循环神经网络(Recurrent Neural Network)
来源:互联网 发布:淘宝网瘦身腰带 编辑:程序博客网 时间:2024/05/19 12:36
本博客是针对李宏毅教授在Youtube上上传的课程视频的学习笔记。
课程视频链接
- Introduction
- Framework
- RNN Example
- Variants of RNN
- Jordan Network store output into memory
- Bidirectional RNN
- Long Short-term Memory LSTM
- Framework
- Relationship with original network
Introduction
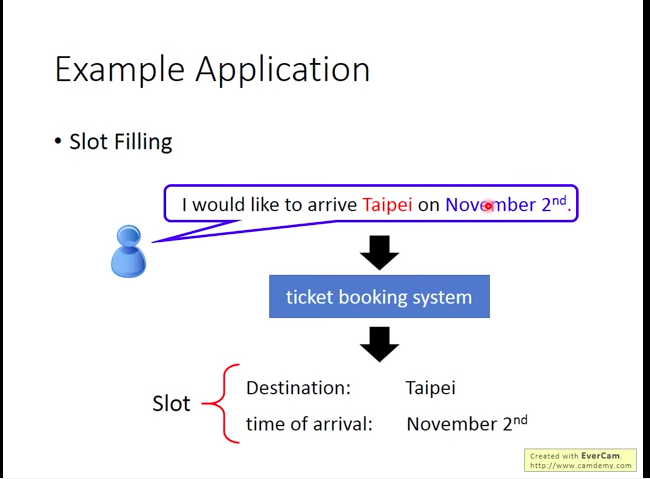
假设我们想做一个智慧订票系统,它能根据用户的文本输入获得订票必须的信息。那么对于系统来说,它所需的订票信息可以被视作若干槽(slot),这些槽需要被填充。比如在订票这里,槽包括目的地(destination),和到达时间(time of arrival)。那么订票系统就需要从用户的输入中提取出两个槽对应的信息填入。
