写入修复(二)
来源:互联网 发布:界面编程 编辑:程序博客网 时间:2024/05/20 14:19
Hinted Handoff:在写入路径中修复
有时,数据写入时节点变为无响应状态。无响应的原因是硬件问题、网络问题、重载节点或长时间垃圾回收(GC)暂停。通过design,hinted handoff允许Cassandra继续执行相同数量的写入,即使群集以降低的容量运行。
在故障检测器将节点标记为关闭之后,如果在cassandra.yaml文件中启用了 提示的切换,则协调器会在一段时间内保存丢失的写入。在Cassandra 3.0及更高版本中,提示存储在本地提示中在每个节点上改进重播。该提示包括关闭的节点的目标ID,作为数据的时间UUID的提示ID,标识Cassandra版本的消息ID以及作为blob的数据本身。提示每隔10秒刷新一次,减少提示的陈旧程度。当八卦发现一个节点已经恢复在线状态时,协调器重新播放每个剩下的提示,将数据写入新返回的节点,然后删除提示文件。如果某个节点停机的时间超过了max_hint_window_in_ms(默认为3小时),则协调器停止写入新的提示。
协调员还会每隔十分钟检查一次提示,说明在停机期间超时的写入操作太短,以便故障检测器通过八卦通知。如果副本节点过载或不可用,并且故障检测器尚未将节点标记为关闭,则在由write_request_timeout_in_ms(默认为10秒)触发的超时之后,期望对该节点的大部分或全部写入失败。协调器返回一个TimeOutException异常,写入将失败,但是一个提示将被存储。如果多个节点同时出现短暂中断,则可能会在协调器上建立大量的内存压力。协调者跟踪当前正在写入的提示数量,如果数量增加太多,协调者拒绝写入并抛出 OverloadedException 例外。
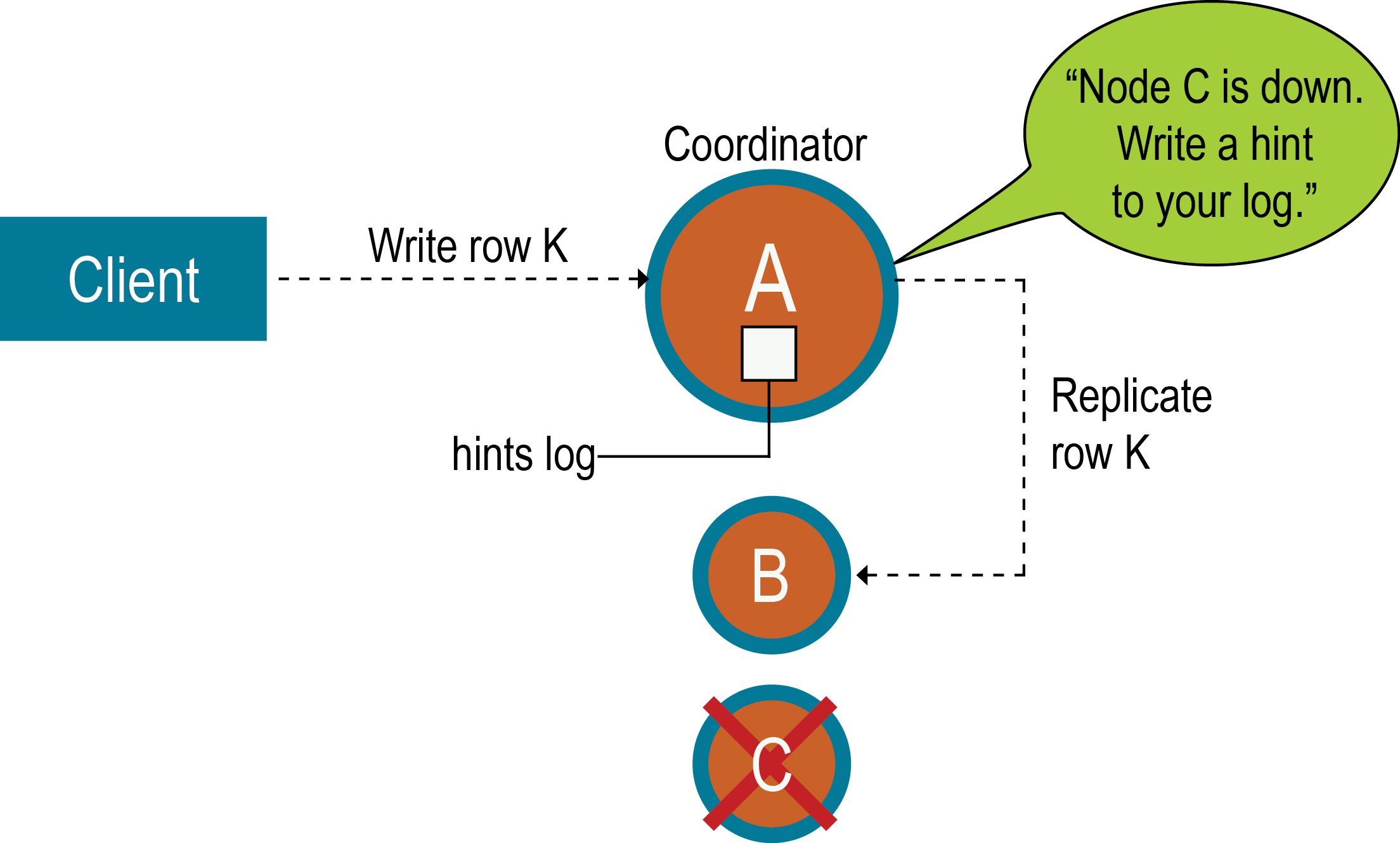
写入请求的一致性级别影响是否写入提示,并且写入请求随后失败。如果群集由两个节点A和B组成,复制因子为1,则每行仅存储在一个节点上。假设节点A是协调者,但在写入行K之前下降,其一致性级别为1。在这种情况下,不能满足指定的一致性级别,并且由于节点A是协调者,因此不能存储提示。节点B不能写数据,因为它没有收到作为协调者的数据,也没有存储提示。协调器检查已启动的副本数量,如果无法满足客户机指定的一致性级别,将不会尝试写入提示。一个暗示的切换失败发生,并将返回一个UnavailableException例外。写请求失败,提示不被写入。
通常,建议在集群中拥有足够的节点,并且复制因子足以避免写请求失败。例如,考虑一个由三个节点A,B和C组成的集群,复制因子为2.当将行K写入协调程序(在此情况下为节点A)时,即使节点C处于关闭状态,可以满足ONE或QUORUM的一致性级别。为什么?节点A和节点B都将接收数据,所以满足一致性级别要求。节点C存储提示,节点C出现时写入提示。同时,协调员可以确认写入成功。
