字节序的问题
来源:互联网 发布:网络解锁助手支持机型 编辑:程序博客网 时间:2024/05/22 11:13
说到程序间的通信,说到底便是发送数据流。我们一般把字节(byte)看作是数据的最小单位。当然,其实一个字节中还包含8个比特(bit)──有时候我奇怪为什么很多朋友会不知道bit或是它和byte的关系。当我们拿到一系列byte的时候,它本身其实是没有意义的,有意义的只是“识别字节的方式”。例如,同样4个字节的数据,我们可以把它看作是1个32位整数、2个Unicode、或者字符4个ASCII字符。
同样我们知道,在一个32位的CPU中“字长”为32个bit,也就是4个byte。在这样的CPU中,总是以4字节对齐的方式来读取或写入内存,那么同样这4个字节的数据是以什么顺序保存在内存中的呢?例如,现在我们要向内存地址为a的地方写入数据0x0A0B0C0D,那么这4个字节分别落在哪个地址的内存上呢?这就涉及到字节序的问题了。
每个数据都有所谓的“有效位(significant byte)”,它的意思是“表示这个数据所用的字节”。例如一个32位整数,它的有效位就是4个字节。而对于0x0A0B0C0D来说,它的有效位从高到低便是0A、0B、0C及0D——这里您可以把它作为一个256进制的数来看(相对于我们平时所用的10进制数)。
而所谓大字节序(big endian),便是指其“最高有效位(most significant byte)”落在低地址上的存储方式。例如像地址a写入0x0A0B0C0D之后,在内存中的数据便是:
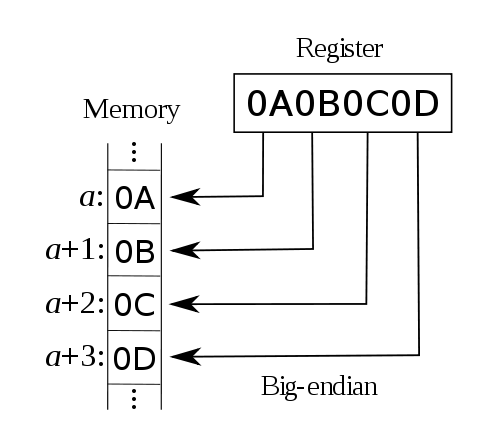
而对于小字节序(little endian)来说就正好相反了,它把“最低有效位(least significant byte)”放在低地址上。例如:
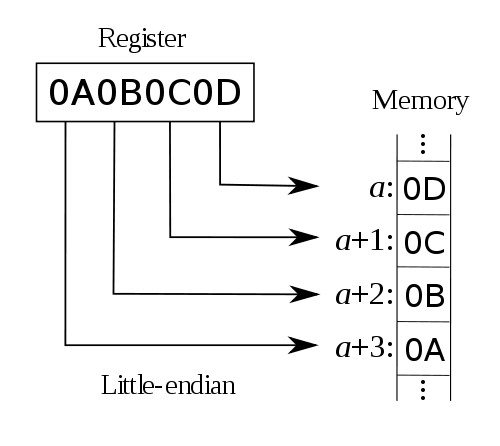
谈到字节序的问题,必然牵涉到两大CPU派系。那就是Motorola的PowerPC系列CPU和Intel的x86系列CPU。PowerPC系列采用big endian方式存储数据,而x86系列则采用little endian方式存储数据。那么究竟什么是big endian,什么又是little endian呢?