那么,这个问题当然是可以用前馈神经网络来解的,只要把每个句子中的词都用一个词向量(word vector)来表示(最简单的方法是如下的1-of-N encoding,也包括Beyond 1-of-N encoding的一些方法),然后扔到NN(神经网络)里,让NN来判断该词是否代表目的地或者到达时间(属于某个槽的概率)。
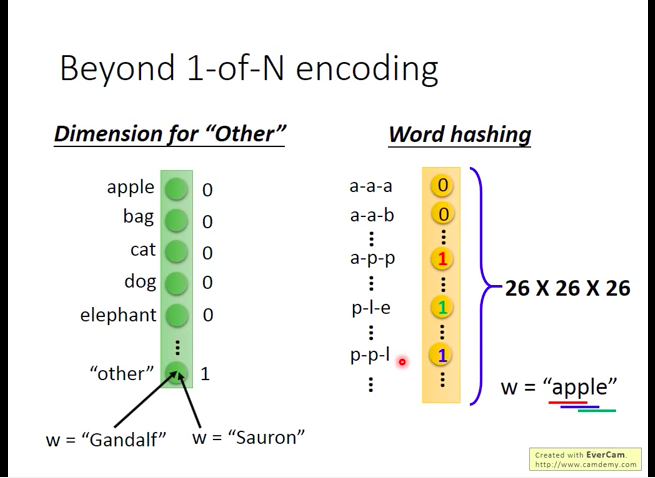
- 1-of-N encoding

- Beyond 1-of-N encoding
为了保证能够顾及到所有的词,我们可以加入一个”other”分量,表示未出现在该向量其它分量中的词;也可以做词散列化(word hashing)。
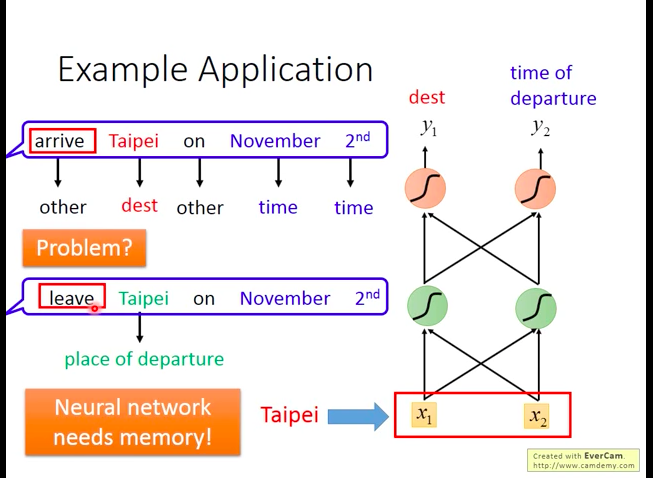
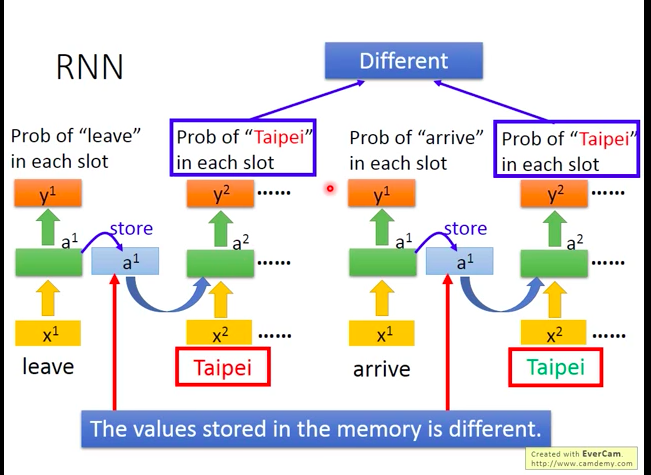
如下图,但是使用前馈神经网络的问题也很明显:我们会需要系统有记忆能力,即它能判断句子中的地点到底是目的地,还是出发地。 (eg:arrive Taipei on Nov.2nd 和 leave Taipei on Nov.2nd中的Taipei都是地点,但前者是目的地,后者是出发地,要买的票完全不一样)。所以,我们可能会希望我们的系统会记得它在看过“Taipei”之前,有看过”arrive”或”leave”。也即面对相同的输入,能输出相应的不同的结果的能力,于是,循环神经网络(Recurrent Neural Network)登场了。
