PRML第四章笔记
来源:互联网 发布:办公软件ppt教程 编辑:程序博客网 时间:2024/06/04 19:32
这是关于PRML第四章的学习笔记。主要从内容思想的理解,具体的理论推导需要结合原文以及概率论的知识。这一章主要讲线性的分类模型,所谓分类线性模型,是指决策⾯是输⼊向量x的线性函数,因此被定义为D维输⼊空间中的(D − 1)维超平⾯。
主要内容有四点:
1) 判别函数模型:Fisher准则的分类,以及它和最小二乘分类的关系 (Fisher分类是最小二乘分类的特例)
2) 概率生成模型的分类模型
3) 概率判别模型的分类模型
4) 全贝叶斯概率的Laplace近似
线性分类模型和第三章的线性回归可以统称为线性模型。只是对应的激活函数是做分类还是做回归的区别。 
一,判别函数模型:找到函数f(x)将输入x映射为类别标签,也就是去掉激活函数,直接做x的变换。对于线性判别函数,就是x的现在线性组合(或者基函数的线性组合),即决策面为超平面的判别函数。
1,二分类:输入变量的线性函数 ,y(x) ≥ 0,那么它被分到C1中,否则被分到C2中。
(原文中的点到平面的距离公式也很重要)
2,k分类:采用K类判别函数,这个K类判别函数由K个线性函数组成,形式为:,对于点x, 如果对于所有的j != k都有
, 那么就把它分到
。
3,分类的最小平方法:就是用平⽅和误差函数最小化求解参数W的方法。但是最小平方法抛弃掉了所有的概率表示,有很大的局限性。(对于任意的x的值,y(x)的元素的和等于1。但是,这个对于加和的限制本⾝并不能够让模型的输出表⽰为概率的形式,因为它们没有被限制在区间(0, 1))
4,Fisher线性判别函数:让类投影后分开大,同时类内部方差小的想法确定参数W。类间散度最大是通过它们的均值距离体现的,而 类内聚合度最强 是通过 类内的点到均值的散的程度表达的。 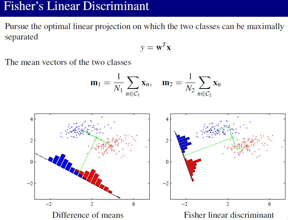
注意:二分类中Fisher准则可以看成最小平方的一个特例
5,感知器算法:对应一个二分类模型,输入向量首先使用一个固定的非线性函数变换得到特征向量ϕ(x),然后使用这个特征向量构造一个一般的线性模型形式:。
算法对感知器准则(另外一种误差函数)使用随机梯度下降寻找参数。 

(常见的模型:感知机模型、k邻近、决策树、支持向量机)
二、概率生成模型:对条件分布概率和先验分布建模,然后使用贝叶斯定理计算后验分布概率。后验分布也就是逻辑回归,后验概率找到就是逻辑回归分割面。 
(具体分类就选后验概率最大的)
1,高斯分布-生成模型:(允许每个类条件概率密度p(x | Ck)有相同的协⽅差矩阵Σk,那么⼆次项消去的现象就会出现,否则就会出现二次判别函数,而不是线性的。)
(1)对于二类高斯分布模型-生成模型:(也就是判断一个输入,属于那个高斯分布,即两个高斯分布的后验概率较大) 
(2)对于多分类的高斯分布-生成模型:(谁的后验概率比较大选那个) 
(3)结论:最终求得的决策边界对应于后验概率为常数的决策⾯,因此由x的线性函数给出,从⽽决策边界在输⼊空间是线性的。先验概率密度
只出现在偏置参数
中,因此先验的改变的效果是平移决策边界,即平移后验概率中的常数轮廓线。
2,最大似然函数求模型的参数
在上面提出的生成模型中,即后验概率最大化,这个模型的参数为:条件概率密度的参数、先验类概率
。当我们知道类条件概率密度
的参数化的函数形式,我们就能够使⽤最⼤似然法确定各个参数的值。

3,对于整个指数族分布都有同样的分析方法:
1) 假定class-conditional distribution的分布形式,MLE估计该分布中的参数(从而得到了class-conditional distribution)
2) 计算每个类别的后验概率。在上面的例子中,得到的后验概率刚好是一个GLM模型(Logistic)
