【Spark】sortBy[T]和sortByKey[T]排序详解
来源:互联网 发布:java 运行环境变量 编辑:程序博客网 时间:2024/05/15 08:48
问题导读:
1. 排序算子是如何做排序的?
2. 完整的排序流程是?
解决方案:
1 前言
在前面一系列博客中,特别在Shuffle博客系列中,曾描述过在生成ShuffleWrite的文件的时候,对每个partition会先进行排序并spill到文件中,最后合并成ShuffleWrite的文件,也就是每个Partition里的内容已经进行了排序,在最后的action操作的时候需要对每个executor生成的shuffle文件相同的Partition进行合并,完成Action的操作。
排序算子和常见的reduce算子算法有何区别?
常见的一些聚合、reduce算子,不需要排序
2 排序
下面是一个常见的排序的小例子:
核心代码:OrderedRDDFunctions.scala
会很奇怪么?RDD里面并没有sortByKey的方法?在这里和前面博客里提到的PairRDDFunctions一样,隐式转换:
调用的是OrderedRDDFunctions.scala里的方法
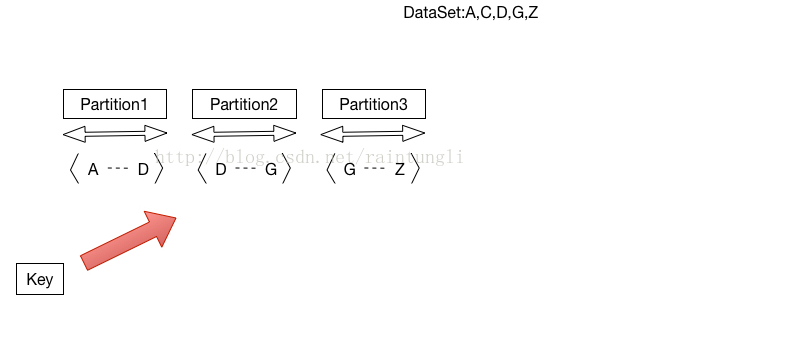
对Partition采用了范围分配的策略,为何要使用范围分配的策略?
2.1 分配Range
Range的分配不合理,会影响数据的不均衡,导致executor在做同Partition排序的时候会不均衡,并行计算的整体性能往往会被单个最糟糕的运行节点所拖累,如果提高运算的速度,需要考虑数据分配的均衡性。
2.1.1 每个区块采样大小
获取所有的key,依据所有的Key制定区间,这显然是不明智的,后果变成一个全量数据的排序。我们可以采用部分采样的策略,基于采样数据进行区间划分,首先我们需要评估一个简单的采样大小的阈值。
Partitioner.scala rangeBounds
代码如下:
partitions: 参数在指定sortByKey的时候设置的区块大小:3
rdd.partitions: 指的是在数据的分区块大小:2
每个区块需要采样的数量是通过几个固定参数来计算
2.1.2 Sketch采样(蓄水池采样法)
mapPartitionsWithIndex, collection 这些都是RDD ,都是需要在提交job进行运算的,也就是采样的过程中,是通过executor执行了一次job
函数reservoirSampleAndCount采样
返回的结果里包含了总数据集,区块编号,区块的数量,每个区块的采样集
2.1.3 重新采样
为了避免某些区块的数据量过大,设置了一个阈值:
阈值=采样数除于总数据量,当某个区块的数据量*阈值大于每个区的采样率的时候,认为这个区块的采样率是不足的,需要重新采样
2.1.4 采样集key的权重
我们在前面对每个区进行了相同数量的采样(不包含重新采样),但是每个区的数量有可能是不均衡的,为了避免不均衡性需要对每个区采样的key进行权重设置,尽量分配高权重给数据量多的区
权重因子:
n 是区的数据数量
sample 是采样的数量
这里权重的最小值是1,因为采样的数量肯定是小于等于数据
当数据量大于采样数量的时候,每个区的采样数量是相同的,那么意味着区的数据量越大,该区块的key的权重也就越大
2.1.5 分配每个区块的range