对于希望Cassandra在所有常规副本关闭时都能接受写入并且不能满足一致性级别ONE的应用程序,Cassandra提供了一致性级别ANY。任何保证在适当的副本目标变为可用并且接收提示重播之后写入是持久的和可读的。
死亡的节点可能存储了未传递的提示,因为任何节点都可以成为协调者。死亡节点上的数据也会在长时间停机后过时。如果一个节点长时间关闭,应该进行手动修复。
乍一看,似乎暗示的切换消除了手动修复的需要,但这不是真的,因为硬件故障是不可避免的,并具有以下分支:
丢失必要的历史数据,告诉群集的其余部分究竟是什么数据丢失。
失败的提示 - 尚未重播的失败节点协调的请求。
通过停用节点或使用nodetool removenode命令从集群中删除节点时,Cassandra会自动删除针对不再存在的节点的提示。卡桑德拉也删除掉桌子的提示。
有关提示存储的更多解释,请参阅“3.0中的新增内容:改进的提示存储和交付”或讨论基本内容的旧博客,“ 现代提示”切换。
- 写入修复(二)
- MBR损坏修复(二)
- 热修复探究(二)
- Android热修复学习(二)
- 热修复技术初探(二)
- log4j(二)将日志写入数据库
- mysql-cluster数据自动修复(节点崩溃期间写入其他节点数据)
- windows下exfat无法写入修复
- hbase修复--数据无法写入到表中。
- 脱壳步骤二-修复
- Android热补丁动态修复技术(二):实战!CLASS_ISPREVERIFIED问题!(热修复技术)
- win2003 修复安装之:遭遇黑色34分钟(二)
- 【转】硬盘损坏和修复等相关知识(二)
- Grub 之常用命令和Windows引导修复(二)
- iOS之 动态热修复技术JSPatch(二)
- Android热补丁动态修复技术(二):实践
- Android热修复(Hot Fix)案例全剖析(二)
- Android热修复与插件化(二)虚拟机详解
- 17.12.17日报
- Linux 下统计网卡的流量
- Redis dump.rdb appendonly.aof 文件路径修改
- elasticsearch分布式检索
- Tomcat使用基础
- 写入修复(二)
- 设计模式:模板方法模式
- Spring MVC全局处理Exception
- ioc
- STL学习笔记-模板知识
- Disruptor 2.0更新摘要
- 傅里叶分析之掐死教程(完整版)
- Java集合框架(一)--构图
- 【swing】JLabel详解以及使用示例


