Unicode、GB2312、GBK和GB18030中的汉字[转]
来源:互联网 发布:php自动识别验证码 编辑:程序博客网 时间:2024/05/17 23:36
GB18030有两个版本:GB18030-2000和GB18030-2005。GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字。GB18030-2005的主要特点是在GB18030-2000基础上增加了 CJK统一汉字扩充B的汉字。本文数一数GB18030中的汉字,也顺便看看其它标准中的汉字。
1 Unicode中的汉字
在Unicode 5.0的99089个字符中,有71226个字符与汉字有关。它们的分布如下:
Block名称开始码位结束码位字符数CJK统一汉字4E009FBB20924CJK统一汉字扩充A34004DB56582
CJK统一汉字扩充B200002A6D642711
CJK兼容汉字F900FA2D302
CJK兼容汉字FA30FA6A59
CJK兼容汉字FA70FAD9106CJK兼容汉字补充2F8002FA1D542
如果不算兼容汉字,Unicode目前支持的汉字总数是20924+6582+42711=70217。
这里有一个细节。在早期的Unicode版本中,CJK统一汉字区的范围是0x4E00-0x9FA5,也就是我们经常提到的20902个汉字。当前版本的Unicode增加了22个字符,码位是0x9FA6-0x9FBB。它们是:
![]()
那么GB18030是否支持这22个字符?后面还会讨论。
2 GB2312
1980年的GB2312一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
这6763个汉字在Unicode中不是连续的,分布在CJK统一汉字字符区(0x4E00-0x9FA5)的20902个汉字中。
3 GBK
1995年的汉字扩展规范GBK1.0收录了21886个符号,包括21003个汉字和883个其它符号。
这21003汉字包括CJK统一汉字区的20902个汉字。余下的101个汉字包括:
- 增补汉字和部首80个,包括28个部首和52个汉字。GBK编码是从FE50-FE7E,FE80-FEA0。下图标注了Unicode编码。
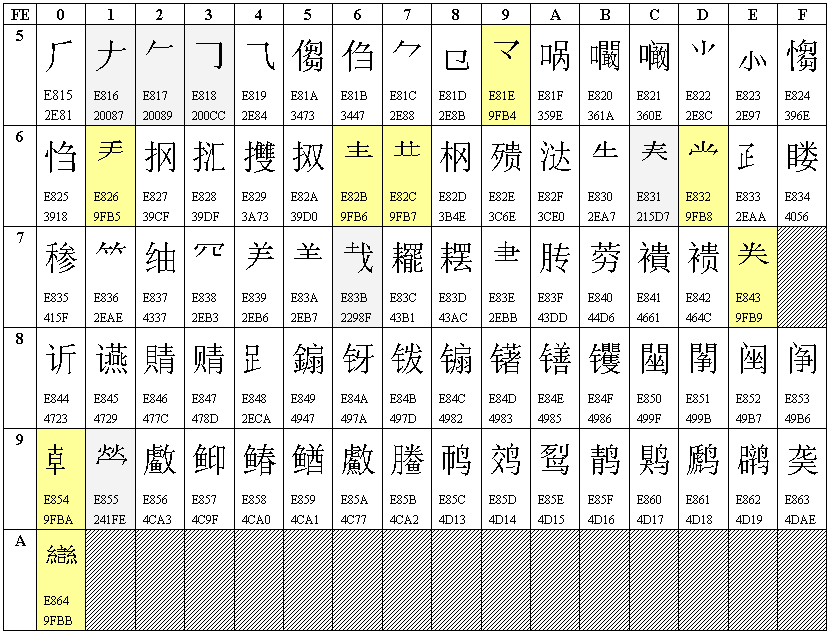
在制定GBK时,Unicode中还没有这些字符,所以使用了专用区的码位,这80个字符的码位是0xE815-0xE864。后来,Unicode将52 个汉字收录到“CJK统一汉字扩充A”。28个部首中有14个部首被收录到“CJK部首补充区”。所以在上图中,这些字符都有两个Unicode编码。
上图中淡黄色背景的8个部首被收录到“CJK统一汉字区”的新增区域,即前面提到的0x9FA6-0x9FBB。还有6个淡灰色背景的部首被Unicode收录到“CJK统一汉字扩充B”(网友slt指正)。
请注意,淡黄色和淡灰色的14个字符按照GB18030还是应该映射到PUA码位。这14个字符与非PUA码位的映射关系只是网友找出来的,不是标准规定的。如果按照GBK编码,这80个字符应该全部映射到PUA码位。GB18030将其中66个字符映射到了非PUA码位。不过在Windows中,简体中文区域的默认代码页还是GBK,不是GB18030。
- CJK兼容汉字区挑选出来的21个汉字。见下表: 汉字GBK编码Unicode编码郎FD9CF92C凉FD9DF979秊FD9EF995裏FD9FF9E7隣FDA0F9F1兀FE40FA0C嗀FE41FA0D﨎FE42FA0E﨏FE43FA0F﨑FE44FA11﨓FE45FA13﨔FE46FA14礼FE47FA18﨟FE48FA1F蘒FE49FA20﨡FE4AFA21﨣FE4BFA23﨤FE4CFA24﨧FE4DFA27﨨FE4EFA28﨩FE4FFA29
4 GB18030-2000
4.1 字汇
GB18030-2000的字汇部分是这样写的:
本标准收录的字符分别以单字节、双字节和四字节编码。5.1 单字节部分
本标准中,单字节的部分收录了GB 11383的0x00到0x7F全部128个字符及单字节编码的欧元符号。
5.2 双字节部分
本标准中,双字节的部分收录内容如下:
GB 13000.1的全部CJK统一汉字字符。
GB 13000.1的CJK兼容区挑选出来的21个汉字。