样本已经采集好了,现在需要对依据样本进行区块的range进行分配
2.2 ShuffleWriter
在以前的博客里介绍了SortShuffleWrite,在sortByKey的排序情况下使用了BypassMergeSortShuffleWriter,把焦点聚焦到key如何分配到Partitioner和每个Partition的文件将会如何写入key,value生成Shuffle文件,在这两点上BypassMergeSortShuffleWriter将明显的不同于SortShuffleWrite
2.2.1 分配key到Partition
在函数调用了partitioner.getPartition方法,还是回到RangePartitioner类中
2.2.2 生成shuffle文件
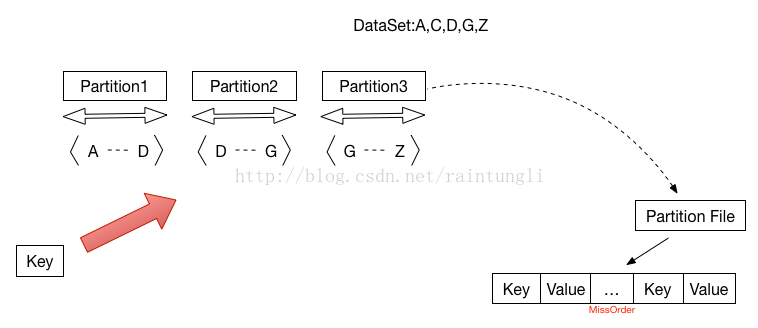
注意:在这里并没有象SortShuffleWrite 对每个Partition进行排序,Spill 文件,最后合并文件,而是直接写到了Partition文件中。
2.3 Shuffle Read读取Shuffle文件
在BlockStoreShuffleReader的read函数里
ExternalSorter.insertAll函数
ExternalSorter函数,这个函数在前面的这篇博客里介绍的比较清楚,这里使用了buffer结构体
在reduceByKey的这些算子相同的Key是需要合并的,所以需要使用Map结构处理相同的Key的值的合并问题,而对排序来说,并不需要相同的值合并,使用Array结构就可以了。
注:在Spark上实现Map、Array都使用了数组的结构,并没有用链表结构
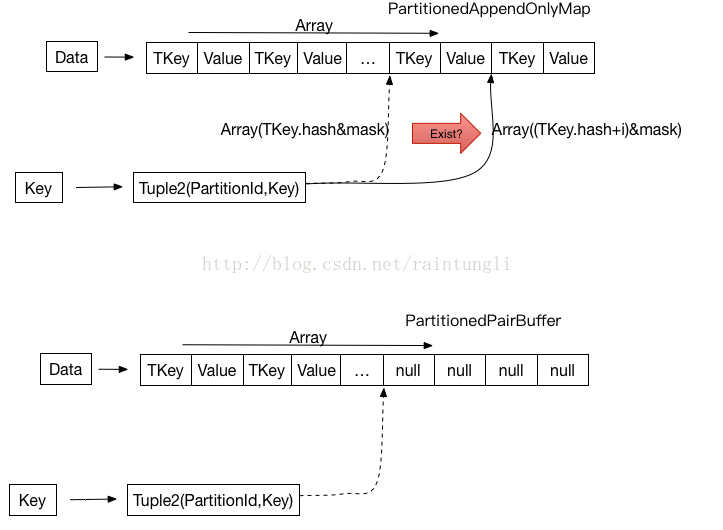
在上图的PartitionPairBuffer结构中,有以下几点要注意:
插入KV结构的时候,不进行排序,也就是在处理相同的Partition的时候直接读取插入Array
会存在当内存不够Spill到磁盘的情况,关于Spill请具体参考博客链接
2.3.1 排序
当ExternalSorter.insertAll函数完成后,才会构建一个排序的迭代器
这里分成两种情况:
还在内存里没有Spill到文件中去,这时候构建一个内存里的PartitionedDestructiveSortedIterator迭代器,在迭代器中已经排序好了PartitionPairBuffer里的内容
Spill到文件里的,文件里的已经排好序了,需要对内存里的PartitionPairBuffer进行排序(和前面一种情况相同的处理),最后对文件和内存进行外排序(外排序可参考博客)
2.4 最后的归并
在Driver端Dag-scheduler-event-loop 线程中会处理每个executor返回的结果(刚才Partition排序后的结果)
通过方法taskSucceeded的方法进行不同的Partition的合并
实际上是调用了resultHandler方法,我们来看看resultHandler是怎样定义的
在runJob的方法里
就是:
构建了一个数组result,将每个Partition的数值保存到result的数组里
result[0]=partition[0] =array(tuple<k,v>,tuple<k,v>.....)