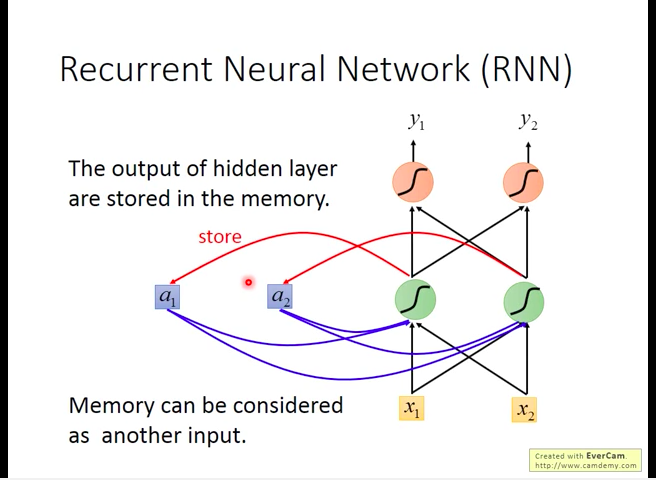
Framework
RNN会将隐层的输出暂存到一个额外的单元中(

RNN Example
我们用一个简单的RNN例子来说明一下它的效果。
首先给定额外单元初始值0,然后我们的输入序列如下图所示。那么,当我们输入第一个向量[1,1],那么其最终对应的output会是[4,4],而隐层会将它的output[2,2]写入到额外单元。
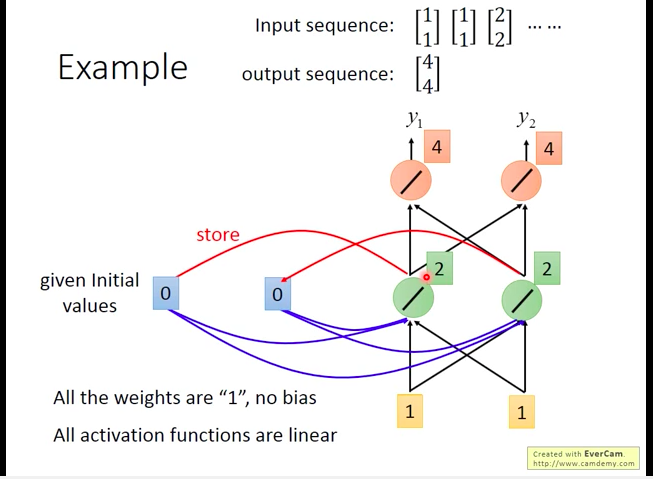
然后,输入第二个向量[1,1],会输出[12,12]。(此时已经达到效果:面对相同的输入[1,1],RNN可以产生不同的输出)
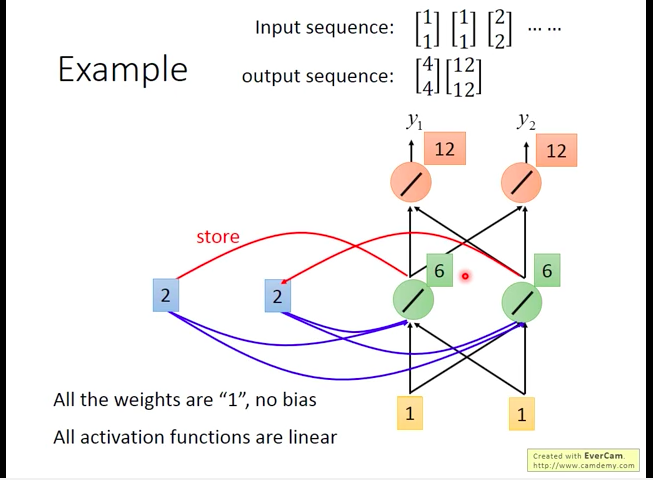
接着,输入第三个向量[2,2],会输出[32,32]。
同时,我们要注意,当我们改变输入向量的输入顺序时,RNN的输出也会改变,对于RNN来说,输入的顺序也是一个非常重要的特性。

那么之前提过的智慧订票系统问题也就可以用RNN来解决。
我们将客户的语句逐词输入到RNN中,让RNN输出该词属于slot的概率,而RNN的能力使得它可以“记得”看过“arrive”或“leave”,进而给出更准确的输出结果。