GB 13000.1中收录而GB 2312未收录的我国台湾地区使用的图形字符139个。
GB 13000.1收录的其它字符31个。
GB 2312中的非汉字符号。
GB 12345 的竖排标点符号19个。
GB 2312未收录的10个小写罗马数字。
GB 2312未收录的带音调的汉语拼音字母5个以及ɑ 和ɡ 。
汉字数字“〇”。
表意文字描述符13个。
增补汉字和部首/构件80个。
双字节编码的欧元符号。
5.3 四字节部分
本标准的四字节的部分,收录了上述双字节字符之外的,包括CJK统一汉字扩充A在内的GB 13000.1 中的全部字符。
4.2 汉字
如下表所示,GB18030-2000收录了27533个汉字:
类别 码位范围 码位数 字符数 字符类型 双字节部分 第一字节 0xB0-0xF7第二字节 0xA1-0xFE 6768 6763 汉字 第一字节0x81-0xA0
第二字节0x40-0xFE 6080 6080 汉字 第一字节0xAA-0xFE
第二字节0x40-0xA0 8160 8160 汉字 四字节部分 第一字节0x81-0x82
第二字节0x30-0x39
第三字节0x81-0xFE
第四字节0x30-0x39 6530 6530 CJK统一汉字扩充A
27533就是6763+6080+8160+6530。双字节部分的6763+6080+8160=21003个汉字就是GBK的21003个汉字。
在Unicode中,CJK统一汉字扩充A有6582个汉字,为什么这里只有6530个汉字?
这是因为在GBK时代,双字节部分已经收录过CJK统一汉字扩充A的52个汉字,所以还余6530个汉字。
5 GB18030-2005
5.1 字汇
GB18030-2005的字汇部分是这样写的:
本标准收录的字符分别以单字节、双字节或四字节编码。5.1 单字节部分
本标准中,单字节的部分收录了GB/T 11383-1989的0x00到0x7F全部128个字符。
5.2 双字节部分
本标准中,双字节的部分收录内容如下:
GB 13000.1-1993的全部CJK统一汉字字符。见附录A。
GB 13000.1-1993的CJK兼容区挑选出来的21个汉字。见附录A。
GB 13000.1-1993中收录而GB 2312未收录的我国台湾地区使用的图形字符139个。见附录A。
GB 13000.1-1993收录的其它字符31个。见附录A。
GB 2312中的非汉字符号。见附录A。
GB 12345 的竖排标点符号19个。见附录A。
GB 2312未收录的10个小写罗马数字。见附录A。
GB 2312未收录的带音调的汉语拼音字母5个以及ɑ 和ɡ 。见附录A。
汉字数字“〇”。 见附录A。
表意文字描述符13个。见附录A和附录B。
对GB 13000.1-1993增补的汉字和部首/构件80个。见附录A和附录C。
双字节编码的欧元符号。见附录A。
5.3 四字节部分
本标准的四字节的部分,收录了上述双字节字符之外的,GB 13000的CJK统一汉字扩充A、CJK统一汉字扩充B和已经在GB13000中编码的我国少数民族文字的字符。见附录D。
GB18030-2005最主要的变化是增加了CJK统一汉字扩充B。它还去掉了单字节编码的欧元符号(0x80)。
5.2 汉字
如下表所示,GB18030-2005收录了70244个汉字:
类别 码位范围 码位数 字符数 字符类型 双字节部分 第一字节 0xB0-0xF7第二字节 0xA1-0xFE 6768 6763 汉字 第一字节0x81-0xA0
第二字节0x40-0xFE 6080 6080 汉字 第一字节0xAA-0xFE
第二字节0x40-0xA0 8160 8160 汉字 四字节部分 第一字节0x81-0x82
第二字节0x30-0x39
第三字节0x81-0xFE
第四字节0x30-0x39 6530 6530 CJK统一汉字扩充A 第一字节0x95-0x98
第二字节0x30-0x39
第三字节0x81-0xFE
第四字节0x30-0x39 42711 42711 CJK统一汉字扩充B
70244就是6763+6080+8160+6530+42711。
6 结束语
GB2312有6763个汉字,GBK有21003个汉字,GB18030-2000有27533个汉字,GB18030-2005有70244个汉字。
Unicode 5.0中,如果不算兼容区,目前有70217个汉字。让我们比较一下Unicode的70217汉字和GB18030-2005中的70244汉字:
GB18030-2005Unicode 5.0对应的Unicode编码CJK统一汉字的20902汉字CJK统一汉字的20902汉字0x4E00-0x9FA5CJK统一汉字扩充A的6582汉字CJK统一汉字扩充A的6582汉字0x3400-0x4DB5CJK统一汉字扩充B的42711汉字CJK统一汉字扩充B的42711汉字0x20000-0x2A6D6CJK部首补充区的14个部首未计入2E81, 2E84, 2E88, 2E8B, 2E8C, 2E97, 2EA7, 2EAA, 2EAE, 2EB3, 2EB6, 2EB7, 2EBB, 2ECACJK兼容汉字区的21个汉字未计入F92C, F979, F995, F9E7, F9F1, FA0C, FA0D, FA0E, FA0F, FA11, FA13, FA14, FA18, FA1F, FA20, FA21, FA23, FA24, FA27, FA28, FA29因为GB18030映射了Unicode的所有码位,所以CJK统一汉字区新增的0x9FA6-0x9FB3这14个字符在GB18030中都有对应的码位。不过GB18030没有明确收录这些字符。
附录1 GB18030的汉字编码表
我整理了GB18030的汉字编码表,需要的朋友可以下载。以下是其中的简要说明:
简要说明将表1(21003)和表2(6530)合起来就是GB18030-2000要求的27533个汉字
将表1(21003)、表2(6530)和表3(42711)合起来就是GB18030-2005要求的70244个汉字
Unicode的扩充A本来有6582个汉字,因为GB18030的双字节区已经收录过Unicode扩充A的52个汉字,所以GB18030四字节区扩充A只有6530个汉字。表4列出了这52个汉字。
GBK增补的80个字符本来是放在PUA区的。后来又被Unicode收录。所以既可以用PUA区的编码表示,也可以用非PUA编码表示。如下表所示。
http://www.diybl.com/course/3_program/java/javajs/2007116/84795.html
- Unicode、GB2312、GBK和GB18030中的汉字
- Unicode、GB2312、GBK和GB18030中的汉字
- Unicode、GB2312、GBK和GB18030中的汉字
- Unicode、GB2312、GBK和GB18030中的汉字
- Unicode、GB2312、GBK和GB18030中的汉字
- Unicode、GB2312、GBK和GB18030中的汉字
- Unicode、GB2312、GBK和GB18030中的汉字
- Unicode、GB2312、GBK和GB18030中的汉字[转]
- [转帖]Unicode、GB2312、GBK和GB18030中的汉字
- Unicode、GB2312、GBK和GB18030中的汉字关联
- unicode、utf-8、gb18030、gb2312、gbk(转)
- ANSI、GBK、GB2312、UTF-8、GB18030和 UNICODE
- ANSI、GBK、GB2312、UTF-8、GB18030和 UNICODE
- ANSI、GBK、GB2312、UTF-8、GB18030和、UNICODE编码解读
- ANSI、GBK、GB2312、UTF-8、GB18030和 UNICODE
- ANSI、GBK、GB2312、UTF-8、GB18030和 UNICODE
- unicode utf-8 gb18030 gb2312 gbk各种编码对比 [转]
- 中文字符集编码Unicode ,gb2312 , cp936 ,GBK,GB18030(转)
- 李开复创立天使投资 柳传志郭台铭等投资八亿元
- HDU 1234 开门人和关门人
- while(cin>>str)结束的问题
- 项目总结
- RandomAccessFile类的应用
- Unicode、GB2312、GBK和GB18030中的汉字[转]
- asp.net的异常处理机制
- 李开复:新公司今日起开始招聘
- 2008年度世界顶级杀毒软件排名榜
- 开始攻坚——算法
- 《货币战争》:下一场世界大战
- table合并
- Java多线程初学者指南(1):线程简介
- 第十一章实验任务