什么时候对所有的Partition最后合并呢?
来看RDD的collect算子
runJob返回的是result的数组,每个Partition是管理不同的范围,最后的合并只要简单的将不同的Partition合并就可以了
3. 排序完整的流程
转自:csdn
作者:raintungli
1. 排序算子是如何做排序的?
2. 完整的排序流程是?
解决方案:
1 前言
在前面一系列博客中,特别在Shuffle博客系列中,曾描述过在生成ShuffleWrite的文件的时候,对每个partition会先进行排序并spill到文件中,最后合并成ShuffleWrite的文件,也就是每个Partition里的内容已经进行了排序,在最后的action操作的时候需要对每个executor生成的shuffle文件相同的Partition进行合并,完成Action的操作。
排序算子和常见的reduce算子算法有何区别?
常见的一些聚合、reduce算子,不需要排序
- 将相同的hashcode分配到同一个partition,哪怕是不同的executor
- 在做最后的合并的时候,只需要合并不同的executor里相同的partition就可以了
- 对每个partition进行排序,考虑内存因数,解决相同的Partition多文件合并的问题,使用外排序进行相同的key合并
2 排序
下面是一个常见的排序的小例子:
[Scala] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
packagespark.sortimportorg.apache.spark.SparkConfimportorg.apache.spark.SparkContextobjectsortsample { defmain(args:Array[String]) { valconf=newSparkConf().setAppName("sortsample") valsc=newSparkContext(conf) varpairs=sc.parallelize(Array(("a",0),("b",0),("c",3),("d",6),("e",0),("f",0),("g",3),("h",6)),2); pairs.sortByKey(true,3).collect().foreach(println); }}核心代码:OrderedRDDFunctions.scala
会很奇怪么?RDD里面并没有sortByKey的方法?在这里和前面博客里提到的PairRDDFunctions一样,隐式转换:
[Scala] 纯文本查看 复制代码
1
2
3
4
implicitdefrddToOrderedRDDFunctions[K :Ordering:ClassTag, V:ClassTag](rdd:RDD[(K, V)]) :OrderedRDDFunctions[K, V, (K, V)] ={ newOrderedRDDFunctions[K, V, (K, V)](rdd)}调用的是OrderedRDDFunctions.scala里的方法
[Scala] 纯文本查看 复制代码
1
2
3
4
5
6
7
defsortByKey(ascending:Boolean=true, numPartitions:Int=self.partitions.length) :RDD[(K, V)] =self.withScope { valpart=newRangePartitioner(numPartitions, self, ascending) newShuffledRDD[K, V, V](self, part) .setKeyOrdering(if(ascending) ordering elseordering.reverse) }对Partition采用了范围分配的策略,为何要使用范围分配的策略?
- 对其它非排序类型的算子,使用散列算法,只要保证相同的key是分配在相同的partition就可以了,并不会影响相同的key的合并,计算。
- 对排序来说,如果只是保证相同的key在相同的Partition并不足够,最后还是需要合并所有的Partition进行排序合并,如果这发生在Driver端做这件事,将会非常可怕,那么我们可以做一些策略改变,制定一些Range,使排序相近的key分配到同一个Range上,在把Range扩大化,比如:一个Partition管理一个Range
2.1 分配Range
Range的分配不合理,会影响数据的不均衡,导致executor在做同Partition排序的时候会不均衡,并行计算的整体性能往往会被单个最糟糕的运行节点所拖累,如果提高运算的速度,需要考虑数据分配的均衡性。
2.1.1 每个区块采样大小
获取所有的key,依据所有的Key制定区间,这显然是不明智的,后果变成一个全量数据的排序。我们可以采用部分采样的策略,基于采样数据进行区间划分,首先我们需要评估一个简单的采样大小的阈值。
Partitioner.scala rangeBounds
代码如下:
[Scala] 纯文本查看 复制代码
1
2
3
4
valsampleSize=math.min(20.0* partitions, 1e6) // Assume the input partitions are roughly balanced and over-sample a little bit. valsampleSizePerPartition=math.ceil(3.0* sampleSize / rdd.partitions.length).toInt val(numItems, sketched) =RangePartitioner.sketch(rdd.map(_._1), sampleSizePerPartition)partitions: 参数在指定sortByKey的时候设置的区块大小:3
[Scala] 纯文本查看 复制代码
1
pairs.sortByKey(true,3)rdd.partitions: 指的是在数据的分区块大小:2
[Scala] 纯文本查看 复制代码
1
sc.parallelize(Array(("a",0),("b",0),("c",3),("d",6),("e",0),("f",0),("g",3),("h",6)),2)每个区块需要采样的数量是通过几个固定参数来计算
[Scala] 纯文本查看 复制代码
1
valsampleSizePerPartition=math.ceil(3.0* sampleSize / rdd.partitions.length).toInt2.1.2 Sketch采样(蓄水池采样法)
[Scala] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