而之所以RNN可以具备“记住能力”,最核心的也就在于额外单元(memory),因为它储存了输入“arrive”或“leave”后的隐层的输出值,于是在下一次RNN接受“Taipei”输入时,它会输入不同的对应值到隐层中,以区分两种不同的情况。
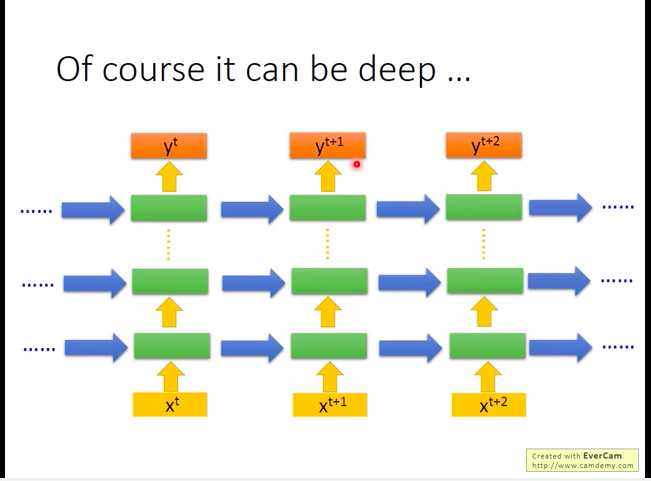
理所当然的,RNN也可以做的很深(deep),即加很多隐层。
Variants of RNN
RNN有很多扩展变体,下面举几个例子。
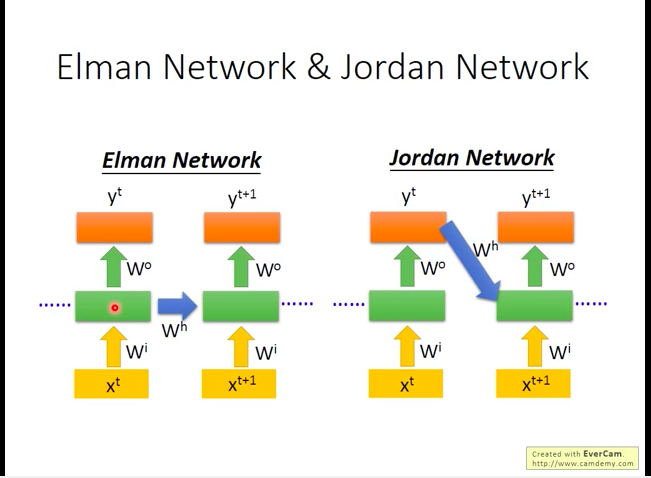
Jordan Network (store output into memory)
- Elman网络:每次将隐层的值读出(放入memory),在下一次再读入隐层;
- Jordan网络:每次将输出层的值读出(放入memory),在下一次再读入隐层。(一般Jordan网络的表现据说会好一些,因为它相对Elman网络可以更好地控制存到Memory中的内容。)
Bidirectional RNN
双向RNN。
同时训练一个正向读取输入序列的逆向读取输入序列的网络,再将它们的隐层拿出来,都接到一个输出层,得到最后的输出。
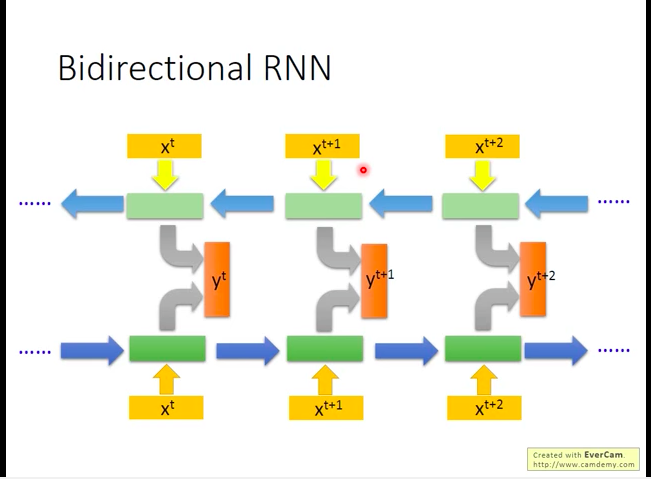
双向网络的好处是:它同时正向和逆向看过了输入序列,那么就可以对序列中任一单个输入的上下文环境都有了解,而不是只了解它之前的输入情况。
