅W*H的feature map,对应W*H*k个锚点.所有的锚点都具有尺度不变性.
Loss functions:
在计算Loss值之前,作者设置了anchors的标定方法.正样本标定规则:
1) 如果Anchor对应的reference box与ground truth的IoU值最大,标记为正样本;
2) 如果Anchor对应的reference box与ground truth的IoU>0.7,标记为正样本.事实上,采用第2个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的Anchor对应的reference box与groud truth的IoU不大于0.7,可以采用第一种规则生成.
3) 负样本标定规则:如果Anchor对应的reference box与ground truth的IoU<0.3,标记为负样本.
4) 剩下的既不是正样本也不是负样本,不用于最终训练.
5) 训练RPN的Loss是有classification loss (即softmax loss)和regression loss (即L1 loss)按一定比重组成的.
计算softmax loss需要的是anchors对应的groundtruth标定结果和预测结果,计算regression loss需要三组信息:
i. 预测框,即RPN网络预测出的proposal的中心位置坐标x,y和宽高w,h;
ii. 锚点reference box:
之前的9个锚点对应9个不同scale和aspect_ratio的reference boxes,每一个reference boxes都有一个中心点位置坐标x_a,y_a和宽高w_a,h_a;
iii. ground truth:标定的框也对应一个中心点位置坐标x*,y*和宽高w*,h*.因此计算regression loss和总Loss方式如下:

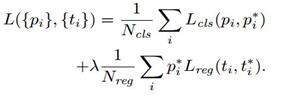
RPN训练设置:
(1)在训练RPN时,一个Mini-batch是由一幅图像中任意选取的256个proposal组成的,其中正负样本的比例为1:1.
(2)如果正样本不足128,则多用一些负样本以满足有256个Proposal可以用于训练,反之亦然.
(3)训练RPN时,与VGG共有的层参数可以直接拷贝经ImageNet训练得到的模型中的参数;剩下没有的层参数用标准差=0.01的高斯分布初始化.
RoI Pooling理解:
ROI pooling layer实际上是SPP-NET的一个精简版,SPP-NET对每个proposal使用了不同大小的金字塔映射,而ROI pooling layer只需要下采样到一个7x7的特征图.对于VGG16网络conv5_3有512个特征图,这样所有region proposal对应了一个7*7*512维度的特征向量作为全连接层的输入.
RoI Pooling就是实现从原图区域映射到conv5区域最后pooling到固定大小的功能
- FasterRCNN算法:RPN层的深入理解
- RPN算法
- faster-rcnn中,对RPN的理解
- 对Region Proposal Network,RPN的理解
- Faster RCNN 中 RPN 的理解
- 对全连接层的深入理解
- service层深入理解
- EM算法的深入理解
- Faster-Rcnn中RPN(Region Proposal Network)的理解
- Shunting+yard -- RPN 算法
- 中缀表达式转后缀式的RPN算法
- 基于逆波兰RPN算法的计算器实现
- 三层的深入理解(BLL层的职责)
- 深入理解快速排序算法的稳定性
- 一致性Hash算法的深入理解
- 对prime算法的深入理解
- fasterrcnn训练自己的数据
- 关于FasterRCNN的思考问题解决
- Spring DAO(1):基础 & 数据源配置
- STM32固件库
- Windows7 系统上配置caffe GPU/CPU 的深度学习框架
- 系统吞吐量、TPS(QPS)、用户并发量、性能测试概念和公式
- tensorflow.slice_input_producer
- FasterRCNN算法:RPN层的深入理解
- 军事理论课答案(西安交大版)
- sklearn CountVectorizer\TfidfVectorizer\TfidfTransformer函数详解
- pytorch使用(四)训练网络
- 搞定字体样式、背景的工具类(shape、selector、drawable)
- 物联网之无线网络技术(Cellular,LPWAN,LAN)
- Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser
- iOS MRC情况下重写setter getter方法
- 设计模式