defsketch[K:ClassTag]( rdd:RDD[K], sampleSizePerPartition:Int):(Long, Array[(Int, Long, Array[K])]) ={ valshift=rdd.id // val classTagK = classTag[K] // to avoid serializing the entire partitioner object valsketched=rdd.mapPartitionsWithIndex { (idx, iter) => valseed=byteswap32(idx ^ (shift << 16)) val(sample, n) =SamplingUtils.reservoirSampleAndCount( iter, sampleSizePerPartition, seed) Iterator((idx, n, sample)) }.collect() valnumItems=sketched.map(_._2).sum (numItems, sketched)}mapPartitionsWithIndex, collection 这些都是RDD ,都是需要在提交job进行运算的,也就是采样的过程中,是通过executor执行了一次job
[Scala] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
defreservoirSampleAndCount[T:ClassTag]( input:Iterator[T], k:Int, seed:Long=Random.nextLong()) :(Array[T], Long) ={ valreservoir=newArray[T](k) // Put the first k elements in the reservoir. vari=0 while(i < k && input.hasNext) { valitem=input.next() reservoir(i)=item i +=1 } // If we have consumed all the elements, return them. Otherwise do the replacement. if(i < k) { // If input size < k, trim the array to return only an array of input size. valtrimReservoir=newArray[T](i) System.arraycopy(reservoir,0, trimReservoir, 0, i) (trimReservoir, i) }else{ // If input size > k, continue the sampling process. varl=i.toLong valrand=newXORShiftRandom(seed) while(input.hasNext) { valitem=input.next() l +=1 // There are k elements in the reservoir, and the l-th element has been // consumed. It should be chosen with probability k/l. The expression // below is a random long chosen uniformly from [0,l) valreplacementIndex=(rand.nextDouble() * l).toLong if(replacementIndex < k) { reservoir(replacementIndex.toInt)=item } } (reservoir, l) }}函数reservoirSampleAndCount采样
- 当数据小于要采样的集合的时候,可以使用数据为样本
- 当数据集合超过需要采样数目的时候会继续遍历整个数据集合,通过随机数进行位置的随机替换,保证采样数据的随机性
返回的结果里包含了总数据集,区块编号,区块的数量,每个区块的采样集
2.1.3 重新采样
为了避免某些区块的数据量过大,设置了一个阈值:
[Scala] 纯文本查看 复制代码
1
valfraction=math.min(sampleSize / math.max(numItems, 1L),1.0)阈值=采样数除于总数据量,当某个区块的数据量*阈值大于每个区的采样率的时候,认为这个区块的采样率是不足的,需要重新采样
[Scala] 纯文本查看 复制代码
1
2
3
4
5
valimbalanced=newPartitionPruningRDD(rdd.map(_._1), imbalancedPartitions.contains) valseed=byteswap32(-rdd.id - 1) valreSampled=imbalanced.sample(withReplacement=false, fraction, seed).collect() valweight=(1.0/ fraction).toFloat candidates ++=reSampled.map(x=> (x, weight))2.1.4 采样集key的权重
我们在前面对每个区进行了相同数量的采样(不包含重新采样),但是每个区的数量有可能是不均衡的,为了避免不均衡性需要对每个区采样的key进行权重设置,尽量分配高权重给数据量多的区
权重因子:
[Scala] 纯文本查看 复制代码
1
valweight=(n.toDouble / sample.length).toFloatn 是区的数据数量
sample 是采样的数量
这里权重的最小值是1,因为采样的数量肯定是小于等于数据
当数据量大于采样数量的时候,每个区的采样数量是相同的,那么意味着区的数据量越大,该区块的key的权重也就越大
2.1.5 分配每个区块的range
样本已经采集好了,现在需要对依据样本进行区块的range进行分配
- 先对样本进行排序
- 依据每个样本的权重计算每个区块平均所分配的权重
- 最后通过每个区分配的权重按照顺序来决定获取哪些样本用作range,一个区分配一个样本区间
[Scala] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
defdetermineBounds[K:Ordering:ClassTag]( candidates:ArrayBuffer[(K, Float)], partitions:Int):Array[K]={ valordering=implicitly[Ordering[K]] valordered=candidates.sortBy(_._1) valnumCandidates=ordered.size valsumWeights=ordered.map(_._2.toDouble).sum valstep=sumWeights / partitions varcumWeight=0.0 vartarget=step valbounds=ArrayBuffer.empty[K] vari=0 varj=0 varpreviousBound=Option.empty[K] while((i < numCandidates) && (j < partitions - 1)) { val(key, weight) =ordered(i) cumWeight +=weight if(cumWeight >=target) { // Skip duplicate values. if(previousBound.isEmpty || ordering.gt(key, previousBound.get)) { bounds +=key target +=step j +=1 previousBound=Some(key) } } i +=1 } bounds.toArray}2.2 ShuffleWriter