Long Short-term Memory (LSTM)
RNN每次有新的输入时,memory都会变化,而LSTM则可以保持相同的memory更长时间。
如下图,LSTM中有三个阀门(gate)。
- Input Gate:当某个值想被写入Memory cell中时,需要input gate打开,而input gate打开和关闭的时机是LSTM自己学习到的。
- Output Gate:当Memory Cell的值要输出到网路的其它部分时,需要output gate打开,而打开和关闭的时机也是自己学习到的。
- Forget Gate:当Memory Cell的值要被遗忘时,需要forget gate打开,而打开和关闭的时机也是自己学习到的。
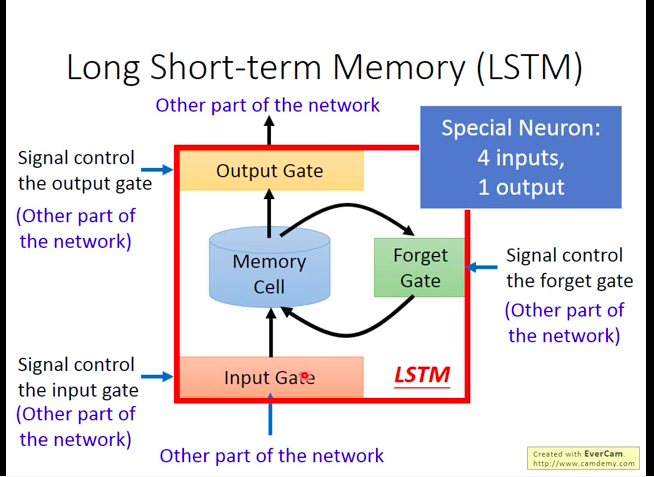
所以整个LSTM可以看做有4个输入(1个网络其它部分的输入+3个gate的控制信号)和一个输出。
Framework
gate的激活函数f一般用sigmoid函数,因为输出值在[0,1]之间,可以模拟阀门打开的程度。

(李老师提到说想做人体LSTM,以帮助大家更好地理解LSTM的工作机制233333…)
下图可以帮助理解LSTM的工作机制:

然后我们再在LSTM中做一下实际的运算。
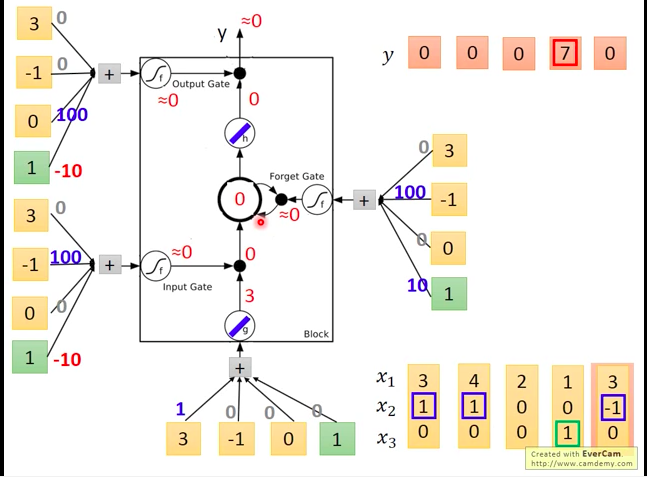