(常见的模型有:高斯模型、朴素贝叶斯模型、隐马尔科夫模型)
三、概率判别式模型使⽤⼀般的线性模型的函数形式,然后使⽤最⼤似然法直接确定它的参数。即:最⼤化由条件概率分布定义的似然函数。用后验概率表示似然函数,直接求出模型参数
1,逻辑回归:类别C1的后验概率可以写成作⽤在特征向量φ的线性函数上的logistic sigmoid函数的形式,进而可以得出似然函数的表达式。并且采用牛顿方法或得参数的值(具体看原文推导公式)。(对多分类处理,用后验分布表示似然函数,操作一样)
2,probit回归:当后验概率的形式很复杂的时候,使用一般的后验概率形式(之前都是逻辑函数),即:采用P(θ)累计分布函数来代替逻辑函数作为后验分布。
(假设概率密度p(θ)是零均值、单位⽅差的⾼斯概率密度。对应的累积分布函数为这被称为逆probit(inverse probit) 函数。它的形状为sigmoid形,基于probit激活函数的⼀般的线性模型被称为probit回归。)
3,标准链接函数:如果假设⽬标变量的条件分布来⾃于指数族分布,对应的激活函数选为标准链接函数。具体查看原文,就是把一些想法统一到一起了。
(常见的模型也就只有逻辑回归模型)
四、拉普拉斯近似:拉普拉斯是一个数学工具,在讨论贝叶斯观点的分类是很有用。它的⽬标是找到定义在⼀组连续变量上的概率密度的⾼斯近似。
1,拉普拉斯近似介绍:⾼斯分布有⼀个性质,即它的对数是变量的⼆次函数。考虑ln f(z)以众数z0为中⼼的泰勒展开的近似方法,找到一个高斯近似。(为了应⽤拉普拉斯近似, 我们⾸先需要寻找众数z0, 然后计算在那个众数位置上的Hessian矩阵)
2,拉普拉斯应用:拉普拉斯方法可以计算模型证据的近似值,对模型进行评估。
五、贝叶斯logistic回归
对于logistic回归,精确的贝叶斯推断是⽆法处理的。特别地,计算后验概率分布需要对先验概率分布于似然函数的乘积进⾏归⼀化,⽽似然函数本⾝由⼀系列logistic sigmoid函数的乘积组成,每个数据点都有⼀个logistic sigmoid函数。对于预测分布的计算类似地也是⽆法处理的。
这里采用拉普拉斯近似,找到一个高斯近似分布。拉普拉斯近似由下⾯的⽅式获得:⾸先寻找后验概率分布的众数,然后调节⼀个以众数为中⼼的⾼斯分布。这需要计算对数后验概率的⼆阶导数,这等价于寻找Hessian矩阵。(具体看原文推导)
- PRML第四章笔记
- PRML第二章笔记
- PRML第三章笔记
- PRML笔记
- PRML笔记之INTRODUCTION
- PRML 学习笔记
- PRML笔记:1-介绍
- PRML阅读笔记
- PRML抽样方法笔记
- prml第一章笔记
- PRML第一章笔记
- PRML CHAPTER 2 学习笔记
- PRML学习笔记(1)
- PRML学习笔记(一)
- PRML 学习笔记(1)
- PRML 学习笔记(2)
- 机器学习笔记(PRML)
- 【PRML】第一章绪论学习笔记
- FineReport 8.0 无限制企业破解版授权码
- 2017研究生乒乓球比赛记录
- Full Cleaner中文破解版及软件使用教程
- windows下sapi做TTS转化(修复)总结
- iview page分页组件的集成
- PRML第四章笔记
- Reinforcement Learning系列之二:MC prediction
- Android异步和同步的区别
- win10 64位串口抓包监控软件
- Python bottle 笔记(二) —— APP
- 6-1 多态性与虚函数
- android 屏幕旋转重置界面问题 局部刷新界面问题
- Android studio3.0配置cocos2dx3.1.6
- perl中字符串编码分析和注意事项