其实big endian是指低地址存放最高有效字节(MSB),而little endian则是低地址存放最低有效字节(LSB)。
用文字说明可能比较抽象,下面用图像加以说明。比如数字0x12345678在两种不同字节序CPU中的存储顺序如下所示:
Big Endian
低地址 高地址
----------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 12 | 34 | 56 | 78 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Little Endian
低地址 高地址
----------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 78 | 56 | 34 | 12 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
从上面两图可以看出,采用big endian方式存储数据是符合我们人类的思维习惯的。而little endian,!@#$%^&*,见鬼去吧 -_-|||
为什么要注意字节序的问题呢?你可能这么问。当然,如果你写的程序只在单机环境下面运行,并且不和别人的程序打交道,那么你完全可以忽略字节序的存在。但是,如果你的程序要跟别人的程序产生交互呢?在这里我想说说两种语言。C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而JAVA编写的程序则唯一采用big endian方式来存储数据。试想,如果你用C/C++语言在x86平台下编写的程序跟别人的JAVA程序互通时会产生什么结果?就拿上面的0x12345678来说,你的程序传递给别人的一个数据,将指向0x12345678的指针传给了JAVA程序,由于JAVA采取big endian方式存储数据,很自然的它会将你的数据翻译为0x78563412。什么?竟然变成另外一个数字了?是的,就是这种后果。因此,在你的C程序传给JAVA程序之前有必要进行字节序的转换工作。
无独有偶,所有网络协议也都是采用big endian的方式来传输数据的。所以有时我们也会把big endian方式称之为网络字节序。当两台采用不同字节序的主机通信时,在发送数据之前都必须经过字节序的转换成为网络字节序后再进行传输。ANSI C中提供了下面四个转换字节序的宏。
big endian:最高字节在地址最低位,最低字节在地址最高位,依次排列。
little endian:最低字节在最低位,最高字节在最高位,反序排列。
endian指的是当物理上的最小单元比逻辑上的最小单元小时,逻辑到物理的单元排布关系。咱们接触到的物理单元最小都是byte,在通信领域中,这里往往是bit,不过原理也是类似的。
一个例子:
如果我们将0x1234abcd写入到以0x0000开始的内存中,则结果为
big-endian little-endian
0x0000 0x12 0xcd
0x0001 0x34 0xab
0x0002 0xab 0x34
0x0003 0xcd 0x12
目前应该little endian是主流,因为在数据类型转换的时候(尤其是指针转换)不用考虑地址问题。
PS:
这两个术语来自于 Jonathan Swift 的《《格利佛游记》其中交战的两个派别无法就应该从哪一端--小端还是大端--打开一个半熟的鸡蛋达成一致。:)
在那个时代,Swift是在讽刺英国和法国之间的持续冲突,Danny Cohen,一位网络协议的早期开创者,第一次使用这两个术语来指代字节顺序,后来这个术语被广泛接纳了
摘自《深入理解计算机系统》
很好的一本书:)
An Essay on Endian Order
Copyright (C) Dr. William T. Verts, April 19, 1996
Depending on which computing system you use, you will have to consider the byte order in which multibyte numbers are stored, particularly when you are writing those numbers to a file. The two orders are called "Little Endian" and "Big Endian".
The Basics
"Little Endian" means that the low-order byte of the number is stored in memory at the lowest address, and the high-order byte at the highest address. (The little end comes first.) For example, a 4 byte LongInt
Byte3 Byte2 Byte1 Byte0
will be arranged in memory as follows:
Base Address+0 Byte0
Base Address+1 Byte1
Base Address+2 Byte2
Base Address+3 Byte3
Intel processors (those used in PC's) use "Little Endian" byte order.
"Big Endian" means that the high-order byte of the number is stored in memory at the lowest address, and the low-order byte at the highest address. (The big end comes first.) Our LongInt, would then be stored as:
Base Address+0 Byte3
Base Address+1 Byte2
Base Address+2 Byte1
Base Address+3 Byte0
Motorola processors (those used in Mac's) use "Big Endian" byte order.
Which is Better?
You may see a lot of discussion about the relative merits of the two formats, mostly religious arguments based on the relative merits of the PC versus the Mac. Both formats have their advantages and disadvantages.
In "Little Endian" form, assembly language instructions for picking up a 1, 2, 4, or longer byte number proceed in exactly the same way for all formats: first pick up the lowest order byte at offset 0. Also, because of the 1:1 relationship between address offset and byte number (offset 0 is byte 0), multiple precision math routines are correspondingly easy to write.
In "Big Endian" form, by having the high-order byte come first, you can always test whether the number is positive or negative by looking at the byte at offset zero. You don't have to know how long the number is, nor do you have to skip over any bytes to find the byte containing the sign information. The numbers are also stored in the order in which they are printed out, so binary to decimal routines are particularly efficient.