如下图,每个输入值(包括三个阀门的输入值)都是通过将实际LSTM输入向量分别与各个输入口对应的weights相乘再加上bias获得的。
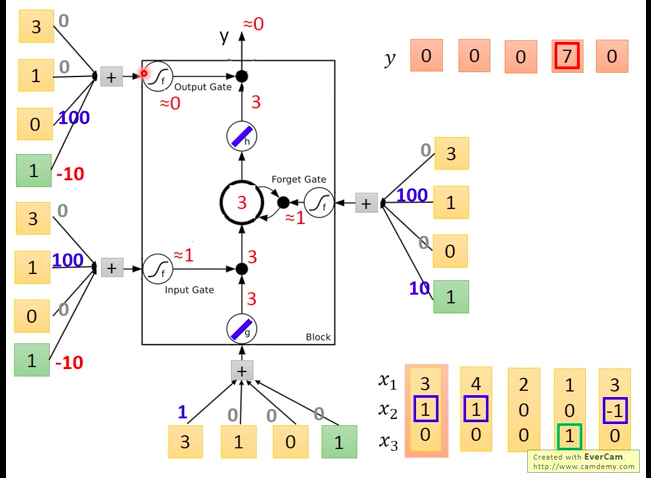
我们来分析一下,每个gate可能被打开的情况:
- input gate:当
x2 有正值时,通常会使得gate的输入为较大的正值,会使得input gate被打开,否则关闭。 - ouptut gate:当
x3 有正值时,通常会使得gate的输入为较大的正值,会使得input gate被打开,否则关闭。 forget gate:因为bias为正,除非
x2 为负,否则一般都是打开状态。实际输入的例子
首先输入第一个向量[3,1,0],获得下图的结果。
输入第二个向量[4,1,0],获得下图的结果。

输入第三个向量[2,0,0],获得下图的结果。
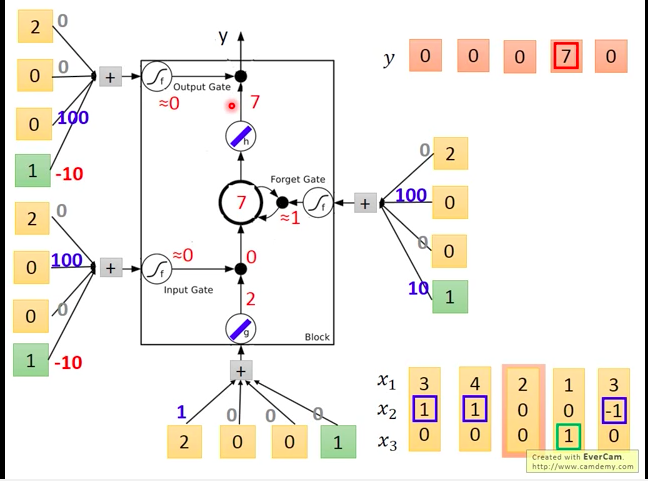
输入第四个向量[1,0,1],获得下图的结果。
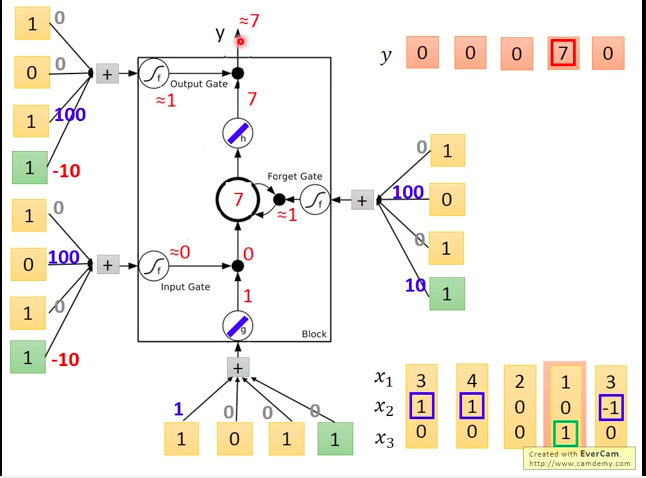
输入第五个向量[3,-1,0],获得下图的结果。
Relationship with original network
在之前的神经网络中,我们简单地将隐层的单元设置为一个神经元,而当利用LSTM时,可以将之前的神经元替换为一个LSTM单元。不过,因此用上了LSTM的NN参数的数量也相对多了大约4倍。