在以前的博客里介绍了SortShuffleWrite,在sortByKey的排序情况下使用了BypassMergeSortShuffleWriter,把焦点聚焦到key如何分配到Partitioner和每个Partition的文件将会如何写入key,value生成Shuffle文件,在这两点上BypassMergeSortShuffleWriter将明显的不同于SortShuffleWrite
[Scala] 纯文本查看 复制代码
1
2
3
4
5
while(records.hasNext()) { finalProduct2<K, V> record =records.next(); finalK key =record._1(); partitionWriters[partitioner.getPartition(key)].write(key, record._2()); }2.2.1 分配key到Partition
在函数调用了partitioner.getPartition方法,还是回到RangePartitioner类中
[Scala] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
defgetPartition(key:Any):Int={ valk=key.asInstanceOf[K] varpartition=0 if(rangeBounds.length <=128) { // If we have less than 128 partitions naive search while(partition < rangeBounds.length && ordering.gt(k, rangeBounds(partition))) { partition +=1 } }else{ // Determine which binary search method to use only once. partition=binarySearch(rangeBounds, k) // binarySearch either returns the match location or -[insertion point]-1 if(partition < 0) { partition=-partition-1 } if(partition > rangeBounds.length) { partition=rangeBounds.length } } if(ascending) { partition }else{ rangeBounds.length - partition } }- 当Partition的分配数小于128的时候,轮训的查找每个Partition
- 当Partition大于128的时候,使用二分法查找Partition
2.2.2 生成shuffle文件
- 基于前面对key进行排序的partition的分配,写到对应的partition文件中
- 合并Partition文件生成index和data文件(shuffle_shuffleid_mapid_0.index)(shuffle_shuffleid_mapid_0.data)因为Partition已经合并了,最后一位reduceID都是为0
注意:在这里并没有象SortShuffleWrite 对每个Partition进行排序,Spill 文件,最后合并文件,而是直接写到了Partition文件中。
2.3 Shuffle Read读取Shuffle文件
在BlockStoreShuffleReader的read函数里
[Scala] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
dep.keyOrderingmatch{ caseSome(keyOrd:Ordering[K])=> // Create an ExternalSorter to sort the data. Note that if spark.shuffle.spill is disabled, // the ExternalSorter won't spill to disk. valsorter= newExternalSorter[K, C, C](context, ordering =Some(keyOrd), serializer =dep.serializer) sorter.insertAll(aggregatedIter) context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled) context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled) context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes) CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop()) caseNone=> aggregatedIter }ExternalSorter.insertAll函数
[Scala] 纯文本查看 复制代码
1
2
3
4
5
6
while(records.hasNext) { addElementsRead() valkv=records.next() buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C]) maybeSpillCollection(usingMap=false) }ExternalSorter函数,这个函数在前面的这篇博客里介绍的比较清楚,这里使用了buffer结构体
[Scala] 纯文本查看 复制代码
1
2
@volatileprivatevarmap =newPartitionedAppendOnlyMap[K, C] @volatileprivatevarbuffer =newPartitionedPairBuffer[K, C]在reduceByKey的这些算子相同的Key是需要合并的,所以需要使用Map结构处理相同的Key的值的合并问题,而对排序来说,并不需要相同的值合并,使用Array结构就可以了。
注:在Spark上实现Map、Array都使用了数组的结构,并没有用链表结构