What does that Mean for Us?
What endian order means is that any time numbers are written to a file, you have to know how the file is supposed to be constructed. If you write out a graphics file (such as a .BMP file) on a machine with "Big Endian" integers, you must first reverse the byte order, or a "standard" program to read your file won't work.
The Windows .BMP format, since it was developed on a "Little Endian" architecture, insists on the "Little Endian" format. You must write your Save_BMP code this way, regardless of the platform you are using.
Common file formats and their endian order are as follows:
Adobe Photoshop -- Big Endian
BMP (Windows and OS/2 Bitmaps) -- Little Endian
DXF (AutoCad) -- Variable
GIF -- Little Endian
IMG (GEM Raster) -- Big Endian
JPEG -- Big Endian
FLI (Autodesk Animator) -- Little Endian
MacPaint -- Big Endian
PCX (PC Paintbrush) -- Little Endian
PostScript -- Not Applicable (text!)
POV (Persistence of Vision ray-tracer) -- Not Applicable (text!)
QTM (Quicktime Movies) -- Little Endian (on a Mac!)
Microsoft RIFF (.WAV & .AVI) -- Both
Microsoft RTF (Rich Text Format) -- Little Endian
SGI (Silicon Graphics) -- Big Endian
Sun Raster -- Big Endian
TGA (Targa) -- Little Endian
TIFF -- Both, Endian identifier encoded into file
WPG (WordPerfect Graphics Metafile) -- Big Endian (on a PC!)
XWD (X Window Dump) -- Both, Endian identifier encoded into file
Correcting for the Non-Native Order
It is pretty easy to reverse a multibyte integer if you find you need the other format. A single function can be used to switch from one to the other, in either direction. A simple and not very efficient version might look as follows:
Function Reverse (N:LongInt) : LongInt ;
Var B0, B1, B2, B3 : Byte ;
Begin
B0 := N Mod 256 ;
N := N Div 256 ;
B1 := N Mod 256 ;
N := N Div 256 ;
B2 := N Mod 256 ;
N := N Div 256 ;
B3 := N Mod 256 ;
Reverse := (((B0 * 256 + B1) * 256 + B2) * 256 + B3) ;
End ;
A more efficient version that depends on the presence of hexadecimal numbers, bit masking operators AND, OR, and NOT, and shift operators SHL and SHR might look as follows:
Function Reverse (N:LongInt) : LongInt ;
Var B0, B1, B2, B3 : Byte ;
Begin
B0 := (N AND $000000FF) SHR 0 ;
B1 := (N AND $0000FF00) SHR 8 ;
B2 := (N AND $00FF0000) SHR 16 ;
B3 := (N AND $FF000000) SHR 24 ;
Reverse := (B0 SHL 24) OR (B1 SHL 16) OR (B2 SHL 8) OR (B3 SHL 0) ;
End ;
- 字节序的问题
- 字节序的问题
- 字节序的问题
- 关于字节序的问题
- 计算机的字节序问题
- 关于字节序的问题
- 网络字节序的问题
- 大小字节序的问题
- 网络字节序的问题
- PowerPC的字节序问题
- PowerPC的字节序问题
- 网络字节序问题的思考
- 字节序问题:大小端的判定
- 字节序的大小端问题
- 字节对齐的问题
- 字节对齐的问题
- 字节对齐的问题
- 字节对齐的问题
- VS2008中关于“加载安装组件时遇到问题。取消安装”的解决
- 【转】谈谈使用VFW在windows下编程控制摄像头(一)。 【孙涛】
- GAC
- linux kernel for mips memory lost when pfn!=0
- 10款让你震撼的js+css图片展示
- 字节序的问题
- log4j输出多个自定义日志文件,动态配置路径
- 中文的几个编码 GB2312、GBK、GB18030、GB13000、BIG5
- 魔兽停服:500万寂寞背后的利益暗战
- 使用System.Net.Mail注意区分form和sender
- 博客开通中......
- 退出SSH时继续执行PHP脚本
- RHEL5下搭建DNS服务器
- ETL一些经验分享