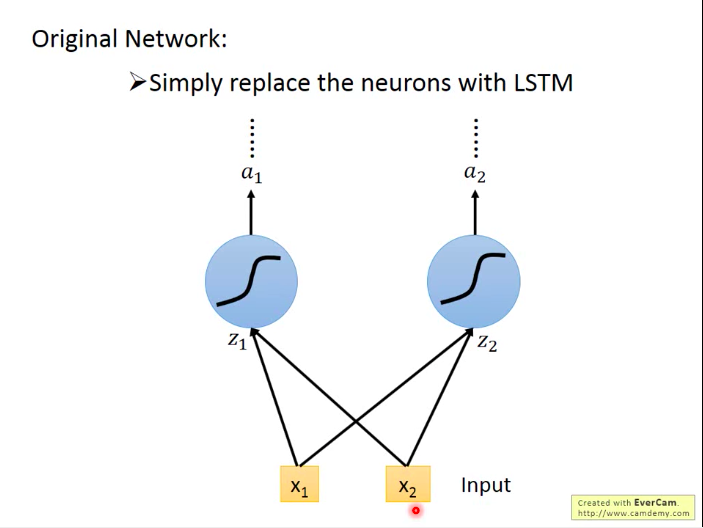
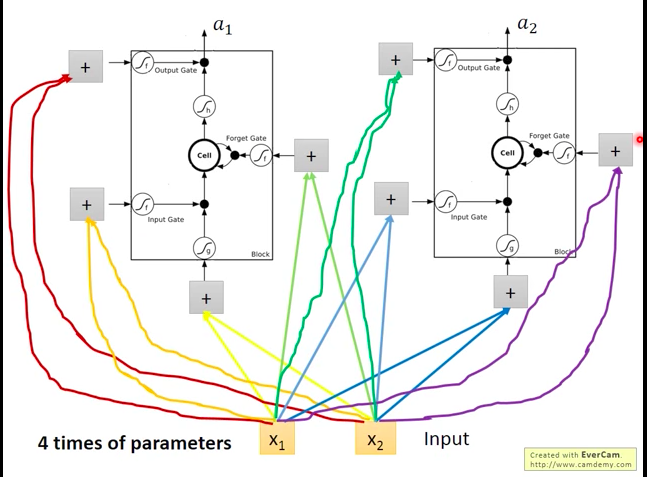
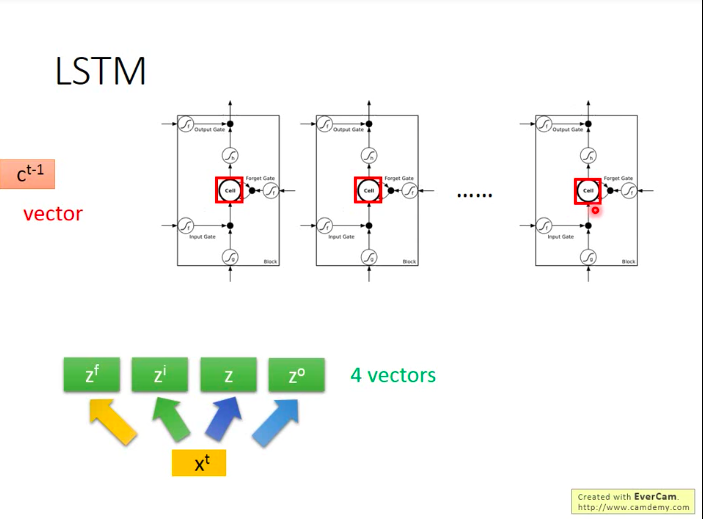
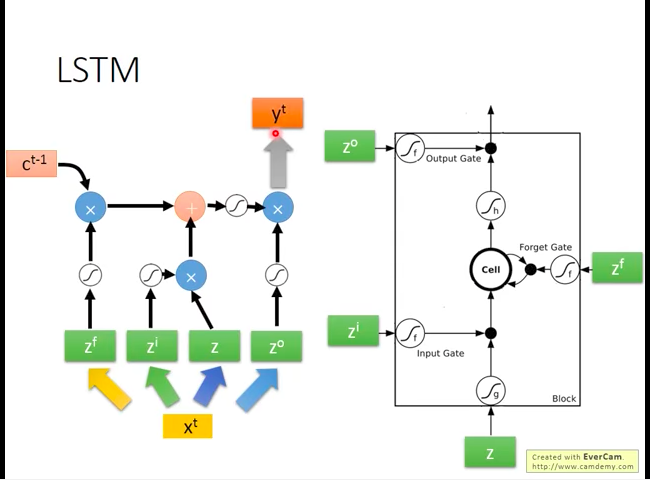
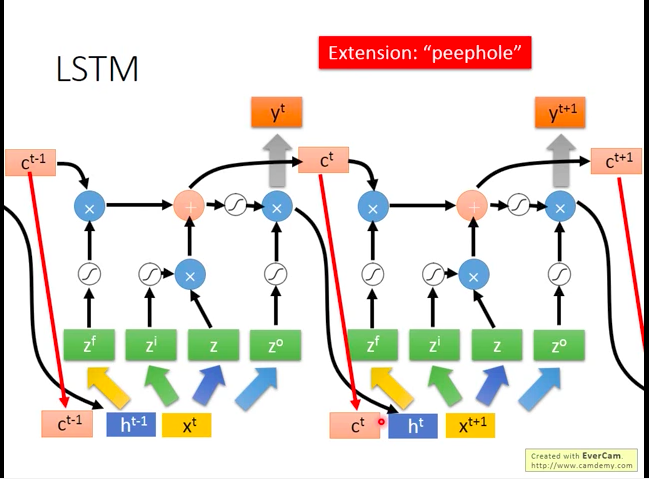
多个LSTM的串联:
Keras也支持LSTM、GRU(LSTM的简化版本,少了一个阀门,参数比LSTM少了三分之一),Simple RNN。
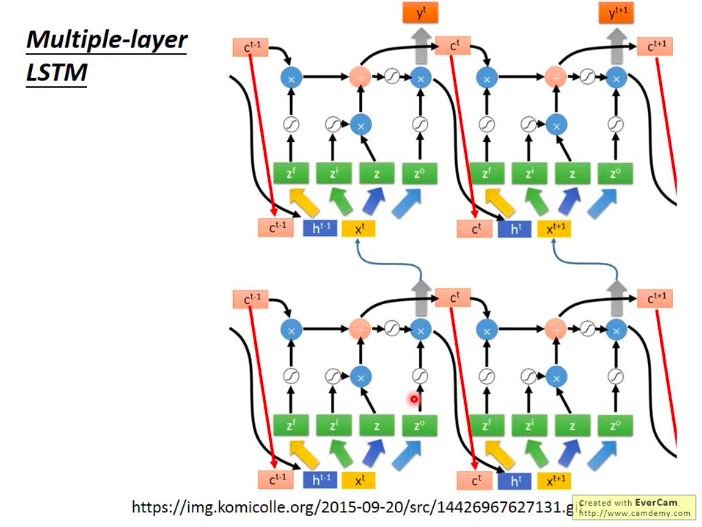
老师说,很多人看了上图那么复杂的架构后,反应都如下图:觉得这种网络可能不会work。

不过LSTM现在是比较标准的RNN架构了,所以现在做RNN的基本都是在LSTM上下功夫。而Keras里面建立一个LSTM单元也只要一个简单的构造函数就行了,所以不同太担心,哈哈!
- 循环神经网络(Recurrent Neural Network)
- 概述 循环神经网络(RNN-Recurrent Neural Network)(1)
- Recurrent Neural Network系列1--RNN(循环神经网络)概述
- 详解循环神经网络(Recurrent Neural Network)
- 详解循环神经网络(Recurrent Neural Network)
- 回归神经网络RNN(Recurrent Neural network)
- 循环神经网络(Recurrent Neural Network, RNN)与LSTM
- Recurrent Neural Networks 循环神经网络
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- android imageView释放内存
- java基础
- spring boot集成mybatis,枚举类型字段注册通用
- SQL LEFT JOIN 关键字
- 用bbed修改数据文件头,跳过丢失的归档
- 循环神经网络(Recurrent Neural Network)
- 微信小程序----导航栏透明渐变二
- Android动画解析(二)-----属性动画
- golang语言中map的初始化及使用
- [POJ-2387]Til the Cows Come Home
- 33. Search in Rotated Sorted Array
- SQL AND & OR (运算符)
- 按住鼠标左键直接拖动页面,横向滚动
- spring mvc 拦截器