在上图的PartitionPairBuffer结构中,有以下几点要注意:
插入KV结构的时候,不进行排序,也就是在处理相同的Partition的时候直接读取插入Array
会存在当内存不够Spill到磁盘的情况,关于Spill请具体参考博客链接
2.3.1 排序
当ExternalSorter.insertAll函数完成后,才会构建一个排序的迭代器
[Scala] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
defpartitionedIterator:Iterator[(Int, Iterator[Product2[K, C]])] ={valcollection:WritablePartitionedPairCollection[K, C] =if(usingMap) map elsebuffer valusingMap=aggregator.isDefined if(spills.isEmpty) { // Special case: if we have only in-memory data, we don't need to merge streams, and perhaps // we don't even need to sort by anything other than partition ID if(!ordering.isDefined) { // The user hasn't requested sorted keys, so only sort by partition ID, not key groupByPartition(destructiveIterator(collection.partitionedDestructiveSortedIterator(None))) }else{ // We do need to sort by both partition ID and key groupByPartition(destructiveIterator( collection.partitionedDestructiveSortedIterator(Some(keyComparator)))) } }else{ // Merge spilled and in-memory data merge(spills, destructiveIterator( collection.partitionedDestructiveSortedIterator(comparator))) }}这里分成两种情况:
还在内存里没有Spill到文件中去,这时候构建一个内存里的PartitionedDestructiveSortedIterator迭代器,在迭代器中已经排序好了PartitionPairBuffer里的内容
[Scala] 纯文本查看 复制代码
1
2
3
4
5
6
7
/** Iterate through the data in a given order. For this class this is not really destructive. */overridedefpartitionedDestructiveSortedIterator(keyComparator:Option[Comparator[K]]) :Iterator[((Int, K), V)] ={ valcomparator=keyComparator.map(partitionKeyComparator).getOrElse(partitionComparator) newSorter(newKVArraySortDataFormat[(Int, K), AnyRef]).sort(data, 0, curSize, comparator) iterator}Spill到文件里的,文件里的已经排好序了,需要对内存里的PartitionPairBuffer进行排序(和前面一种情况相同的处理),最后对文件和内存进行外排序(外排序可参考博客)
2.4 最后的归并
在Driver端Dag-scheduler-event-loop 线程中会处理每个executor返回的结果(刚才Partition排序后的结果)
[Scala] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
private[scheduler]defhandleTaskCompletion(event:CompletionEvent) {.... caseSuccess=> stage.pendingPartitions -=task.partitionId taskmatch{ casert:ResultTask[_,_]=> // Cast to ResultStage here because it's part of the ResultTask // TODO Refactor this out to a function that accepts a ResultStage valresultStage=stage.asInstanceOf[ResultStage] resultStage.activeJobmatch{ caseSome(job)=> if(!job.finished(rt.outputId)) { updateAccumulators(event) job.finished(rt.outputId)=true job.numFinished +=1 // If the whole job has finished, remove it if(job.numFinished==job.numPartitions) { markStageAsFinished(resultStage) cleanupStateForJobAndIndependentStages(job) listenerBus.post( SparkListenerJobEnd(job.jobId, clock.getTimeMillis(), JobSucceeded)) } // taskSucceeded runs some user code that might throw an exception. Make sure // we are resilient against that. try{ job.listener.taskSucceeded(rt.outputId, event.result) }catch{ casee:Exception=> // TODO: Perhaps we want to mark the resultStage as failed? job.listener.jobFailed(newSparkDriverExecutionException(e)) } }}通过方法taskSucceeded的方法进行不同的Partition的合并
[Scala] 纯文本查看 复制代码
1
job.listener.taskSucceeded(rt.outputId, event.result)[Scala] 纯文本查看 复制代码
1
2
3
4
5
6
7
8
9
overridedeftaskSucceeded(index:Int, result:Any):Unit={ // resultHandler call must be synchronized in case resultHandler itself is not thread safe. synchronized { resultHandler(index, result.asInstanceOf[T]) } if(finishedTasks.incrementAndGet()==totalTasks) { jobPromise.success(()) }}实际上是调用了resultHandler方法,我们来看看resultHandler是怎样定义的
[Scala] 纯文本查看 复制代码
1
2
3
4
5
6
7
8
defrunJob[T, U:ClassTag]( rdd:RDD[T], func:(TaskContext, Iterator[T]) => U, partitions:Seq[Int]):Array[U]={ valresults=newArray[U](partitions.size) runJob[T, U](rdd, func, partitions, (index, res) => results(index) =res) results}在runJob的方法里
[Scala] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
defrunJob[T, U:ClassTag]( rdd:RDD[T], func:(TaskContext, Iterator[T]) => U, partitions:Seq[Int], resultHandler:(Int, U) => Unit):Unit={ if(stopped.get()) { thrownewIllegalStateException("SparkContext has been shutdown") } valcallSite=getCallSite valcleanedFunc=clean(func) logInfo("Starting job: " + callSite.shortForm) if(conf.getBoolean("spark.logLineage",false)) { logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString) } dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get) progressBar.foreach(_.finishAll()) rdd.doCheckpoint()}就是:
[Scala] 纯文本查看 复制代码
1
(index, res) => results(index) =res)构建了一个数组result,将每个Partition的数值保存到result的数组里
result[0]=partition[0] =array(tuple<k,v>,tuple<k,v>.....)
什么时候对所有的Partition最后合并呢?
来看RDD的collect算子
[Scala] 纯文本查看 复制代码
1
2
3
4
defcollect():Array[T]=withScope { valresults=sc.runJob(this, (iter:Iterator[T])=> iter.toArray) Array.concat(results:_*)}runJob返回的是result的数组,每个Partition是管理不同的范围,最后的合并只要简单的将不同的Partition合并就可以了
3. 排序完整的流程
- Driver 提交一个采样任务,需要Executor对每个Partition进行数据采样,数据采样是一次全数据的扫描
- Driver 获取采样数据,每个Partition的数据量,依据数据量的权重,进行Range的分配
- Driver 开始进行排序,先提交ShuffleMapTask ,Executor对分配到自己的数据基于Range进行Partition的分配,直接写入Shuffle文件中
- Driver 提交ResultTask,Executor读取Shuffle文件中相同的Partition进行合并(相同的key不做值的合并)、排序
- Driver 接收到ResultTask的值后,最后进行不同的Partition数据合并
转自:csdn
作者:raintungli
转载自:http://www.aboutyun.com/thread-22069-1-1.html
阅读全文
0 0
- 【Spark】sortBy[T]和sortByKey[T]排序详解
- Spark: sortBy和sortByKey函数详解
- Spark: sortBy和sortByKey函数详解
- Spark: sortBy和sortByKey函数详解
- Spark: sortBy和sortByKey函数详解
- Spark: sortBy和sortByKey函数详解
- Spark:sortBy和sortByKey的函数详解
- Spark: sortBy sortByKey 二次排序
- spark中的sortBy和sortByKey
- Spark算子[13]:sortByKey、sortBy、二次排序 源码实例详解
- SPARK:sortByKey和sortBy 函数讲解
- Spark中sortByKey和sortBy对(key,value)数据分别 根据key和value排序
- Spark中sortByKey和sortBy对(key,value)数据分别 根据key和value排序
- 【spark】sortByKey实现二次排序
- spark:sortByKey按年龄排序--20
- Spark 使用sortByKey进行二次排序
- Spark 使用sortByKey进行二次排序
- spark sortByKey
- Range Addition II(leetcode)
- NRF24L01多对一、多通道通讯关键代码
- 关于sql联级删除和修改
- python3中单引号,双引号,三个单引号 ,三个双引号的差别,以及反斜杠的用法
- 透视
- 【Spark】sortBy[T]和sortByKey[T]排序详解
- pcl点云索引与应用
- 安装Ubuntu遇到的一些坑
- swagger -- ref 自定义的使用
- 思维导图之如何战胜拖延症
- linux FTP启动
- javascript函数式编程库-underscore.js
- 【12月19日】LeetCode刷题日志(三):Best Time to Buy and Sell Stock with Transaction Fee
- JavaScript数据可视化编程学习(一)Flotr2,包含简单的,柱状图,折线图,饼图,散点图


